Articolele lui
 Candale Silviu (silviu)
Candale Silviu (silviu)
Limbajul pseudocod
Introducere
Pseudocod este un limbaj prin care sunt descriși pașii dintr-un algoritm. Limbajul pseudocod conține structurile specifice unui limbaj de programare obișnuit (precum Pascal, C/C++, Basic, etc) dar este destinat a fi citit de către oameni, nu de către calculatoare.
De obicei sunt omise detaliile vitale într-un limbaj de programare, precum declararea variabilelor sau secvențe specifice limbajului. Algoritmii pseudocod pot conține secvențe descrise în limbaj natural, precum și expresii matematice compacte, care lipsesc din limbajele de programare reale.
Conceptele care intervin in algoritmii pseudocod sunt similare cu cele din limbajele de programare:
- instrucțiuni
- variabile
- constante
- operații
- expresii
Există mai multe variante ale limbajului pseudocod. Acest articol se referă la varianta folosită în subiectele pentru examenul de bacalaureat la informatică. Limba folosită este limba română.
Variabile și constante
În pseudocod variabilele nu se declară, iar numele lor respectă regula uzuală a identificatorilor – litere, cifre, caracterul de subliniere și să nu înceapă cu cifră.
Constantele care apar de regulă în algoritmii pseudocod sunt constante literale (valori numerice, întregi sau reale, caractere – delimitate prin apostrof ‘, șiruri de caractere – delimitate prin apostroafe (‘) sau ghilimele (“). De asemenea, pot să apară constante matematice, de exemplu \( \pi \).
Operații
Sunt prezente toate operațiile aritmetice uzuale:
- adunarea a două numere:
a+b. În funcție de context, rezultatul este întreg sau real. - scăderea a două numere:
a-b. În funcție de context, rezultatul este întreg sau real. - înmulțirea a două numere:
a*b. În funcție de context, rezultatul este întreg sau real. - împărțirea a două numere:
a/b. Rezultatul se consideră real. Dacă se dorește determinarea câtului împărțirii a două numere naturale, se va folosi partea întreagă a rezultatului împărțirii:[a/b]. - restul împărțirii a două numere întregi:
a%b. Se aplică numai pentru date întregi, iar rezultatul este număr întreg.
Notă: Unele variante pseudocod propun operațiile DIV și MOD pentru determinarea câtului și restului împărțirii a două numere întregi. De asemenea, pot să apară operații de ridicare la putere, în forma \( a ^ n\), sau de extragere a rădăcinii pătrate – \(\sqrt{x}\).
Operațiile relaționale sunt:
=– egalitatea≠– neegalitatea<– mai mic≤– mai mic sau egal>– mai mare≥– mai mare sau egal
Operanzii sunt de regulă numere, iar rezultatul este valoare de adevăr (adevărat sau fals).
Operațiile logice sunt NOT, ȘI, SAU – cu semnificațiile cunoscute. O descriere a operațiilor logice poate fi găsită aici: www.pbinfo.ro/articole/21315/operatii-logice.
Instrucțiuni
Instrucțiunile sunt componentele algoritmului care au efect, atunci când se execută. Ele modifică valorile unor variabile, citesc sau afișează date, repetă anumite acțiuni, etc.
De regulă fiecare instrucțiune se scrie pe o linie (sau mai multe în cazul celor complexe), dar există situații când, pentru a economisi spațiu, două sau mai multe instrucțiuni simple se scriu pe același rând, separate prin ;.
Orice algoritm poate fi reprezentat prin intermediul a trei tipuri de structuri:
- structura liniară
- structura alternativă
- structura repetitivă
- structura repetitivă cu număr necunoscut de pași
- structura repetitivă cu număr necunoscut de pași și test inițial
- structura repetitivă cu număr necunoscut de pași și test final
- structura repetitivă cu număr cunoscut de pași
- structura repetitivă cu număr necunoscut de pași
Citirea
Pentru citirea datelor se folosește instrucțiunea citește <listă variabile>, unde <listă variabile> reprezintă un șir de variabile separate prin caracterul ,. Se preiau valori succesive de la tastatură și se memorează în variabilele din listă.
Exemplu
citeste a , b , c
Citirea datelor este frecvent însoțită de precizări privind datele citite (tip, valori posibile. etc.).
Afișarea
Pentru afișarea datelor se folosește instrucțiunea scrie <listă expresii>, unde <listă expresii> reprezintă un șir de expresii separate prin caracterul ,. Se evaluează în ordine expresiile din listă și se afisează pe ecran rezultatele lor.
Exemplu
scrie 'a + b = ' , a + b
Dacă a = 3 și b = 4 se va afișa:
a + b = 7
Atribuirea
Pentru atribuire se folosește instructiunea <variabilă> ← <expresie>. Se evaluază expresia, iar valoarea obținută se memorează in variabilă.
Exemple
a ← 0 S ← a + b i ← i + 1
Structura alternativă
În pseudocod există instrucțiunea daca, cu următoarea sintaxă:
┌ daca <conditie> atunci │ <instructiuni1> │ altfel │ <instructiuni2> └■
sau
┌ daca <conditie> atunci │ <instructiuni1> └■
Modul de execuție este următorul:
- se evaluează
<conditie> - dacă este adevărată, se executa grupul de instrucțiuni
<instructiuni1>, apoi se trece la următoarea instrucțiune - dacă este falsă, se executa grupul de instrucțiuni
<instructiuni2>, dacă există secțiuneaaltfel, apoi se trece la următoarea instrucțiune.
Structuri repetive
Structura repetitivă cu număr cunoscut de pași
Instrucțiunea PENTRU
Sintaxă
┌ pentru <variabila> ← <expresie initiala>, <expresie finala> , <pas> executa │ <instructiuni> └■
unde expresie initiala, expresie finala și pas sunt expresii cu rezultat (de regulă) întreg, iar pas poate fi 1 sau -1 și poate lipsi, caz în care se consideră că este 1.
variabila primește pe rând valori crescătoare (dacă pas = 1) sau descrescătoare (dacă pas = -1) începând de la expresie initiala până la expresie finala, și pentru fiecare valoare se execută secvența instructiuni.
Dacă pas = 1 și expresie initiala > expresie finala>, secvența instructiuni nu se va executa deloc. La fel se întâmplă când <pas = -1 și expresie initiala < expresie finala. În caz contrar numărul de pași este expresie initială - expresie finala + 1, dacă <pas = 1, respectiv expresie finală - expresie initiala + 1, dacă pas=-1.
Exemplu
Determinarea sumei și produsului primelor n numere naturale:
S ← 0; P ← 1 ┌ pentru i←1,n executa │ S ← S + i │ P ← P * i └■ scrie S, ' ' , P
Structura repetitivă cu număr necunoscut de pasi și test inițial
Instrucțiunea CÂT TIMP … EXECUTĂ
Sintaxă
┌ cat timp <conditie> executa │ <instructiuni> └■
Mod de execuție
- se evalueză condiția
- dacă este adevărată se executa instrucțiunile și se revine la pasul 1
- dacă este falsă se trece la următoarea instrucțiune din algoritm
Important: Dacă condiția este de la început falsă, instrucțiunile nu se vor executa deloc!
Exemplu
Determinarea sumei cifrelor unui număr natural:
citeste n S ← 0 ┌ cat timp n ≠ 0 executa │ S ← S + n % 10 │ n ← [n/10] └■ scrie S
Structura repetitivă cu număr necunoscut de pasi și test final
Instrucțiunea EXECUTA … CAT TIMP
Sintaxă
┌ executa │ <instructiuni> └ cat timp <conditie>
Mod de execuție
- se executa instrucțiunile
- se evalueză condiția
- dacă este adevărată se revine la pasul 1
- dacă este falsă se trece la următoarea instrucțiune din algoritm
Important: Chiar dacă condiția este de la început falsă, instrucțiunile s-au executat deja o dată!
Exemplu
Numărul cifrelor unui număr natural:
citeste n cnt ← 0 ┌ executa │ cnt ← cnt + 1 │ n ← [n/10] └ cat timp n ≠ 0 scrie cnt
Instrucțiunea REPETA … PANA CAND
Sintaxă
┌ repeta │ <instructiuni> └ pana cand <conditie>
Mod de execuție
- se executa instrucțiunile
- se evalueză condiția
- dacă este falsă se revine la pasul 1
- dacă este adevărată se trece la următoarea instrucțiune din algoritm
Important: Chiar dacă condiția este de la început adevărată, instrucțiunile s-au executat deja o dată!
Exemplu
Numărul cifrelor unui număr natural:
citeste n cnt ← 0 ┌ repeta │ cnt ← cnt + 1 │ n ← [n/10] └ pana cand n = 0 scrie cnt
Echivalența structurilor repetitive
Numeroase exerciții propun un algoritm și se cere scrierea unui algoritm echivalent care să folosească o structură repetitivă de alt tip. Doi algoritmi sunt echivalenți dacă pentru orice set de date de intrare (conforme cu restricțiile problemei) ei obțin aceleași rezultate.
Această secțiune descrie câteva reguli de transformare a structurilor repetitive din algoritmii pseudocod.
PENTRU → CÂTTIMP
┌ pentru i←a,b executa │ <instructiuni> └■
i ← a ┌ cattimp i ≤ b executa │ <instructiuni> │ i ← i + 1 └■
PENTRU → EXECUTĂ … CÂTTIMP
┌ pentru i←a,b executa │ <instructiuni> └■
i ← a ┌ daca i ≤ b atunci │┌ executa ││ <instructiuni> ││ i ← i + 1 │└ cattimp i ≤ b └■
PENTRU → REPETĂ … PÂNÂCÂND
┌ pentru i←a,b executa │ <instructiuni> └■
i ← a ┌ daca i ≤ b atunci │┌ repeta ││ <instructiuni> ││ i ← i + 1 │└ panacand i > b └■
CÂTTIMP → EXECUTĂ … CÂTTIMP
┌ cattimp <conditie> executa │ <instructiuni> └■
┌ daca <conditie> atunci │┌ executa ││ <instructiuni> │└ cattimp <conditie> └■
CÂTTIMP → REPETĂ … PÂNÂCÂND
┌ cattimp <conditie> executa │ <instructiuni> └■
┌ daca <conditie> atunci │┌ repeta ││ <instructiuni> │└ panacand NOT <conditie> └■
REPETĂ … PÂNĂCÂND → CÂTTIMP
┌ repeta │ <instructiuni> └ panacand <conditie>
<instructiuni> ┌ cattimp NOT <conditie> executa │ <instructiuni> └■
 Candale Silviu (silviu)
Candale Silviu (silviu) C++ STL priority queue
Coada de priorități este o structură de date de tip coadă, în care se fac operații de inserare și eliminare, dar ordinea nu este cea a cozii obișnuite. Fiecare element are asociată o anumită prioritate (de exemplu chiar valoarea sa), iar elementul de la începutul cozii este cel cu prioritate maximă, el fiind și cel care va fi eliminat din coadă în cazul operației de eliminare a unui element.
Cozile de priorități pot fi implementate sub formă de heap-uri, iar STL contine containerul adaptor priority_queue. Tehnic priority_queue implementează în mod implicit un max-heap.
Operația de determinare a elementului maxim are complexitate constantă, in timp ce operațiile de inserare și eliminare au complexități logaritmice în raport cu numărul de elemente.
Declarare
Clasa priority_queue este o clasă template definită în headerul queue:
#include <queue>
O putem declara ca în exemplul următor:
priority_queue<int> H;
Implicit, priority_queue-ul este un max-heap (elementul maxim are prioritate maximă) și se implementează pe baza operației < (less<int>)). Dacă dorim să gestionăm un min-heap (elementul minim să aibă prioritate maximă) vom folosi următoarea declarație:
priority_queue<int , vector<int> , greater<int> > H;
Similar, putem crea cozi de priorităti cu elemente de tipuri oarecare T. Condiția este să fie definit pentru tipul T operatorul < (functorul less<T>), sau să construim un functor de comparare.
struct fcmp
{ bool operator()(const T & a , const T & b)
{
//returneaza true daca si numai daca a este strict in fata lui b in ordinea dorita
}
};
priority_queue<T , vector<T> , fcmp > H;
Operații de bază
Fie următoarea coadă de priorități:
priority_queue<T> H; T v;
Adăugarea unui element
priority_queue<T> H; T v; H.push(v);
Se adaugă în coadă elementul v. Elementele se reorganizează pentru se păstra proprietate de heap (elementul maxim să fie la început).
Ștergerea unui element
priority_queue<T> H; H.pop();
Se șterge din coadă elementul de la început. Elementele se reorganizează pentru se păstra proprietate de heap.
Determinarea elementului din vârf
priority_queue<T> H; T v; v = H.top();
Returnează o referință la elementul de la începutul cozii. Elementul se va elimina numai la apelul metodei pop().
Stabilirea faptului că este coada vidă
priority_queue<T> H; H.empty()
Returnează true dacă H este o coadă vidă și false în caz contrar.
Dimeniunea cozii
priority_queue<T> H; H.size()
Returnează numărul de elemente din coada de priorități H.
Atribuirea
Conținutul unei cozi de priorități poate fi copiat în altă coadă de același tip prin operatorul de atribuire =.
priority_queue<T> A , B; ... A = B;
Exemple
Considerăm următoarea problemă;
Se dau coordonatele întregi ale unor puncte în plan. Să se afișeze coordonatele în ordinea crescătoare a absciselor, iar la abscise egale în ordinea crescătoare a ordonatelor.
Următoarele soluții se bazează pe o coadă de priorități în care adăugăm toate punctele, apoi le extragem și le afișăm.
Soluția 1
Pentru memorarea unui punct folosim o structură (clasă) definită în mod adecvat. Pentru stabilirea ordinii între puncte folosim un functor, iar pentru afișarea coordonatelor folosim o funcție prietenă.
#include <iostream>
#include <queue>
using namespace std;
struct Punct{
int x , y;
Punct(int a = 0, int b = 0){ x = a , y = b;}
friend ostream & operator<<(ostream & os , Punct A)
{
os << "(" << A.x << "," << A.y << ")";
return os;
}
};
struct fcmp
{ bool operator()(const Punct & a , const Punct & b)
{
if(a.x > b.x)
return true;
if(a.x < b.x)
return false;
if(a.y > b.y)
return true;
return false;
}
};
int main()
{
priority_queue<Punct, vector<Punct>, fcmp> H;
H.push(Punct(6,1));
H.push(Punct(2,7));
H.push(Punct(2,4));
H.push(Punct(4,10));
H.push(Punct(7,4));
while(! H.empty())
cout << H.top() << '\n', H.pop();
return 0;
}
Soluția 2
În acestă soluție nu folosim un functor pentru comparare, ci supraîncărcăm operatorul < printr-o functie prietenă.
#include <iostream>
#include <queue>
using namespace std;
struct Punct{
int x , y;
Punct(int a = 0, int b = 0){ x = a , y = b;}
friend ostream & operator<<(ostream & os , const Punct & A)
{
os << "(" << A.x << "," << A.y << ")";
return os;
}
friend bool operator<(const Punct & A , const Punct & B)
{
if(A.x > B.x)
return true;
if(A.x < B.x)
return false;
if(A.y > B.y)
return true;
return false;
}
};
int main()
{
priority_queue<Punct> H;
H.push(Punct(6,1));
H.push(Punct(2,7));
H.push(Punct(2,4));
H.push(Punct(4,10));
H.push(Punct(7,4));
while(! H.empty())
cout << H.top() << '\n', H.pop();
return 0;
}
Soluția 3
Pentru memorare punctelor folosim clasa pair. Clasa pair are definit operatorul mai mic, acesta verificând ordinea lexicografică pentru membrii first și second.
#include <iostream>
#include <queue>
using namespace std;
int main()
{
priority_queue <
pair<int,int>,
vector<pair<int,int>>,
greater<pair<int,int>>
> H;
H.push({6,1});
H.push({2,7});
H.push({2,4});
H.push({4,10});
H.push({7,4});
while(! H.empty())
cout << "(" << H.top().first << "," << H.top().second << ")" << '\n', H.pop();
return 0;
}
Declararea de mai sus trebuie făcută în acest mod, pentru a obține un min-heap. Dacă am fi folosit declararea:
priority_queue <pair<int,int> > H;
s-ar fi implementat (pe baza functorului less<pair<int,int>>) un max-heap, în care elementele de prioritate maximă ar fi fost acela care au câmpul first mai mare.
C++ STL bitset
bitset este un container special din STL care permite lucrul cu șiruri de biți. Aceștia sunt memorați eficient, pentru un bit din șir folosindu-se un bit în memorie. Astfel, spațiul de memorie ocupat de un bitset cu M biți este mai mic decât un tablou bool V[M]; sau un vector cu elemente de tip bool, dar numărul de biți M din bitset trebuie să fie cunoscut în momentul compilării, deci trebuie să fie o contantă.
Pot fi folosiți de exemplu pe post de vectori caracteristici, dar suportă și operațiile pe biți cunoscute pentru tipurile întregi.
Declararea
Pentru a folosi containerul bitset trebuie inclus headerul bitset:
#include <bitset>
Declararea se face astfel:
const int M = 16; bitset<M> B = 30;
Operații elementare
Afișarea
const int M = 16; bitset<M> B = 30; cout << B << endl;
Observații:
Meste constantă. Lipsa modificatoruluiconstduce la o eroare de compilare.- Când afișăm bitsetul, se afișează toți cei
Mbiți.
Indexarea
Biții din bitset sunt indexați de la 0 și pot fi accesați prin operatorul []. Bitul cel mai nesemnificativ (cel mai din dreapta) este B[0], iar bitul cel mai semnificativ este B[M-1], unde M este dimensiunea bitsetului.
const int M = 16; bitset<M> B = 30; // 0000000000011110 B[6] = 1; cout << B; // 0000000001011110
Compararea
Două containere bitset de aceeași dimensiune pot fi comparate cu operatorii == și !=.
Notă: operația != este eliminată în C++20.
Atribuirea
Putem să-i atribuim unui bitset valoarea unui întreg sau valoarea unui alt bitset. Prin atribuirea unui întreg, biții din bitsetul B devin identici cu biții din reprezentarea în memorie a valorii întregi care se atribuie:
const int M = 16; bitset<M> B, A; B = -30; cout << B << endl; // 1111111111100010 B = 5; cout << B << endl; // 0000000000000101 A = B; cout << A << endl; // 0000000000000101
Manipularea biților
Numărarea bitilor setați, numărul total de biți
Pentru a afle câți biți din bitset sunt setați (au valoarea 1), folosim metoda count(). Pentru a determina numărul total de biți, folosim metoda size(). Numărul biților nesetați (cu valoarea 0), facem diferența celor două.
const int M = 16; bitset<M> B = 63; cout << B.count() << endl; // 6 cout << B.size() << endl; // 16
Determinarea valorii unui bit
Se face cu metoda test(k), unde k reprezintă numărul de ordine al bitului dorit (de la dreapta spre stânga, incepând de la 0), iar rezultatul este 1 sau 0.
const int M = 16; bitset<M> B = 63; cout << B << endl; // 0000000000111111 cout << B.test(5) << endl; // 1 cout << B.test(6) << endl; // 0
Set, reset, flip
Bitsetul oferă metode pentru:
- setarea unui bit precizat:
B.set(k)dă valoarea1pentruB[k]B.set(k , r)dă valoarearpentruB[k]B.set()dă valoarea1pentru toți biții dinB
- resetarea unui bit precizat:
B.reset(k)dă valoarea0pentruB[k]B.reset()dă valoarea0pentru toți biții dinB
- schimbarea valoare biților (din
1devine0, iar din0devine1):B.flip(k)schimbă valoarea luiB[k]B.flip()schimbă valorile pentru toți biții dinB
bitset<M> B; B = 63; cout << B << endl; // 0000000000111111 //bitii se numeroteaza de la dreapta, incepand cu 0 B.reset(5); B.set(10); B.set(9 , 1); B.set(3 , 0); B.flip(2); cout << B << endl; // 0000011000010011 B.flip(); cout << B << endl; // 1111100111101100 B.set(); cout << B << endl; // 1111111111111111 B.reset(); cout << B << endl; // 0000000000000000
Operații pe biți
Operatii logice pe biți
Clasa bitset suportă operatorii logici pe biți (~, &, |, ^).
bitset<M> B, A; B = -60; A = 5; cout << "A = " << A << endl; // 0000000000000101 cout << "B = " << B << endl; // 1111111111000100 cout << "~B = " << ~B << endl; // 0000000000111011 cout << "A & B = " << (A & B) << endl; // 0000000000000100 cout << "A | B = " << (A | B) << endl; // 1111111111000101 cout << "A ^ B = " << (A ^ B) << endl; // 1111111111000001
Operatorii de deplasare
Clasa bitset suportă operatorii de deplasare a biților (<<, >>).
bitset<M> B; int n = 4; B = 7; cout << "B = " << B << endl; // 0000000000000111 cout << "B << n = " << (B << n) << endl; // 0000000001110000
Atribuiri
Clasa bitset suportă atriburile scurte: &=, |=, ^=, precum și <<=, >>=.
Fie A , B două containere bitset de aceași dimensiune și n un întreg. Atunci:
A &= Beste echivalent cuA = A & B;A |= Beste echivalent cuA = A | B;A ^= Beste echivalent cuA = A ^ B;A <<= neste echivalent cuA = A << n;A >>= neste echivalent cuA = A >> n;
Conversii
Bitset-ul poate fi convertit la
- string –
to_stringB.to_string()– returnează un string conținând reprezentarea binară a luiB, formată formată din caractere0și1;B.to_string(c0)– returnează un string conținând reprezentarea binară a luiB, caracterele0fiind înlocuite cu caracterulc0;B.to_string(c0 , c1)– returnează un string conținând reprezentarea binară a luiB, caracterele0și1fiind înlocuite cu caracterulc0, respectivc1;
- întreg fără semn-
to_ulong(),to_uulong()B.to_ulong()– retunează un întreg fără semn pe 32 de biți (unsingned int,unsigned long) cu reprezentarea binară echivalentă cu configurația bitsetuluiB;B.to_uulong()– retunează un întreg fără semn pe 64 de biți (unsigned long long) cu reprezentarea binară echivalentă cu configurația bitsetuluiB;- dacă valoarea întreagă corespunzătoare bitsetului nu poate fi reprezentată pe 32, respectiv 64 de biți, se va ridica o excepție de tip
overflow_error.
C++ vector - scurt tutorial
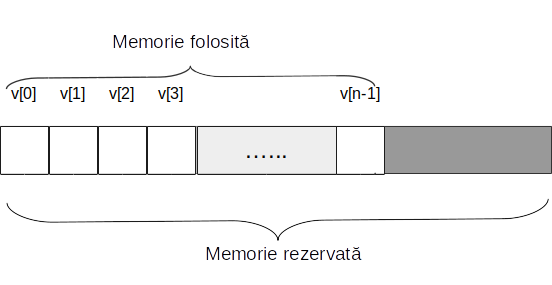
Containerul C++ vector este, probabil, cel mai folosit container STL. Vectorii sunt tablouri dinamice cu elemente omogene care au proprietatea de a se redimensiona automat când se adaugă sau se șterge un element, gestionarea memoriei fiind realizată automat de către container.
Vectorii sunt stocați într-o zonă contiguă de memorie și pot fi traversați cu ajutorul iteratorilor. Elementele se adaugă, de regulă la sfârșit. Operația de adăugare ia, de regulă, timp constant, cu excepția cazului când spatiul de memorie alocat trebuie redimensionat (mărit). Ștergerea unui element ia întotdeauna timp constant. Inserarea și ștergerea la începutul sau în interiorul vectorului iau timp liniar.
Declararea unui vector
Trebuie inclus header-ul vector:
#include <vector>;
Declararea se face astfel:
vector<T> V;
unde T este un tip de date. Acesta va fi tipul elementelor vectorului. Vectorul declarat mai sus este vid – are 0 elemente.
Alternativ, putem declara vectorul astfel:
vector<T> V(n);
n este un întreg. Se va crea un crea un vector V cu n elemente. Valorile acestora sunt valorile implicite pentru datele de tip T. Pentru tipurile numerice, valoarea elementelor este 0.
vector<T> V(n, vT);
n este un întreg, iar vT este o dată de tip T. Se va crea un crea un vector V cu n elemente. Valorile acestora sunt copii ale lui vT.
De exemplu:
vector<int> A; // se crează un vector A cu zero elemente cin >> n; vector<int> B(n); // se crează un vector B cu n elemente, egale cu 0 cin >> x; vector<int> C(n , x); // se crează un vector B cu n elemente, egale cu x
Atribuirea
Spre deosebire de tablourile standard C, vectorilor li se pot atribui valori în orice moment. Exemplu:
vector<int> A , B = {2 , 4, 6 , 8};
A = B;
A = {1 , 2 , 3 , 4 , 5};
Dimensiunea și capacitatea
Numărul de elemente din vector poate fi determinat cu funcția size():
vector<int> A = {2 , 4 , 6 , 8};
cout << A.size(); // 4
De regulă, memoria alocată pentru un vector este mai mare decât memoria folosită. Acest lucru se întâmplă pentru a se evita realocarea memoriei (operație costisitoare, care presupune copierea tuturor elementelor) de fiecare dată când se adaugă elemente.
Funcția capacity() returnează numărul de elemnte pe care le poate avea vectorul la momentul curent, fără a se realoca memoria. Are loc relația capacity() >= size(), iar numărul de elemente care pot fi adăugate fără realocare este capacity() - size().
Redimensionarea
Funcția resize() permite redimensionarea unui vector și are următoarele forme:
V.resize(n);(1)V.resize(n , x);(2)
Vectorul V se redimensionează încât să aibă n elemente:
- dacă
n < V.size(), în vector vor rămâne primelenelemente, celelalte vor fi șterse. - dacă
n > V.size(), în vector se vor adăugan - V.size()elemente egale cux, în cazul (2) sau egale cu valoarea implicită pentru tipul elementelor din vector, în cazul (1). Această valoare este0pentru tipurile numerice.
Adăugarea unui element
Adăugarea unui nou element în vector se face la sfârșit, cu funcția push_back():
vector<int> A; for(int i = 1 ; i <= 5 ; i ++) A.push_back(2 * i); cout << A.size();
Accesarea unui element
Elementele vectorilor pot fi accesate prin intermediul indicilor, cu operatorul []. Acesta nu verifică existență elementului cu un anumit indice, iar dacă acesta nu există, comportamentul programului este impredictibil.
vector<int> A; for(int i = 1 ; i <= 5 ; i ++) A.push_back(2 * i); for(int i = 0 ; i < A.size() ; i ++) cout << A[i] << ' '; // 0 2 4 6 8
De asemenea, este posibilă accesarea elementelor prin intermediul funcției at(). Aceasta returnează o referință la elementul de la poziția dată, iar dacă acesta nu există ridică o excepție care poate fi capturată prin mecanismul try … catch.
vector<int> A = {2 , 4 , 6 , 8 , 10};
A.at(1) = 20; //A = {2 , 20 , 6 , 8 , 10}
for(auto x : A)
cout << x << " ";
Primul și ultimul element poate fi accesat prin intemediul funcțiilor front() și back(). Ele returnează referințe la primul, respectiv ultimul element al vectorului. Comportamentul este impredictibil dacă vectorul este vid.
vector<int> A = {2 , 4 , 6 , 8 , 10};
A.at(1) = 20; //A = {2 , 20 , 6 , 8 , 10}
A.front() = 7; //A = {7 , 20 , 6 , 8 , 10}
A.back() = 5; //A = {7 , 20 , 6 , 8 , 5}
for(auto x : A)
cout << x << " ";
Iteratori
Iteratorii sunt similari cu pointerii. Cu ajutorul lor putem identifica adresa elementelor din vector. Iteratorii pot fi dereferențiați (obtinând referințe la elemente), pot fi incrementați/decrementați și pot fi adunați cu scalari.
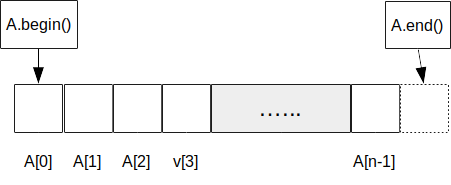
Vectorii oferă prin intermediul funcției begin() un iterator la primul element al funcției, iar prin end() un iterator la elementul de după ultimul element al vectorului.
vector<int> A = {2 , 4 , 6 , 8 , 10};
vector<int>::iterator I;
for(I = A.begin() ; I < A.end() ; I ++)
cout << *I << " "; // 2 4 6 8 10
Observații:
- tipul variabilei iterator trebuie să fie în concordanță cu tipul elementelor vectorului;
- pentru a lucra cu elementul pentru care cunoaștem iteratorul, acesta trebuie să fie dereferențiat:
*I; - rezultatul funcției
A.end()este un iterator, dar acestuia nu-i corespunde un element al vectorului. Valoarea sa este adresa de după ultimul element al vectorului.
Clasa vector conține și funcțiile rbegin() și rend(), care returnează iteratori de tip reverse iterator, care permit parcurgerea vectorului în ordien inversă:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(vector<int>::reverse_iterator I = A.rbegin() ; I < A.rend() ; I ++)
cout << *I << " ";
Acești iteratori fac parte din categoria iteratorilor cu acces aleatoriu. Este cea mai puternică categorie de iteratori (cu cele mai multe operații definite). Aceste operații sunt:
| Expresie | Rezultat, efect |
|---|---|
*I |
Dereferențiere |
I->camp |
Acces la câmpurile structurii/membrii clasei memorate în elementele vectorului |
++I |
Preincrementare. Rezultatul este poziția următoare |
I++ |
Postincrementare. Rezultatul este poziția inițială |
--I |
Predecrementare. Rezultatul este poziția anterioară |
I-- |
Postdecrementare. Rezultatul este poziția inițială |
I == J |
Egalitate între doi iteratori |
I != J |
Neegalitate între doi iteratori |
<, >, <=, >= |
Operatori relaționali. Operanzii sunt iteratorii. Rezultatul este conform cu poziția în vector a elementelor adresate de cei doi iteratori |
I[k] |
Elementul de pe poziția k, începând de la I |
I += k |
k pași înainte |
I -= k |
k pași înapoi |
I + k |
iterator spre al k-lea element după cel curent |
I + k |
iterator spre al k-lea element înaintea celui curent |
I - J |
distanța în vector între iteratorii I și J |
Parcurgerea unui vector
O primă modalitate de parcurgere este folosind indicii, similar cu parcurgerea tablourilor standard C. Pentru determinarea numărului de elemnte există functia size():
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(int i = 0 ; i < A.size(); i ++)
cout << A[i] << " ";
De asemenea, putem folosi iteratorii:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(vector<int>::iterator I = A.begin() ; I < A.end() ; I ++)
cout << *I << " ";
Pentru ușurință, putem folosi specificatorul de tip auto pentru a stabili tipul iteratorului:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(auto I = A.begin() ; I < A.end() ; I ++)
cout << *I << " ";
Începând de la versiunea 2011 a stadardului C++ există o formă specială a instrucțiunii for, care permite parcurgerea elementelor unui container:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(int x : A)
cout << x << " ";
Specificatorul de tip auto poate fi folosit și aici. În secvența de mai sus, x reprezintă pe rând câte o copie a elementelor din A. Eventualele modificări ale lui x nu vor modifica valorile elementelor din A. Dacă se dorește modificare elemenelor din A, atunci x trebuie să fie o referință:
vector<int> A = {2 , 4 , 6 , 8 , 10};
for(int & x : A)
x *= 2;
for(int x : A)
cout << x << " ";
Parcurgerea inversă
Vectorii suportă iteratori reversibili, care permit parcurgerea containerului în ordine inversă. Clasa vector are metodele:
rbegin()– returnează un iterator reversibil la ultimul element din containerrend()– returnează un iterator reversibil la elementul din fața primului
Parcurgerea se poate face astfel:
for(vector<int>::reverse_iterator I = V.rbegin() ; I < V.rend() ; I ++) cout << *I << " ";
Inserarea elementelor
Pentru adăugarea la sfârșit se folosește metoda push_back(). Pentru inserarea de noi elemente în interiorul containerului se folosește metoda insert(), care are mai multe forme:
V.insert(pos , x)– inserează în vectorulV, în fața iteratoruluiposun nou element cu valoareax;V.insert(pos , cnt , x)inserează în vectorulV, în fața iteratoruluipos,cntnoi elemente egale cux;V.insert(pos , st , dr)inserează în vectorulV, în fața iteratoruluipos,dr-stnoi elemente, având valorile egale cu cele ale elementelor din secvența[st, dr)dintr-un container oarecare. Dacă vectorulVși secvența[st,dr)se suprapun rezultatul este impredictibil.
Rezultatul apelurilor de mai sus este un iterator la primul element inserat.
Apelurile de mai sus invalidează toți iteratorii și referințele la elemente din V, dacă în urma inserării se realocă memorie, respectiv se invalidează iteratorii și referințele din dreapta lui pos, în caz contrar.
Mai multe detalii despre insert() aici: https://en.cppreference.com/w/cpp/container/vector/insert.
Eliminarea elementelor
Pentru eliminarea tuturor elementelor intr-un vector există metoda clear().
V.clear();
În urma eliminării, rezultatul lui V.size() este 0.
Pentru eliminarea ultimului element al tabloului există metoda pop_back(). În urma apelului se invalidează iteratorii și referințele la ultimul element, precum și iteratorul end().
Pentru eliminarea unor elemente oarecare se folosește metoda erase(), cu următoarele forme:
V.erase(pos)– elimină elementul indicat de iteratorulpos.posnu poate fi egal cuend()V.erase(st , dr)– elimină elementele din intervalul[st,dr), undestșidrsunt iteratori la elemente dinV
Rezultatul funcției erase() este un iterator la elementul de după ultimul element eliminat.
Se invalidează iteratorii și iteratorii din dreapta lui posm inclusiv iteratorul end().
Mai multe detalii aici: https://en.cppreference.com/w/cpp/container/vector/erase.
C++ STL pair
Clasa C++ pair este definită în header-ul utility și permite încapsularea într-un obiect a unei perechi ordonate de date. Acestea pot fi de orice tip, inclusiv obiecte sau containere.
O variabilă de tip pair se declară astfel:
pair<T1 , T2> P;
de exemplu
pair<int , double> P;
P are două câmpuri. Primul este de tip T1 (int), al doilea de tip T2 (double). Acestea au numele first și second, iar accesul la ele se face prin operatorul de acces la câmp .: P.first și P.second.
Câmpurile lui P pot primi valori direct, prin atribuiri, de exemplu:
P.first = 10; P.second = 1.5;
O altă metodă prin care câmpurile pot primi valori este folosirea funcției make_pair(). Aceasta are doi parametri, de tipul celor două câmpuri:
P = make_pair(10 , 1.5);
Datele de același tip pair pot fi comparate cu operatorii ==, !=, <, <=, >, >=. Ordinea lor este cea lexicografică.
Standard Template Library - STL
Standard Template Library este o componentă importantă a limbajului C++, oferind structuri de date eficiente, mecanisme de utilizare a acestora și multe altele.
STL nu este cuprins în programa de informatică pentru liceu, dar poate fi folosit în rezolvarea multor probleme.
Introducere
Containere
Containerele stochează date; acestea pot fi de orice tip, inclusiv obiecte sau containere. Modul de stocare și operațiile existente diferă de la un container la altul.
- vector
- C++ vector – scurt tutorial
- Tablouri bidimensionale folosind STL
- set, map
- bitset
- stack, queue
- priority_queue
Algoritmi
Algoritmii se aplică la secvențe de elemente, care pot fi containere, părți ale containerelor sau alte structuri de date ce pot fi gestionate cu ajutorul pointerilor – de exemplu tablouri standard C.
- Algoritmi care nu modifică secvența
- Algoritmi care mută elementele din secvență
- Algoritmi de sortare și căutare
STL - Concepte fundamentale
Standard Template Library reprezintă un ansamblu de mecanisme scrise în C++ pentru gestionarea eficientă a unor colecții de date, împreună cu algoritmi eficienți care prelucrează aceste date. Este parte a Bibliotecii Standard C++, fiind astfel disponibilă în orice compilator care respectă standardul C++.
Introducere
STL are trei componente fundamentale: containerele, iteratorii și algoritmii, precum și o serie de componente suplimentare: containerele speciale, functorii, alocatorii.
Containerele
Containerele sunt obiecte care conțin date (de orice tip, putând fi la rândul containere). Alocarea memoriei pentru conținutul containerelor se face automat (de regulă dinamic), de către container.
Containerele sunt de două tipuri: containere secvențiale și containere asociative.
Containerele secvețiale gestionează un ansamblu de elemente dispuse strict liniar. Fiecare element al containerului are o poziție bine stabilită, care nu depinde de valoarea elementului. Avem următoarele contaniere secvențiale:
- vector – gestionează o secvență de elemente asemănătoare tablourilor standard C;
- deque (double-ended queue)- este o coadă cu operații rapide de adăugare și eliminare la ambele capete;
- list – gestionează o listă alocată dinamic, oferind operațiile de bază cu aceasta.
Timpul necesar pentru operațiile uzuale asupra containerelor secvențiale este redat mai jos:
| Operație | vector | deque | list |
|---|---|---|---|
| Accesarea primului element | constant | constant | constant |
| Accesarea ultimului element | constant | constant | constant |
| Accesarea unui element oarecare | constant | constant | liniar |
| Adăugare/ștergere la început | liniar | constant | constant |
| Adăugare/ștergere la sfârșit | constant | constant | constant |
| Adăugare/ștergere oarecare | liniar | liniar | constant |
Containerele asociative sunt structuri de date în care fiecare element are asociată o anumită cheie și are o anumită valoare. Ordinea elementelor în container depinde de cheie și se poate schimba în funcție de celelalte elemente. Aceste containere implementează eficient operațiile de adăugare de noi elemente, ștergere a elementelor în funcție de cheie, precum și căutarea elementelor după cheie.
Sunt două familii de containere asociative:
- set – în care cheia și valoarea elementelor sunt identice; containerele de acest tip sunt:
- set – memorează elemente distincte; elementele sunt menținute în ordine (strict) crescătoare;
- multiset – elementele pot fi egale și sunt menținute în ordine crescătoare;
- unordered_set – memorează elemente distincte; nu este garantată o anumită ordine a elementelor;
- unordered_multiset – elementele pot fi egale și nu este garantată o anumită ordine a elementelor
- map – cheile și valorile diferă; accesul la elemente se face prin intermediul cheii; containerele de acest tip sunt:
- map – cheile sunt distincte; elementele sunt menținute în ordine (strict) crescătoare a cheilor;
- multimap – cheile pot fi egale și sunt menținute în ordinea crescătoare a cheilor;
- unordered_map – cheile sunt distincte; nu este garantată o anumită ordine a elementelor;
- unordered_map – cheile pot fi egale și nu este garantată o anumită ordine a elementelor.
Timpii necesari pentru operațiile de adăugare, ștergere și acces sunt logaritmici pentru containerele asociative care menține elementele ordonate și constanți pentru containerele care nu mențin elementele în ordine.
Iteratorii
Iteratorii reprezintă o generalizare a conceputului de pointer. Ei oferă acces la elementele containerelor într-o manieră uniformă, pentru toate containere și pentru toți algoritmii STL.
Operațiile cu iteratorii sunt similare cu operațiile cu pointeri, putându-i dereferenția, incrementa/decrementa, compara, aduna cu întreg, etc. Unele operații sunt disponibile pentru toți iteratorii, altele doar pentru cei ai unor anumite tipuri de container.
Algoritmii
Algoritmii prelucrează colecții de elemente. Aceste colecții pot fi containere, părți ale unor containere sau slte structuri de date care permit lucrul cu pointeri (de exemplu tablouri standard C).
Algoritmii sunt folosiți sub formă de funcții, iar prelucrările pe care le fac sunt diverse: sortări, căutări, modificări, etc.
Containere speciale
Containerele speciale sunt:
- bitset – folosit pentru manipularea eficientă a șirurilor de biți
- containere adaptor – acoperă necesități speciale și sunt create pornind de la containere standard: containerele stack și queue permit gestionarea ușoară a unei stive, respectiv a unei cozi și sunt create pe baza containerului deque, iar containerul priority_queue gestionează o coadă de priorități (heap) și este creat pe baza clasei vector.
Functori și alocatori
Functorii sunt obiecte care se folosesc în maniera unui apel de funcție. Sunt folosite frecvent în cadrul algoritmilor.
Alocatorii sunt obiecte care gestionează alocarea memoriei pentru orice obiect și, în particular, pentru obiectele care fac parte dintr-un container.
Subiecte propuse MEC, aprilie-mai 2020
Subiectele propuse de Ministerul Educației și Cercetării pentru antrenamentul elevilor din clasele a XII-a în vederea susținerii examenului de bacalaureat.
Testul 1
- Matematică-informatică
- Științele naturii
Testul 2
- Matematică-informatică
- Științele naturii
Testul 3
- Matematică-informatică
- Științele naturii
Testul 4
- Matematică-informatică
- Științele naturii
Testul 5
- Matematică-informatică
- Științele naturii
Testul 6
- Matematică-informatică
- Științele naturii
Testul 7
- Matematică-informatică
- Științele naturii
Testul 8
- Matematică-informatică
- Științele naturii
Testul 9
- Matematică-informatică
- Științele naturii
Testul 10
- Matematică-informatică
- Științele naturii
Testul 11
- Matematică-informatică
- Științele naturii
Testul 12
- Matematică-informatică
- Științele naturii
Testul 13
- Matematică-informatică
- Științele naturii
Testul 14
- Matematică-informatică
- Științele naturii
Testul 15
- Matematică-informatică
- Științele naturii
Testul 16
- Matematică-informatică
- Științele naturii
Testul 17
- Matematică-informatică
- Științele naturii
Testul 18
- Matematică-informatică
- Științele naturii
Testul 19
- Matematică-informatică
- Științele naturii
Testul 20
- Matematică-informatică
- Științele naturii
Limbajul HTML - culori
În anumite situații trebuie să precizăm culori. Marcajele și atributele HTML care lucrează cu culori au devenit in mare măsură învechite și au fost înlocuite cu proprietăți CSS.
Așa cum știm, în calculator culorile sunt formate prin “amestecul” a trei culori de bază: red, green și blue. “Cantitatea” culorilor de bază variază între 0 și 255.
Culori în HTML
În HTML, culoarea poate fi precizată prin denumirea ei, (de exemplu red) sau prin codul ei hexazecimal (de exemplu #ff0000).
Codul hexazecimal este un șir de șase cifre hexazecimale (0, 1, .., 9, A, B, …, F), interpretate astfel:
- primele două cifre reprezintă cantitatea de red:
00reprezintă0, adică minim, iarFFreprezintă255, adică maxim; - următoarele două cifre reprezintă cantitatea de green
- ultimele două cifre reprezintă cantitatea de albastru
Sunt 16 culori cu denumire în HTML, deși este posibil ca browser-ele să recunoască mai multe denumiri de culoare:
black – #000000 |
silver – #C0C0C0 |
bgray – #808080 |
white – #FFFFFF |
||||
maroon – #800000 |
red – #FF0000 |
purple – #800080 |
fuchsia – #FF00FF |
||||
green – #008000 |
lime – #00FF00 |
olive – #808000 |
yellow – #FFFF00 |
||||
navy – #000080 |
blue – #0000FF |
teal – #008080 |
aqua – #00FFFF |
Culori în CSS
Cele mei multe atribute HTML care desemnează culori sunt învechite. Ele au fot înlocuite cu proprietăți CSS. Există mai multe proprietăți CSS care au ca valoare o culoare, de exemplu:
color– culoarea textului dintr-o casetăbackground-color– culoarea fundalului unei caseteborder-color– culoarea chenarului unei casete
Culorile pot fi precizate în CSS astfel:
- prin nume. Toate denumirile de culoare din HTML sunt disponibile în CSS. În plus, există multe alte denumire, disponibile aici: https://developer.mozilla.org/en-US/docs/Web/CSS/color_value.
- prin codul hexazecimal
#RRGGBB, cunoscut deja, sau prin codul hexazecimal extins#RRGGBBAA, undeAAreprezintă gradul de opacitate al culorii –00înseamnă complet transparent, iarFFînseamnă complet opac
<div style="background: url('wall-red.png'); padding:20px;">
<div style="background-color: #800080CC; color: teal; font-size: 2em; padding:20px; text-align: center;">
Culori
</div>
</div>
- prin codul hexazecimal scurt:
#RGBeste identic cu#RRGGBB#RGBAeste identic cu#RRGGBBAA
- folosind notația funcțională
rgb(r,g,b), under,gșibsunt numere (naturale scrise în baza10cu valori între0și255) sau procente (100%) corespunde cu255 - folosind notația funcțională
rgb(r,g,b,a), under,gșibsunt numere (naturale scrise în baza10cu valori între0și255) sau procente (100%) corespunde cu255.aeste un număr intre0(complet transparent) și1(complet opac) sau un procent (100%corespunde cu1); - folosind notația funcțională
hsl(h,s,l)sauhsl(h,s,l,a)– reprezentarea colorilor pe modelul HSL (hue, saturation, value). Detalii: https://en.wikipedia.org/wiki/HSL_and_HSV.
Limbajul HTML - entități
Anumite caratere nu pot fi inserate într-un document HTML, deoarece sunt folosite în marcarea conținutului. De exemplu caracterele < și >. Alte caractere nu există pe tastatură și este dificil să le scriem! Pentru asemenea situații s-a implementat conceptul de entitate HTML – o construcție care desemnează un caracter care nu poate fi inserat în alt mod, sau este dificil să facem acest lucru.
O entitate HTML este o bucată de text (un string) care începe cu & și se termină cu ;. De exemplu, pentru a insera caracterele < și > putem folosi entitățile < (lower than), respectiv > (greater than). O altă modalitate de a insera o entitate HTML este să-i precizăm codul numeric. Astfel, caracterul < poate fi inserat ca <.
O altă entitate utilă este – non breaking space. Scopul ei este să înlocuiască caracterul spațiu în situațiile în care dorim să ne asigurăm că nu separăm cuvintele pe rânduri diferite. O altă utilizare frecventă a acestei entități este să inserăm un spațiu mai mare între cuvinte – știut fiind că spațiile consecutive sunt ignorate de către browser.
<p> In HTML, pentru a insera un paragraf folosim eticheta <p>. </p>
O listă completă a entităților HTML este disponibilă aici.