Articolele lui
 Candale Silviu (silviu)
Candale Silviu (silviu)
Metoda Greedy
Metoda Greedy este o metodă care poate fi uneori folosită în rezolvarea problemelor de următorul tip: Se dă o mulțime A. Să se determine o submulțime B a lui A astfel încât să fie îndeplinite anumite condiții – acestea depinzând de problema propriu-zisă.
Algoritm general
De regulă problema dată poate fi rezolvată prin mai multe metode, printre care și Greedy. O rezolvare generală de tip Greedy a problemei de mai sus este următoarea:
B ← ∅
terminat ← FALSE
Execută
Alege convenabil x ∈ A
Dacă x poate fi adăugat în B Atunci
B ← B ∪ {x}
Altfel
terminat ← TRUE
SfârșitDacă
Cât timp terminat=FALSE
Altfel spus, pornim de la mulțimea vidă și adăugăm în mod repetat în B elemente până când acest lucru nu mai este posibil.
Observații
- stabilirea elementului care va fi adăugat în soluția
Bse face alegându-l pe cel mai bun din acel moment – este un optim local. Din acest motiv se numește Greedy (lacom); - după adăugarea în soluția
Ba unui anumit element, acesta va rămâne în soluție până la final. Nu există un mecanism de revenire la la un pas anterior, precum la metoda Backtracking; - alegerea optimului local nu duce întotdeauna la cea mai bună soluție
B; metoda Greedy nu este întotdeauna corectă; - schema prezentată mai sus este vagă și nu poate fi standardizată – să avem un algoritm detaliat care să poată fi aplicat de fiecare dată;
- sunt relativ puține probleme care pot fi rezolvate cu metoda Greedy;
- complexitatea metodei este de regulă polinomială – \( O(n^k)\), unde \(k\) este constant;
- folosim metoda Greedy în două situații:
- știm sigur că rezolvarea este corectă (avem o demonstrație de natură matematică a corectitudinii);
- nu avem decât soluții exponențiale (de tip Backtracking) și un algoritm Greedy dă o soluție nu neapărat optimă, dar acceptabilă.
- de regulă, înainte de începe alegerea elementelor convenabile din mulțimea
A, elementele sale sunt ordonate după un criteriu specific, astfel încât alegerea optimului local să fie cât mai rapidă;
Există câteva probleme celebre de algoritmică ce pot fi rezolvate cu metoda Greedy:
- Problema spectacolelor
- Problema continuă a rucsacului
- Algoritmul lui Dijkstra pentru determinarea drumurilor de cost minim într-un graf
- Algoritmul lui Prim și Algoritmul lui Kruskal pentru determinarea arborelui parțial de cost minim al unui graf
Greedy euristic
Există probleme pentru care avem nevoie de o rezolvare acceptabilă, chiar dacă singurele soluții demonstrate corecte sunt exponențiale, de multe ori inutile în practică.
Putem să aplicăm pentru aceste probleme metoda Greedy, obținând soluții neoptime, dar suficient de apropiate de soluția optimă pentru a fi acceptabile. Mai mult, în implementarea algoritmului se pot aplica diverse artificii la alegerea optimului local care pot duce la soluții din ce în ce mai bune, deși nu neapărat optime.
Un algoritm care obține o soluție acceptabilă, deși nu neapărat optimă, se numește Greedy euristic.
O problemă cu o soluție euristică interesantă este Săritura calului1 (enunț modificat):
Se consideră o tablă de șah cu n linii și m coloane. La o poziție dată se află un cal de șah, acesta putându-se deplasa pe tablă în modul specific acestei piese de șah (în L). Să se determine o modalitate de parcurgere a tablei de către cal, astfel încât acesta să nu treacă de două ori prin aceeași poziție.
Pentru dimensiuni mici ale tablei se poate folosi metoda Backtracking, aceasta determinând o soluție optimă. Dacă dimensiunile tablei sunt mari, metoda Backtracking nu mai poate fi folosită. Putem încerca o strategie Greedy:
- plecăm de la poziția inițială,
istart jstart - cât timp este posibil
- alegem o poziție vecină în L cu poziția curentă în care nu am mai fost
- marcăm poziția aleasă într-un anumit mod și o considerăm poziție curentă
Succesul algoritmului Greedy stă în alegerea poziției vecine! Desigur, nu orice metodă duce la parcurgerea completă a tablei. Neexistând un mecanism de întoarcere la o stare anterioară, când nu mai găsim poziție vecină liberă pentru poziția curentă algoritmul se încheie.
O strategie de succes este să alegem pentru poziția curentă poziția vecină cel mai greu accesibilă la pasul următor – poziția vecină cu număr minim de vecini neparcurși. Teoretic, fiecare poziție de pe tablă are 8 poziții vecini, dar unele sunt în afara tablei, altele sunt deja parcurse, astfel că putem alege dintre cei 8 vecini ai poziției curente un vecin care la rândul său are număr minim de vecini neparcurși.
Mai mult, dacă există mai mulți vecini ai poziției curente cu număr minim de vecini neparcurși, putem varia vecinul cu care vom continua: primul găsit, ultimul găsit, cel mai de sus, cel mai de jos, îl alegem aleatoriu, etc., sporind șansele de a realiza o parcurgere completă a tablei.
 Candale Silviu (silviu)
Candale Silviu (silviu) Metoda Backtracking
Metoda backtracking poate fi folosită în rezolvarea a diverse probleme. Este o metodă lentă, dar de multe ori este singura pe care o avem la dispoziție!
Introducere
Metoda backtracking poate fi aplicată în rezolvarea problemelor care respectă următoarele condiții:
- soluția poate fi reprezentată printr-un tablou
x[]=(x[1], x[2], ..., x[n]), fiecare elementx[i]aparținând unei mulțimi cunoscuteAi; - fiecare mulțime
Aieste finită, iar elementele ei se află într-o relație de ordine precizată – de multe ori celenmulțimi sunt identice; - se cer toate soluțiile problemei sau se cere o anumită soluție care nu poate fi determinată într-un alt mod (de regulă mai rapid).
Algoritmul de tip backtracking construiește vectorul x[] (numit vector soluție) astfel:
Fiecare pas k, începând (de regulă) de la pasul 1, se prelucrează elementul curent x[k] al vectorului soluție:
x[k]primește pe rând valori din mulțimea corespunzătoareAk;- la fiecare pas se verifică dacă configurația curentă a vectorului soluție poate duce la o soluție finală – dacă valoarea lui
x[k]este corectă în raport cux[1],x[2], …x[k-1]:- dacă valoarea nu este corectă, elementul curent
X[k]primește următoarea valoare dinAksau revenim la elementul anteriorx[k-1], dacăX[k]a primit toate valorile dinAk– pas înapoi; - dacă valoarea lui
x[k]este corectă (avem o soluție parțială), se verifică existența unei soluții finale a problemei:- dacă configurația curentă a vectorului soluție
xreprezintă soluție finală (de regulă) o afișăm; - dacă nu am identificat o soluție finală trecem la următorul element,
x[k+1], și reluăm procesul pentru acest element – pas înainte.
- dacă configurația curentă a vectorului soluție
- dacă valoarea nu este corectă, elementul curent
Pe măsură ce se construiește, vectorul soluție x[] reprezintă o soluție parțială a problemei. Când vectorul soluție este complet construit, avem o soluție finală a problemei.
Exemplu
Să rezolvăm următoarea problemă folosind metoda backtracking, “cu creionul pe hârtie”: Să se afișeze permutările mulțimii {1, 2, 3}.
Ne amintim că un șir de numere reprezintă o permutare a unei mulțimi M dacă și numai dacă conține fiecare element al mulțimii M o singură dată. Altfel spus, în cazul nostru:
- are exact
3elemente; - fiecare element este cuprins între
1și3; - elementele nu se repetă.
Pentru a rezolva problemă vom scrie pe rând valori din mulțimea dată și vom verifica la fiecare pas dacă valorile scrise duc la o permutare corectă:
k |
x[] |
Observații |
|---|---|---|
1 |
1 – – | corect, pas înainte |
2 |
1 1 – | greșit |
2 |
1 2 – | corect, pas înainte |
3 |
1 2 1 | greșit |
3 |
1 2 2 | greșit |
3 |
1 2 3 | soluție finală 1 |
3 |
1 2 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
1 3 – | corect, pas înainte |
3 |
1 3 1 | greșit |
3 |
1 3 2 | soluție finală 2 |
3 |
1 3 3 | greșit |
3 |
1 3 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
1 ! – | am terminat valorile posibile pentru x[ 2 ], pas înapoi |
1 |
2 – – | corect, pas înainte |
2 |
2 1 – | corect, pas înainte |
3 |
2 1 1 | greșit |
3 |
2 1 2 | greșit |
3 |
2 1 3 | soluție finală 3 |
3 |
2 1 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
2 2 – | greșit |
2 |
2 3 – | corect, pas înainte |
3 |
2 3 1 | soluție finală 4 |
3 |
2 3 2 | greșit |
3 |
2 3 3 | greșit |
3 |
2 3 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
2 ! – | am terminat valorile posibile pentru x[ 2 ], pas înapoi |
1 |
3 – – | corect, pas înainte |
2 |
3 1 – | corect, pas înainte |
3 |
3 1 1 | greșit |
3 |
3 1 2 | soluție finală 5 |
3 |
3 1 3 | greșit |
3 |
3 1 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
3 2 – | corect, pas înainte |
3 |
3 2 1 | soluție finală 6 |
3 |
3 2 2 | greșit |
3 |
3 2 3 | greșit |
3 |
3 2 ! | am terminat valorile posibile pentru x[ 3 ], pas înapoi |
2 |
3 3 – | greșit |
2 |
3 ! – | am terminat valorile posibile pentru x[ 2 ], pas înapoi |
1 |
! – – | am terminat valorile posibile pentru x[ 1 ], pas înapoi |
Formalizare
Pentru a putea realiza un algoritm backtracking pentru rezolvarea unei probleme trebuie să răspundem la următoarele întrebări:
- Ce memorăm în vectorul soluție
x[]? Uneori răspunsul este direct; de exemplu, la generarea permutărilor vectorul soluție reprezintă o permutare a mulțimiiA={1,2,...,n}. În alte situații, vectorul soluție este o reprezentare mai puțin directă a soluției; de exemplu, generarea submulțimilor unei mulțimi folosind vectori caracteristici sau Problema reginelor. - Ce valori poate lua fiecare element
x[k]vectorului soluție și câte elemente poate aveax[]? Altfel spus, care sunt mulțimileAk. Vom numi aceste restricții condiții externe. Cu cât condițiile externe sunt mai restrictive (cu cât mulțimileAkau mai puține elemente), cu atât va fi mai rapid algoritmul! - Ce condiții trebuie să îndeplinească
x[k]ca să fie considerat corect? Elementulx[k]a primit o anumită valoare, în conformitate ce condițiile externe. Este ea corectă? Poate conduce la o soluție finală? Aceste condiții se numesc condiții interne și în ele pot să intervină doarx[k]și elementelex[1],x[2], …,x[k-1]. Elementelex[k+1], …,x[n]nu poti apărea în condițiile interne deoarece încă nu au fost generate!!! - Am găsit o soluție finală? Elementul
x[k]a primit o valoare conformă cu condițiile externe, care respectă condițiile interne. Am ajuns la soluție finală sau continuăm cux[k+1]?
Exemplu. Pentru problema generării permutărilor mulțimii \(A=\{1, 2, 3, …, n\}\), condițiile de mai sus sunt:
- Vectorul soluție conține o permutare a mulțimii \( A \);
- Condiții externe: \( x[k] \in \{1,2,3,…,n\} \) sau \( x[k] = \overline{1,n} \), pentru \( k = \overline{1,n} \)
- Condiții interne: \( x[k]\neq x[i] \), pentru \( i = \overline{1,k-1} \)
- Condiții de existență a soluției: \( k = n \)
Algoritmul general
Metoda backtracking poate fi implementată iterativ sau recursiv. În ambele situații se se folosește o structură de deate de tip stivă. În cazul implementării iterative, stiva trebuie gestionată intern în algoritm – ceea ce poate duce la dificulăți în implementăre. În cazul implementării recursive se folosește spațiu de memorie de tip stivă – STACK alocat programului; implementarea recursivă este de regulă mai scurtă și mai ușor de înțeles. Acest articol prezintă implementări recursive ale metodei.
Următorul subprogram recursiv prezintă algoritmul la modul general:
- la fiecare apel
BACK(k)se generează valori pentru elementulx[k]al vectorului soluție; - instrucțiunea
Pentrumodelează condițiile externe; - subprogramul
OK(k)verifică condițiile interne - subprogramul
Solutie(k)verifică dacă configurația curentă a vectorului soluție reprezintă o soluție finală - subprogramul
Afisare(k)tratează soluția curentă a problemei – de exemplu o afișează!
subprogram BACK(k)
┌ pentru fiecare element i din A[k] executa
│ x[k] ← i
│ ┌ daca OK(k) atunci
│ │ ┌ daca Solutie(k) atunci
│ │ │ Afisare(k)
│ │ │ altfel
│ │ │ BACK(k+1)
│ │ └■
│ └■
└■
sfarsit_subprogram
Observații:
- de cele mai multe ori mulțimile \(A\) sunt de forma \( A=\{1, 2, 3, …. , n \} \) sau \( A=\{1, 2, 3, …. , m \} \) sau \( A=\{a, a + 1, a + 2, …. , b \} \) sau o altă formă astfel încât să putem scrie instrucțiunea
Pentruconform specificului limbajului de programare folosit – eventual folosind o structură repetitivă de alt tip! Dacă este necesar, trebuie realizate unele transformări încât mulțimile să ajungă la această formă! - elementele mulțimii \( A \) pot fi in orice ordine. Contează însă ordinea în care le vom parcurge în instrucțiunea
Pentru, deoarece în probleme este precizată de obicei o anumită ordine în care trebuie generate soluțiile:- dacă parcurgem elementele lui \( A \) în ordine crescătoare vom obține soluții în ordine lexicografică;
- dacă parcurgem elementele lui \( A \) în ordine descrescătoare vom obține soluții în ordine invers lexicografică.
- în anumite probleme determinarea unei soluții finale nu conduce la întreruperea apelurilor recursive. Un exemplu este generarea submulțimilor unei mulțimi. În acest caz algoritmul de mai sus poate fi modificat astfel:
┌ daca OK(k) atunci
│ ┌ daca Solutie(k) atunci
│ │ Afisare(k)
│ └■
│ BACK(k+1)
└■
Bineînțeles, trebuie să ne asigurăm că apelurile recursive se opresc!
Un șablon C++
Următoarea secvență C++ oferă un șablon pentru rezolvarea unei probleme oarecare folosind metoda backtracking. Vom considera în continuare următoarele condiții externe: \( x[k] = \overline{A,B} \), pentru \( k = \overline{1,n} \). În practică \( A \) și \( B \) vor avea valori specifice problemei:
#include <fstream>
using namespace std;
int x[10] ,n;
int Solutie(int k){
// x[k] verifică condițiile interne
// verificare dacă x[] reprezintă o soluție finală
return 1; // sau 0
}
int OK(int k){
// verificare conditii interne
return 1; // sau 0
}
void Afisare(int k)
{
// afișare/prelucrare soluția finală curentă
}
void Back(int k){
for(int i = A ; i <= B ; ++i)
{
x[k]=i;
if( OK(k) )
if(Solutie(k))
Afisare(k);
else
Back(k+1);
}
}
int main(){
//citire date de intrare
Back(1);
return 0;
}
De multe ori condițiile de existență a soluției sunt simple și nu se justifică scrierea unei funcții pentru verificarea lor, ele putând fi verificate direct în funcția Back().
De cele mai multe ori, rezolvarea unei probleme folosind metoda backtracking constă în următoarele:
- stabilirea semnificației vectorului soluție;
- stabilirea condițiilor externe;
- stabilirea condițiilor interne;
- stabilirea condițiilor de existența a soluției finale;
- completarea adecvată a șablonului de mai sus!
Complexitatea algoritmului
Algoritmii Backtracking sunt exponențiali. Complexitatea depinde de la problemă la problemă dar este de tipul \( O(a^n) \). De exemplu:
- generarea permutărilor unei mulțimi cu
nelemente are complexitatea \( O(n!)\); - generarea submulțimilor unei mulțimi cu
nelemente are complexitatea \( O(2^n) \) - produsul cartezian \( A^n\) unde mulțimea \( A=\{1,2,3,…,m\}\) are complexitatea \(O(m^n)\)
- etc.
PbInfo propune spre rezolvare cu metoda backtracking câteva zeci de probleme! SUCCES!
Citește mai departe
Citiri și scrieri cu format în C++
Operațiile de citire și afișare se realizează de cele mai multe ori aplicându-se niște reguli standard ale limbajului C++, acest lucru fiind de regulă suficient. De exemplu, valorile întregi se afișează în baza 10, valorile reale se afișează de regulă cu 6 cifre (în fața și în spatele punctului zecimal), etc. Uneori este necesar să formatăm mai precis afișările și citirile, aceasta fiind tema prezentului articol.
Introducere
Formatarea citirii și afișării se face prin intermediul unor funcții speciale, numite manipulatori. O parte dintre ele se află în fișierele header fstream și iostream (probabil deja incluse), altele se află în fișierul header iomanip – care trebuie și el inclus.
Afișarea poate fi formatată precizându-se:
- lungimea –
setw(int n): numărulnde caractere care vor fi utilizate pentru afișarea valorii dorite – implicit este variabil și egal cu numărul de caractere necesar. Modificând lungimea putem afișa date în format tabelar, distingându-se clar liniile și coloanele; - alinierea –
left,right,internal: în cazul în care valoarea afișată ocupă mai puține caractere decât lungimea, ea poate fi aliniată la dreapta (implicit) sau la stânga (pentru orice fel de date) sau internal, pentru date numerice (întregi sau reale); - caracterul de umplere –
setfill(char f): dacă valoarea afișată ocupă mai puține caractere decât lungimea, pe pozițiile nefolosite se vor scrie caractere de umplere – implicit spații; - precizia –
setprecision(int n): numărulnde cifre folosite pentru afișarea valorilor reale; în funcție de context, poate reprezenta numărul total de cifre sau numărul de cifre de după punctul zecimal - baza de numerație (
dec,oct,hex) în care sunt scrise valorile de tip întreg. Valorile întregi se pot scrie în baza 10 (implicit), baza 8 sau baza 16; - formatul de afișare (
fixed,scientificsau implicit) valorilor reale.
Citirea poate fi formatată precizându-se:
- baza de numerație (
dec,oct,hex) în care se consideră valoarea întreagă introdusă. Se pot citi valori în bazele10,8sau16. - modul de tratare a caracterelor albe –
skipws,noskipws: implicit, la citire se sare peste eventualele caracterele albe aflate înainte de valoarea de citit (skipws). Dacă este setat modulnoskipwsși înainte de valoarea de citit există caractere albe, citirea va eșua.
Manipulatorii se folosesc ca operanzi în operația de inserare în stream (cout << ) sau extragere din stream (cin >>). Unii dintre ei au efect în mod direct, alții au efect numai în combinație cu alți manipulatori. Unii manipulatori au efect doar asupra următoarei date afișate, alții au efect pentru toate datele care sunt afișate în continuare.
Formatare afișării
Lungimea
Lungimea unei date afișate se referă la numărul de caractere folosite pentru afișarea acelei date. Implicit se folosesc atâtea caractere cât este necesar. De exemplu, pentru a afișa numărul 2019 se folosesc 4 caractere. Acest comportament poate fi modificat cu ajutorul manipulatorului setw(n), unde n reprezintă numărul de caractere folosite pentru afișare:
cout << "|" << 2019 << "|" << endl; cout << "|" << setw(10) << 2019 << "|" << endl;

Când lungimea de afișare este specificată (și mai mare decât cea ocupată efectiv), data poate fi aliniată la stânga (left) sau la dreapta (right) zonei de afișare.
cout << "|" << setw(10) << 2019 << "|" << endl; cout << "|" << setw(10) << left << 2019 << "|" << endl; cout << "|" << setw(10) << right << 2019 << "|" << endl;

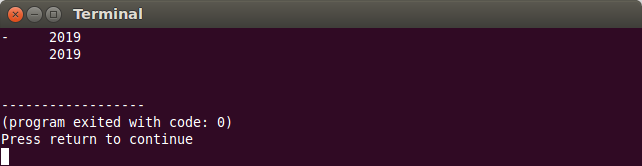
La afișarea valorilor numerice, se poate face o aliniere specială: semnul să fie aliniat la stânga, iar valoarea să fie aliniată la dreapta. Se va folosi manipulatorul internal:
cout << setw(10) << internal << -2019 << endl; cout << setw(10) << internal << 2019 << endl;
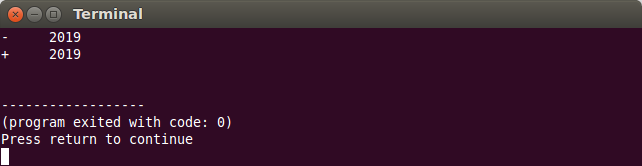
Implicit, pentru valorile pozitive nu se afișează semnul. Acest lucru poate fi gestionat cu modificatorii showpos și noshowpos:
cout << setw(10) << internal << -2019 << endl; cout << setw(10) << showpos << internal << 2019 << endl;
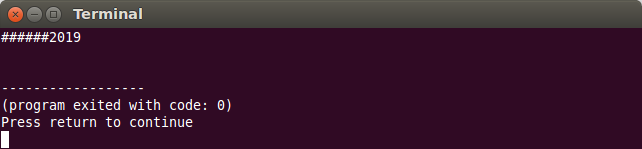
Dacă lungimea de afișare este mai mare decât lungimea datei afișate, caracterele suplimentare sunt implicit spații. Putem modifica acest caracter prin intermediul modificatorului setfill(char), de exemplu:
cout << setw(10) << setfill('#') << 2019 << endl;
Afișarea datelor întregi
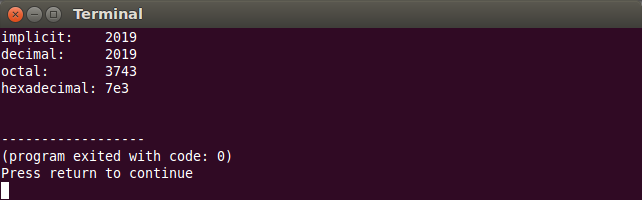
Valorile întregi pot fi afișate (și citite) în baza 10 (decimal, dec), baza 8 (octal, oct) sau baza 16 (hexadecimal, hex):
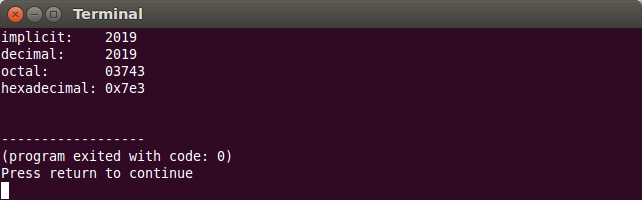
int n = 2019; cout << "implicit: " << n << endl; cout << "decimal: " << dec << n << endl; cout << "octal: " << oct << n << endl; cout << "hexadecimal: " << hex << n << endl;
Implicit, pentru valorile afișate în baza 8 și 16 nu se afișează prefixul care precizează baza (0, respectiv 0x). Aceasta poate fi gestionată cu manipulatorii showbase și noshowbase:
int n = 2019; cout << "implicit: " << n << endl; cout << "decimal: " << showbase << dec << n << endl; cout << "octal: " << oct << n << endl; cout << "hexadecimal: " << hex << n << endl;
Manipulatorii uppercase și nouppercase stabilesc dacă prefixul (Ox, afișat cu showbase) precum și cifrele a, b, c, d, e, f pentru valorile în baza 16 este scris cu litere mari sau nu: 0X7E3 sau 0x7e3 – pentru valoarea zecimală 2019. Acești manipulatori controlează și modul de afișare în forma științifică a datelor reale.
Afișarea valorilor reale
Valorile reale sunt stocate folosind formatul cu virgulă mobilă, iar valoarea afișată este o aproximare a valorii memorate. Modul în care sunt afișate datele reale depinde de mai mulți factori: precizia, formatul de afișare (fix, științific sau implicit), etc.
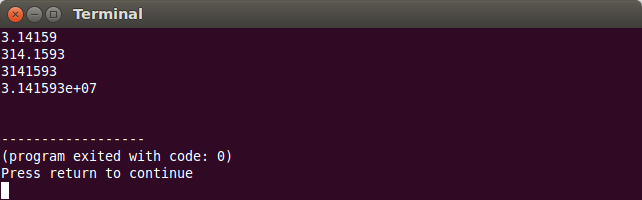
Precizia reprezintă numărul de cifre folosite pentru afișare sau numărul de zecimale afișate. Precizia are implicit valoarea 6 și este în strânsă legătură cu formatul de afișare:
- formatul implicit afișează valoarea în forma fixă sau în forma științifică, în funcție de precizie. Fie
nnumărul de cifre ale părții întregi a valorii de afișat și fiepprecizia curentă:- dacă
n≤p, se va folosi formatul fix de afișare, iar pentru partea zecimală se vor afișap-nzecimale, cu rotunjire - dacă
n>p, se va folosi formatul științific de afișare, cu mantisă și caracteristică, iar precizia reprezintă numărul de cifre ale mantisei
- dacă
double pi = atan(1) * 4; // PI // afisare implicită, precizie implicită 6 cout << pi << endl; // format implicit; precizie 7, 3 cifre la partea intreaga, 4 la partea fractionara cout << setprecision(7) << 100 * pi << endl; // format implicit; precizie 7, 7 cifre la partea intreaga, 0 la partea fractionara cout << setprecision(7) << 1000000 * pi << endl; // format implicit; precizie 7, 8 cifre la partea intreaga; se afiseaza in format stiintific cout << setprecision(7) << 10000000 * pi << endl;
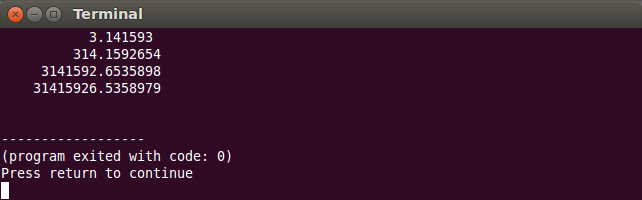
- dacă formatul de afișare precizat este formatul fix, prin intermediul manipulatorului
fixed, precizia reprezintă numărul de cifre aflate după punctul zecimal:
double pi = atan(1) * 4; // PI cout << fixed; // ATENTIE AICI!! cout << right; //format fix, precizie implicită 6, 6 cifre zecimale cout << setw(19) << pi << endl; // format fix; precizie 7, 7 cifre zecimale cout << setw(20) << setprecision(7) << 100 * pi << endl; cout << setw(20) << setprecision(7) << 1000000 * pi << endl; cout << setw(20) << setprecision(7) << 10000000 * pi << endl;
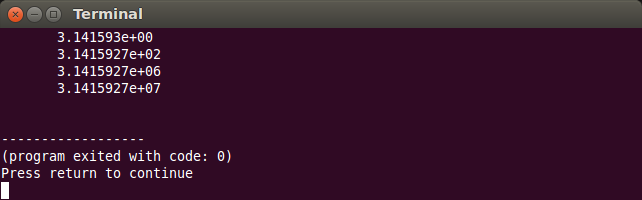
- dacă formatul de afișare este cel științific, prin intermediul manipulatorului
scientific, precizia reprezintă numărul de zecimale ale mantisei:
double pi = atan(1) * 4; // PI cout << scientific; // ATENTIE AICI!! cout << right; //format fix, precizie implicită 6, 6 zecimale la mantisa cout << setw(19) << pi << endl; // format fix; precizie 7, 7 zecimale la mantisa cout << setw(20) << setprecision(7) << 100 * pi << endl; cout << setw(20) << setprecision(7) << 1000000 * pi << endl; cout << setw(20) << setprecision(7) << 10000000 * pi << endl;
La afișarea în format implicit, datele de tip real care nu contin zecimale (au partea fracționară nulă, de exemplu 1.0) vor fi afișate fără zecimale și fără punctul zecimal. Acest comportament poate fi gestionat cu ajutorul manipulatorilor showpoint și noshowpoint.
Afișare valorilor de tip bool
Implicit, valorile de tip bool sunt afișate ca valori numerice. Mai precis:
cout << true << endl; // 1 cout << false << endl; // 0
Este însă posibil să se afișeze și literalii true sau false, cu ajutorul manipulatorilor boolalpha și noboolalpha:
cout << boolalpha << true << endl; // true cout << false << endl; // false cout << noboolalpha; cout << true << endl; // 1 cout << false << endl; // 0
Formatarea citirii
Implicit la citire se sare peste caracterele albe aflate înaintea valorii care se citește. Mai precis:
char x,y,z; cin >> x >> y >> z; // A B C cout << x << y << z; //ABC
Dacă se introduce șirul A B C, variabila x va avea valoarea 'A', y va avea valoarea 'B', iar z va avea valoarea 'C'. Caracterele spațiu sunt sărite. Acest comportament este gestionat prin manipulatorii skipws și noskipws.
char x,y,z; cin >> noskipws; cin >> x >> y >> z; // A B C cout << x << y << z; //A B
Dacă se introduce șirul A B C, variabila x va avea valoarea 'A', y va avea valoarea ' ', iar z va avea valoarea 'B'. Ultimele două caractere sunt ignorate (rămân în stream).
Dacă variabila citită nu poate memora spații (de exemplu este numerică) dar primele caractere sunt albe, citirea va eșua. Variabila va deveni 0 (începând cu C++11) și se va seta failbit, astfel că următoarele citiri nu vor mai avea loc.
int x = 10, y = 10; cin >> noskipws; cin >> x; // " 25" cout << x << " " << y; // 0 10
La citirea variabilelor întregi se poate preciza baza în care sunt valorile așteptate prin manipulatorii dec, oct sau hex.
int x; cin >> hex >> x; // ff cout << x; // 255
Structuri repetitive - introducere
Să considerăm următoarea problemă: “Se citesc trei numere naturale. Să se determine suma lor.” Desigur, este o problemă banală, dar haideți să o analizăm și să vedem mai multe soluții!
Soluția 1
Folosim trei variabile: a, b, c. Le citim și afișăm suma lor.
#include <iostream>
using namespace std;
int main()
{
int a, b, c;
cin >> a >> b >> c;
cout << a + b + c;
return 0;
}
Soluția 2
Această soluție este asemănătoare cu cea anterioară, dar calculăm suma valorilor într-o variabilă suplimentară.
#include <iostream>
using namespace std;
int main()
{
int a, b, c, S;
cin >> a >> b >> c;
S = a + b + c;
cout << S;
return 0;
}
Soluția 3
Vom calcula suma valorilor pe rând. Atenție la inițializarea lui S cu 0!!!
#include <iostream>
using namespace std;
int main()
{
int a, b, c, S;
S = 0;
cin >> a >> b >> c;
S = S + a;
S = S + b;
S = S + c;
cout << S;
return 0;
}
Soluția 4
Observăm că după ce adunăm la S valoarea unei variabile, nu o mai folosim. Putem astfel să folosim o singură variabilă în care să citim de trei ori câte un număr și, după fiecare citire, să adunăm la S valoarea curentă a variabilei.
#include <iostream>
using namespace std;
int main()
{
int a, S;
S = 0;
cin >> a;
S = S + a;
cin >> a;
S = S + a;
cin >> a;
S = S + a;
cout << S;
return 0;
}
Soluția 5
Observă că în soluția anterioară am scris de trei ori aceleași instrucțiuni: cin >> a; S = S + a;. Trebuie înțeles că ele s-au executat de trei ori, dar valorile pe care le aveau variabilele s și S la fiecare pas erau diferite.
Aici intervin structurile repetitive: În loc să scriem de trei ori aceleași instrucțiuni, le vom scrie o singură dată, dar vom cere să fie executate de trei ori!. De exemplu putem folosi instrucțiunea while:
#include <iostream>
using namespace std;
int main()
{
int a, S;
S = 0;
int i = 1;
while(i <= 3)
{
cin >> a;
S = S + a;
i++;
}
cout << S;
return 0;
}
O altă soluție, folosind instrucțiunea for:
#include <iostream>
using namespace std;
int main()
{
int a, S;
S = 0;
for(int i = 1 ; i <= 3 ; i ++)
{
cin >> a;
S = S + a;
}
cout << S;
return 0;
}Structuri de date liniare
Algoritmii prelucrează date organizate în diverse moduri:
- date simple, neorganizate ca structuri de date;
- date organizate ca strucuri de date liniare – listele: rezultatele la un concurs, lista de cumpărături, etc;
- date organizate ca structuri de date arborescente: organigrama unei instituții, arborele genealogic al unei persoane, regnul animal, etc.
- etc.
O structură de date reprezintă un ansamblu de date caracterizat prin relațiile dintre acestea și prin operațiile care pot fi realizate cu datele respective.
Datele care fac parte din structură sunt de un tip oarecare, de obicei structurat (tipul C/C++ struct), care nu caracterizează structura de date. Ele se numesc elemente sau noduri și uneori articol sau înregistrare.
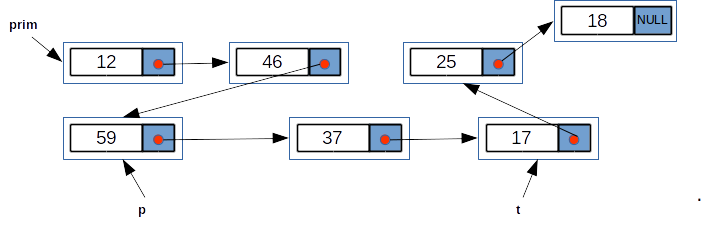
Generarea permutărilor
Citiți mai întâi Metoda backtraking
Prin permutare a unei mulțimi înțelegem o aranjare a elementelor sale, într-o anumită ordine. Este cunoscut, printre altele, faptul că numărul de permutări ale unei mulțimi cu n elemente este \(P_n = n! = 1 \cdot 2 \cdot \cdot \cdots \cdot n \). Prin convenție, \(P_0 = 0! = 1\).
Problema
Fie un număr natural
n. Să se afișeze, în ordine lexicografică, permutările mulțimii \( \left\{ 1, 2, , \cdots , n \right\}\).
Exemplu
Pentru n=3, se va afișa:
1 2 3 1 3 2 2 1 3 2 3 1 3 1 2 3 2 1
Rezolvare
Bineînțeles, vom rezolva problema prin metoda backtracking. Vectorul soluție x[] va reprezenta o permutare candidat. Să ne gândim care sunt proprietățile unei permutări, pe care le va respecta și vectorul x[]:
- elementele sunt numere naturale cuprinse între
1șin; - elementele nu se repetă;
- vectorul
x[]se construiește pas cu pas, element cu element. El va conține o permutare validă când va conținenelemente, desigur corecte.
Cele observate mai sus ne permit să precizăm condițiile specifice algoritmului backtracking, într-un mod mai formal:
- condiții externe: \( x[k] \in \left\{ 1,2, \cdots, n \right\} \);
- condiții interne: \(x[k] \notin \left\{ x[ 1 ],x[ 2 ], \cdots, x[ k-1 ] \right\}\), pentru \( k \in \left\{2,3, \cdots, n \right \} \)
- condiții de existență a soluției: \(k = n\)
Sursă C++
Următorul program afișează pe ecran permutările, folosind un algoritm recursiv:
#include <iostream>
using namespace std;
int x[10] ,n;
void Afis()
{
for( int j=1;j<=n;j++)
cout<<x[j]<<" ";
cout<<endl;
}
bool OK(int k){
for(int i=1;i<k;++i)
if(x[k]==x[i])
return false;
return true;
}
bool Solutie(int k)
{
return k == n;
}
void back(int k){
for(int i=1 ; i<=n ; ++i)
{
x[k]=i;
if( OK(k) )
if(Solutie(k))
Afis();
else
back(k+1);
}
}
int main(){
cin>>n;
back(1);
return 0;
}
Semnificația funcțiilor
void Afis();afișează soluția curentă. Când se apelează, vectorul soluțiexarenelemente, reprezentând o permutare completă;bool OK(int k);verifică condițiile interne. La apel,x[k]tocmai a primit o valoare conform condițiilor externe. Prin funcțiaOK()se va verifica dacă această valoare este validă;bool Solutie(int k);verifică dacă avem o soluție completă. Acest lucru se întâmplă când permutarea este completă – am dat o valoare corectă ultimului element al tabloului,x[n], adică atunci cândk=n;void back(int k);– apelul acestei funcții dă valori posibile elementuluix[x]al vectorului soluție și le verifică:- se parcurg valorile pe care le pot lua elementele vectorului, conform condițiilor externe (în acest caz,
1..n);- se memorează în
x[k]valoarea curentă; - dacă valoarea lui
x[k]este corectă, conform condițiilor interne, se verifică dacă avem o soluție completă. În caz afirmativ se afișează această soluție, în caz contrar se trece la următorul element, prin apelul recursiv;
- se memorează în
- la finalul parcurgerii, se revine la elementul anterior al vectorului
x, prin revenirea din apelul recursiv.
- se parcurg valorile pe care le pot lua elementele vectorului, conform condițiilor externe (în acest caz,
Observații
- generarea valorilor din vectorul soluție începe cu primul element al acestuia,
x[ 1 ]; în consecință, apelul principal al funcțieiback()esteback(1); - generarea permutărilor în ordine lexicografică se obține datorită faptului că, în funcția
back()valorile posibile pe care le primeștex[k]sunt parcurse în ordine crescătoare (for(int i=1 ; i<=n ; ++i)....). Dacă am fi parcurs valorile de lanla1, s-ar fi generat permutările în ordine invers lexicografică; - algoritmul este exponențial și poate fi folosit numai pentru valori mici ale lui
n. O soluție ceva mai bună se poate obține dacă, pentru a stabili corectitudinea condițiilor interne, evităm parcurgerea elementelor deja memorate în vectorul soluție. Acest lucru poate fi realizat prin intermediul unui vector caracteristic, cu semnificația:v[p] = 1dacă valoareapface deja parte din permutare, șiv[p]=0dacăpnu face parte din permutare.
Varianta iterativă
În general, algoritmii nerecursivi sunt mai buni decât cei recursivi, deși uneori sunt mai dificil de urmărit. Următorul program iterativ afișează și el permutările pe ecran:
#include <iostream>
using namespace std;
int n , x[100];
void afisare(int k){
for(int i = 1 ; i <= k ; i ++)
cout << x[i] << " ";
cout << endl;
}
bool OK(int k){
for(int i = 1 ; i < k ; i ++)
if(x[i] == x[k])
return 0;
return 1;
}
void back()
{
int k = 1;
x[1] = 0;
while(k > 0)
{
bool gasit = false;
do{
x[k] ++;
if(x[k] <= n && OK(k))
gasit = true;
}
while(! gasit && x[k ] <= n);
if(! gasit)
k --;
else
if(k < n)
{
k ++;
x[k] = 0;
}
else
afisare(k);
}
}
int main(){
cin >> n;
back();
return 0;
}

O variantă (puțin) mai bună
Algoritmul de generarea a permutărilor este unul exponențial, deci lent. Totuși, poate fi ușor îmbunățit în ceea ce privește verificarea condițiilor interne. Acestea cer ca valoarea curentă a lui x[k] (elementul care se generează) să nu se repete. În varianta anterioară am parcurs elementele care îl preced și le-am comparat cu x[k].
Această parcurgere poate fi evitată dacă folosim un vector caracteristic, uz[], cu următorul înțeles:
\(uz[v] = \begin{cases}
1& \text{dacă valoarea } v \text{ a fost plasată deja în vectorul soluție},\\
0& \text{dacă valoarea } v \text{ nu a fost plasată încă în vectorul soluție}
\end{cases} \)
Următoarele programe folosesc această idee. Primul respectă îndeaproape schema anterioară, în timp ce al doilea este mai scurt – verificarea condițiilor interne și a celor de existență a soluției făcându-se în în funcția back(), fără a mai scrie funcții de sine stătătoare:
#include <iostream>
using namespace std;
int x[10] , n , p, uz[10];
void Afis(int k)
{
for(int j = 1 ; j <= k ; j ++)
cout << x[j] << " ";
cout << endl;
}
bool OK(int k){
return uz[x[k]] == 0;
}
bool Solutie(int k)
{
return k == n;
}
void back(int k){
for(int i = 1 ; i <= n ; ++ i)
{
x[k] = i;
if(OK(k))
{
uz[i] = 1;
if(Solutie(k))
Afis(k);
else
back(k + 1);
uz[i] = 0;
}
}
}
int main(){
cin >> n;
back(1);
return 0;
}
#include <iostream>
using namespace std;
int x[10] , n , p, uz[10];
void Afis(int k)
{
for(int j = 1 ; j <= k ; j ++)
cout << x[j] << " ";
cout << endl;
}
void back(int k){
for(int i = 1 ; i <= n ; ++ i)
if(uz[i] == 0)
{
x[k] = i;
uz[i] = 1;
if(k == n)
Afis(k);
else
back(k + 1);
uz[i] = 0;
}
}
int main(){
cin >> n;
back(1);
return 0;
}
Probleme propuse
Permutari Permutari1 Permutari2 SirPIE Anagrame1 PermPF Shuffle
Citește și
Factorial
În matematică factorialul unui număr întreg pozitiv n este notat cu n! și este egal cu produsul numerelor naturale mai mici sau egale cu n. Prin definiție, 0!=1.
Factorialul unui număr oarecare n indică numărul de permutări (numărul de posibilități de rearanjare) ale unei mulțimi finite având n elemente.
Definiții
Factorialul poate fi definit:
- iterativ: \( n! = 1 \cdot 2 \cdot 3 \cdot \cdots \cdot n \), \(0!=1\)
- recursiv: \( n! = \begin{cases}
1& \text{dacă } n = 0 ,\\
n \cdot (n-1)! & \text{altfel}.
\end{cases} \)
Observații
Obs. 1: Factorialul crește foarte repede. Pentru valori mici ale lui n, valoarea lui n! depășește tipurile de date standard:
0! = 1 1! = 1 2! = 2 3! = 6 4! = 24 5! = 120 6! = 720 7! = 5040 8! = 40320 9! = 362880 10! = 3628800 11! = 39916800 12! = 479001600 13! = 6227020800 -> depaseste tipul int 14! = 87178291200 15! = 1307674368000 16! = 20922789888000 17! = 355687428096000 18! = 6402373705728000 19! = 121645100408832000 20! = 2432902008176640000 21! = 51090942171709440000 -> depaseste tipul long long int
Obs. 2: Pentru n≥5, ultima cifră a lui n! este 0.
Cifra 0 de la finalul unui produs, provine din 2*5. Numărul de zerouri de la finalul unui este egal cu minimul dintre exponentul lui 2 și exponentul lui 5 în descompunerea în factori prim a produsului, aceasta obținându-se din descompunerea în factori prim a fiecărui factor. În cazul lui n!, numărul de zerouri de la final este egal cu exponentul lui 5 în descompunerea în factori. El poate fi determinat astfel:
Obs. 3: Numărul de zerouri de la finalul lui n! este egal cu \( [\frac {n}{5}] + [\frac {n}{5^2}] + [\frac {n}{5^3}] + \cdots\ + [\frac {n}{5^k}] + \cdots \), unde \( [x] \) reprezintă partea întreagă a numărului real \( x \). Pentru \( k \) suficient de mare \( 5^k > n\) și \( [\frac {n}{5^k}] \) devine 0.
O sursă C++ care determină rezultatul este:
#include <iostream>
using namespace std;
int main()
{
int n, p = 5, s = 0;
cin >> n;
while(p <= n)
s += n / p, p *= 5;
cout << s;
return 0;
}
Observația de mai sus este o consecință a:
Obs. 4: Pentru un n dat și un număr prim p, exponentul lui p în descompunerea în factori primi a lui n! este \( [\frac {n}{p}] + [\frac {n}{p^2}] + [\frac {n}{p^3}] + \cdots\ + [\frac {n}{p^k}] + \cdots \), rezultat cunoscut ca formula lui Legendre.
O scriere alternativă este dată în următoarea observație:
Obs. 5: Pentru un n dat și un număr prim p, exponentul lui p în descompunerea în factori primi a lui n! este \( \frac {n-s_{p}(n)}{p-1}\), unde \( s_{p}(n)\) reprezintă suma cifrelor reprezentării în baza p a numărului n.
Pentru mai multe informații, vizitați pagina Factorial – Wikipedia.

Triunghiul lui Pascal
Triunghiul lui Pascal este un tablou triunghiular cu numere naturale, în care fiecare element aflat pe laturile triunghiului are valoarea 1, iar celelalte elemente sunt egale cu suma celor două elemente vecine, situate pe linia de deasupra.
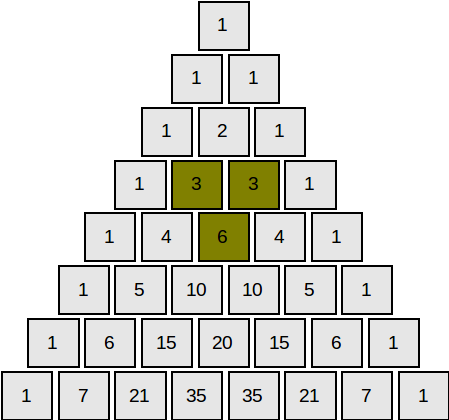
Proprietăți
Putem rearanja elementele tabloului astfel:
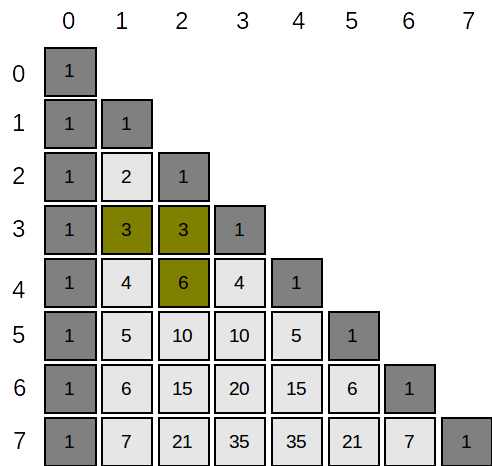
Considerând liniile și coloanele numerotate ca mai sus atunci: \( A_{i,j} = \begin{cases}
1& \text{dacă } i = j \text{ sau } j = 0,\\
A_{i-1,j-1 } + A_{i-1, j} & \text{altfel}.
\end{cases} \). De fapt, această relație este cunoscută în calculul combinărilor: \( {C^{k}_{n}} = \begin{cases}
1& \text{dacă } n = k \text{ sau } k = 0,\\
{ C^{k-1}_{n-1} } + { C^{k}_{n-1} } & \text{altfel}.
\end{cases} \), unde \(C^{k}_{n}\) înseamnă “combinări de n luate câte k”. De fapt, un element \(A_{i,j}\) al tabloului de mai sus este egal cu \( {C^{j}_{i}} \).
Elementele de pe linia n sunt coeficienți binomiali ai dezvoltării \( (a+b)^n = C^{0}_{n} \cdot a^n + C^{1}_{n} \cdot a^{n-1} \cdot b^1 + C^{2}_{n} \cdot a^{n-2} \cdot b^2 + \cdots + C^{k}_{n} \cdot a^{n-k} \cdot b^k + \cdots + C^{n-1}_{n} \cdot a^{1} \cdot b^{n-1} + C^{n}_{n} \cdot b^{n} \) – binomul lui Newton.
Suma elementelor de pe linia n este egală cu 2n: \( {C^{0}_{n}} + {C^{1}_{n}} + {C^{2}_{n}} + \cdots + {C^{k}_{n}} + \cdots + {C^{n}_{n}} = 2^n \).

Problemă
Se citește un număr natural n. Afișați linia n din triunghiul lui Pascal.
Soluție cu combinări
O primă soluție constă în calcularea valorii \( C^{k}_{n} \) pentru fiecare \( k \in \left\{0, 1, 2, \cdots , \ n \right\} \).
#include <iostream>
using namespace std;
int comb(int n , int k)
{
int p = 1;
for(int i = 1 ; i <= k ; i ++)
p = p * (n-i+1) / i;
return p;
}
int main()
{
int n;
cin >> n;
for(int i = 0 ; i <= n ; i ++)
cout << comb(n,i) << " ";
return 0;
}
O îmbunătățire a variantei de mai sus este:
#include <iostream>
using namespace std;
int main()
{
int n;
cin >> n;
int p = 1;
cout << "1 ";
for(int i = 1 ; i <= n ; i ++)
{
p = p * (n-i+1) / i;
cout << p << " ";
}
return 0;
}
Soluție cu matrice
În soluția următoare aplicăm formula \( A_{i,j} = A_{i-1,j-1 } + A_{i-1, j} \), folosind un tablou unidimensional:
#include <iostream>
using namespace std;
int main()
{
int n, A[31][31];
cin >> n;
for(int i = 0 ; i <= n ; i ++)
{
A[i][0] = A[i][i] = 1;
for(int j = 1 ; j < i ; j ++)
A[i][j] = A[i-1][j-1] + A[i-1][j];
}
for(int j = 0 ; j <= n ; j ++)
cout << A[n][j] << " ";
return 0;
}
Soluție cu doi vectori
Soluția de mai sus poate fi îmbunătățită, observând că pentru a calcula linia curentă folosim doar linia precedentă. Vom folosi doar doi vectori, unul pentru linia curentă, celălalt pentru linia precedentă:
#include <iostream>
using namespace std;
int main()
{
int n, v[31],u[31];
cin >> n;
v[0] = 0;
for(int i = 1 ; i <= n ; i ++)
{
u[0] = u[i] = 1;
for(int j = 1 ; j < i ; j ++)
u[j] = v[j-1] + v[j];
for(int j = 0 ; j <= i ; j ++)
v[j] = u[j];
}
for(int j = 0 ; j <= n ; j ++)
cout << v[j] << " ";
return 0;
}
Soluție cu doi vectori și doi pointeri
În soluția de mai sus putem evita copierea elementelor din u în v, folosind doi pointeri suplimentari. Aceștia vor memora adresa de început a celor două tablouri, iar copierea elementelor este înlocuită de interschimbarea valorilor celor doi pointeri:
#include <iostream>
using namespace std;
int main()
{
int n, A[31], B[31];
int * u = A, * v = B;
cin >> n;
v[0] = 0;
for(int i = 1 ; i <= n ; i ++)
{
u[0] = u[i] = 1;
for(int j = 1 ; j < i ; j ++)
u[j] = v[j-1] + v[j];
swap(u,v);
}
for(int j = 0 ; j <= n ; j ++)
cout << v[j] << " ";
return 0;
}
Soluție cu un singur vector
Putem folosi un singur vector. Acesta conține linia anterioară și se modifică pas cu pas, pentru a deveni linia curentă a triunghiului:
#include <iostream>
using namespace std;
int main()
{
int n, v[31];
cin >> n;
v[0] = 0;
for(int i = 1 ; i <= n ; i ++)
{
v[i] = 1;
for(int j = i - 1 ; j > 0 ; j --)
v[j] = v[j] + v[j-1];
v[0] = 1;
}
for(int j = 0 ; j <= n ; j ++)
cout << v[j] << " ";
return 0;
}Model concurs Mate-Info UBB, 2018
Varianta originală a acestui material este disponibilă aici: http://www.cs.ubbcluj.ro/wp-content/uploads/Model-Informatica-Concurs-Mate-Info-UBB-2019-RO.pdf.
În atenția concurenților:
- Se consideră că indexarea șirurilor începe de la 1.
- Problemele tip grilă (Partea A) pot avea unul sau mai multe răspunsuri corecte. Răspunsurile trebuie scrise de candidat pe foaia de concurs (nu pe foaia cu enunțuri). Obținerea punctajului aferent problemei este condiționată de identificarea tuturor variantelor de răspuns corecte și numai a acestora.
- Pentru problemele din Partea B se cer rezolvări complete pe foaia de concurs.
- Rezolvările se vor scrie în pseudocod sau într-un limbaj de programare (Pascal/C/C++).
- Primul criteriu în evaluarea rezolvărilor va fi corectitudinea algoritmului, iar apoi performanța din punct de vedere al timpului de executare și al spațiului de memorie utilizat.
- Este obligatorie descrierea și justificarea (sub) algoritmilor înaintea rezolvărilor. Se vor scrie, de asemenea, comentarii pentru a ușura înțelegerea detaliilor tehnice ale soluției date, a semnificației identificatorilor, a structurilor de date folosite etc. Neîndeplinirea acestor cerințe duce la pierderea a 10% din punctajul aferent subiectului.
- Nu se vor folosi funcții sau biblioteci predefinite (de exemplu: STL, funcții predefinite pe șiruri de caractere).
Partea A (60 puncte)
A.1. Oare ce face? (6 puncte)
Se consideră subalgoritmul alg(x, b) cu parametrii de intrare două numere naturale x și b (1 ≤ x ≤ 1000, 1 < b ≤ 10).
Subalgoritm alg(x, b):
s ← 0
CâtTimp x > 0 execută
s ← s + x MOD b
x ← x DIV b
SfCâtTimp
returnează s MOD (b - 1) = 0
SfSubalgoritm
Precizați efectul acestui subalgoritm.
A. calculează suma cifrelor reprezentării în baza b a numărului natural x
B. verifică dacă suma cifrelor reprezentării în baza b - 1 a numărului x este divizibilă cu b - 1
C. verifică dacă numărul natural x este divizibil cu b - 1
D. verifică dacă suma cifrelor reprezentării în baza b a numărului x este divizibilă cu b - 1
A.2. Ce se afișează? (6 puncte)
Se consideră următorul program:
int sum(int n, int a[], int s){
s = 0;
int i = 1;
while(i <= n){
if(a[i] != 0) s += a[i];
++i;
}
return s;
}
int main(){
int n = 3, p = 0, a[10];
a[1] = -1; a[2] = 0; a[3] = 3;
int s = sum(n, a, p);
cout << s << ”;“ << p; // printf("%d;%d", s, p);
return 0;
}
Care este rezultatul afișat în urma execuției programului?
A. 0;0
B. 2;0
C. 2;2
D. Niciun rezultat nu este corect
A.3. Expresie logică (6 puncte)
Se consideră următoarea expresie logică (X OR Z) AND (NOT X OR Y). Alegeți valorile pentru X , Y , Z astfel încât
evaluarea expresiei să dea rezultatul TRUE:
A. X ← FALSE; Y ← FALSE; Z ← TRUE;
B. X ← TRUE; Y ← FALSE; Z ← FALSE;
C. X ← FALSE; Y ← TRUE; Z ← FALSE;
D. X ← TRUE; Y ← TRUE; Z ← TRUE;
A.4. Calcul (6 puncte)
Fie subalgoritmul calcul(a, b) cu parametrii de intrare a și b numere naturale, 1 ≤ a ≤ 1000, 1 ≤ b ≤ 1000.
1. Subalgoritm calcul(a, b): 2. Dacă a ≠ 0 atunci 3. returnează calcul(a DIV 2, b + b) + b * (a MOD 2) 4. SfDacă 5. returnează 0 6. SfSubalgoritm
Care din afirmațiile de mai jos sunt false?
A. dacă a și b sunt egale, subalgoritmul returnează valoarea lui a
B. dacă a = 1000 și b = 2, subalgoritmul se autoapelează de 10 ori
C. valoarea calculată și returnată de subalgoritm este a / 2 + 2 * b
D. instrucțiunea de pe linia 5 nu se execută niciodată
A.5. Identificare element (6 puncte)
Se consideră șirul (1, 2, 3, 2, 5, 2, 3, 7, 2, 4, 3, 2, 5, 11, ...) format astfel: plecând de la șirul numerelor naturale, se
înlocuiesc numerele care nu sunt prime cu divizorii lor proprii, fiecare divizor d fiind considerat o singură dată pentru
fiecare număr. Care dintre subalgoritmi determină al n-lea element al acestui șir (n – număr natural, 1 ≤ n ≤ 1000)?
A.
Subalgoritm identificare(n):
a ← 1, b ← 1, c ← 1
CâtTimp c < n execută
a ← a + 1, b ← a, c ← c + 1, d ← 2
f ← false
CâtTimp c ≤ n și d ≤ a DIV 2 execută
Dacă a MOD d = 0 atunci
c ← c + 1, b ← d, f ← true
SfDacă
d ← d + 1
SfCâtTimp
Dacă f atunci
c ← c - 1
SfDacă
SfCâtTimp
returnează b
SfSubalgoritm
B.
Subalgoritm identificare(n):
a ← 1, b ← 1, c ← 1
CâtTimp c < n execută
c ← c + 1, d ← 2
CâtTimp c ≤ n și d ≤ a DIV 2 execută
Dacă a MOD d = 0 atunci
c ← c + 1, b ← d
SfDacă
d ← d + 1
SfCâtTimp
a ← a + 1, b ← a
SfCâtTimp
returnează b
SfSubalgoritm
C.
Subalgoritm identificare(n):
a ← 1, b ← 1, c ← 1
CâtTimp c < n execută
a ← a + 1, d ← 2
CâtTimp c < n și d ≤ a execută
Dacă a MOD d = 0 atunci
c ← c + 1, b ← d
SfDacă
d ← d + 1
SfCâtTimp
SfCâtTimp
returnează b
SfSubalgoritm
D.
Subalgoritm identificare(n):
a ← 1, b ← 1, c ← 1
CâtTimp c < n execută
b ← a, a ← a + 1, c ← c + 1, d ← 2
CâtTimp c ≤ n și d ≤ a DIV 2 execută
Dacă a MOD d = 0 atunci
c ← c + 1, b ← d
SfDacă
d ← d + 1
SfCâtTimp
SfCâtTimp
returnează b
SfSubalgoritm
A.6. Factori primi (6 puncte)
Fie subalgoritmul factoriPrimi(n, d, k, x) care determină cei k factori primi ai unui număr natural n, începând căutarea factorilor primi de la valoarea d. Parametrii de intrare sunt numerele naturale n, d și k, iar parametrii de ieșire sunt șirul x cu cei k factori primi (1 ≤ n ≤ 10000, 2 ≤ d ≤ 10000, 0 ≤ k ≤ 10000).
Subalgoritm factoriPrimi(n, d, k, x):
Dacă n MOD d = 0 atunci
k ← k + 1
x[k] ← d
SfDacă
CâtTimp n MOD d = 0 execută
n ← n DIV d
SfCâtTimp
Dacă n > 1 atunci
factoriPrimi(n, d + 1, k, x)
SfDacă
SfSubalgoritm
Stabiliți de câte ori se autoapelează subalgoritmul factoriPrimi(n, d, k, x) prin execuția următoarei secvențe de instrucțiuni:
n ← 120 d ← 2 k ← 0 factoriPrimi(n, d, k, x)
A. de 3 ori
B. de 5 ori
C. de 9 ori
D. de același număr de ori ca și în cadrul secvenței de instrucțiuni:
n ← 750 d ← 2 k ← 0 factoriPrimi(n, d, k, x)
A.7. Oare ce face? (6 puncte)
Se consideră subalgoritmul expresie(n) , unde n este un număr natural (1 ≤ n ≤ 10000).
Subalgoritm expresie(n):
Dacă n > 0 atunci
Dacă n MOD 2 = 0 atunci
returnează -n * (n + 1) + expresie(n - 1)
altfel
returnează n * (n + 1) + expresie(n - 1)
SfDacă
altfel
returnează 0
SfDacă
SfSubalgoritm
Precizați forma matematică a expresiei \( E(n) \) calculată de acest subalgoritm:
A. \( E(n) = 1 \cdot 2 – 2 \cdot 3 + 3 \cdot 4 + … + (-1)^{n+1} \cdot n \cdot (n + 1) \)
B. \( E(n) = 1 \cdot 2 – 2 \cdot 3 + 3 \cdot 4 + … + (-1)^{n} \cdot n \cdot (n + 1) \)
C. \( E(n) = 1 \cdot 2 + 2 \cdot 3 + 3 \cdot 4 + … + (-1)^{n+1} \cdot n \cdot (n + 1) \)
D. \( E(n) = 1 \cdot 2 + 2 \cdot 3 + 3 \cdot 4 + … + (-1)^{n} \cdot n \cdot (n + 1) \)
A.8. Expresie logică (6 puncte)
Se consideră următoarea expresie logică: (NOT Y OR Z) OR (X AND Y). Alegeți valorile pentru X , Y , Z astfel încât rezultatul evaluării expresiei să fie adevărat:
A. X ← FALSE; Y ← FALSE; Z ← FALSE;
B. X ← FALSE; Y ← FALSE; Z ← TRUE;
C. X ← FALSE; Y ← TRUE; Z ← FALSE;
D. X ← TRUE; Y ← FALSE; Z ← TRUE;
A.9. Valori ale parametrului de intrare (6 puncte)
Se consideră următorul subalgoritm:
Subalgoritm SA9(a):
Dacă a < 50 atunci
Dacă a MOD 3 = 0 atunci
returnează SA9(2 * a - 3)
altfel
returnează SA9(2 * a - 1)
SfDacă
altfel
returnează a
SfDacă
SfSubalgoritm
Pentru care dintre valorile parametrului de intrare a subalgoritmul va returna valoarea 61?
A. 16
B. 61
C. 4
D. 31
A.10. Instrucțiuni lipsă (6 puncte)
Se dă următorul subalgoritm:
1: Subalgoritm cautare(x, n, val): 2: Dacă n = 1 atunci 3: returnează (x[1] = val) 4: altfel 5: returnează cautare(x, n - 1, val) 6: SfDacă 7: SfSubalgoritm
Ce instrucțiune sau instrucțiuni trebuie adăugate și unde astfel încât în urma apelului, subalgoritmul cautare(x, n, val) să determine dacă elementul val face sau nu parte din șirul x cu n elemente (n număr natural strict mai mare ca zero)?
A. Linia 5 trebuie modificată în: returnează ((x[n] = val) și cautare(x - 1, n, val))
B. Linia 5 trebuie modificată în: returnează ((x[n] = val) sau cautare(x, n - 1, val))
C. Linia 5 trebuie modificată în: dacă (x[n] = val) atunci returnează true altfel returnează cautare(x, n - 1, val)
D. nu trebuie modificată nici o instrucțiune
Partea B (30 puncte)
1. Prefix (15 puncte)
Cifra de control a unui număr natural se determină calculând suma cifrelor numărului, apoi suma cifrelor sumei și așa
mai departe până când suma obținută reprezintă un număr cu o singură cifră. De exemplu, cifra de control a numărului
182 este 2 (1 + 8 + 2 = 11, 1 + 1 = 2).
Un număr p format din exact k cifre este prefix al unui număr q cu cel puțin k cifre dacă numărul format din primele k
cifre ale numărului q (parcurse de la stânga la dreapta) este egal cu p. De exemplu, 17 este prefix al lui 174, iar 1713
este prefix al lui 1713242.
Se consideră un număr nr natural (0 < nr ≤ 30000) și o matrice (un tablou bidimensional) A cu m linii și n coloane (0 <
m ≤ 100, 0 < n ≤ 100), având ca elemente numere naturale mai mici decât 30000. Se consideră și subalgoritmul cifrăControl(x) pentru determinarea cifrei de control asociată numărului x:
Subalgoritm cifraControl(x):
s ← 0
CâtTimp x > 0 execută
s ← s + x MOD 10
x ← x DIV 10
Dacă x = 0 atunci
Dacă s < 10 atunci
Returnează s
altfel
x ← s
s ← 0
SfDacă
SfDacă
SfCâtTimp
returnează s
SfSubalgoritm
Cerințe:
a. Scrieți o variantă recursivă (fără structuri repetitive) a subalgoritmului cifrăControl(x) care are același antet și același efect cu acesta. (5 puncte)
b. Scrieți modelul matematic al variantei recursive a subalgoritmului cifrăControl(x) (dezvoltat la punctul a). (3 puncte)
c. Scrieți un subalgoritm care, folosind subalgoritmul cifrăControl(x), determină cel mai lung prefix (notat prefix) al numărului nr care se poate construi folosind cifrele de control corespunzătoare elementelor din matricea dată. O astfel de cifră de control poate fi folosită de oricâte ori în construirea prefixului. Dacă nu se poate construi un prefix, prefix va fi -1. Parametrii de intrare ai subalgoritmului sunt numerele nr, m, n, matricea A, iar parametrul de ieșire este prefix. (7 puncte)
Exemplu: dacă avem nr = 12319, m = 3 și n = 4 și matricea \( A = \begin{bmatrix}182 & 12 & 274 & 22 \\ 22 & 1 & 98 & 56 \\ 5 & 301 & 51 & 94 \end{bmatrix} \), cel mai lung prefix este prefix = 1231, cifrele de control fiind:
| Element din matrice | 182 | 12 | 274 | 22 | 1 | 98 | 56 | 5 | 301 | 51 | 94 |
| Cifră control | 2 | 3 | 4 | 4 | 1 | 8 | 2 | 5 | 4 | 6 | 4 |
2. Robi-grădina (15 puncte)
Un grădinar pasionat de tehnologie decide să folosească o „armată” de roboți pentru a uda straturile din grădina sa. El dorește să folosească apă de la izvorul situat la capătul cărării principale care străbate grădina. Fiecărui strat îi este asociat un robot și fiecare robot are de udat un singur strat. Toți roboții pornesc de la izvor în misiunea de udare a straturilor la aceeași oră a dimineții (spre exemplu 5:00:00) și lucrează în paralel și neîncetat un același interval de timp. Ei parcurg cărarea principală până la stratul lor, pe care îl udă și revin la izvor pentru a-și reumple rezervorul de apă. La finalul intervalului de timp aferent activității, toți roboții se opresc simultan, indiferent de starea lor curentă. Inițial, la izvor este amplasat un singur robinet. Grădinarul constată însă că apar întârzieri în programul de udare a plantelor deoarece roboții trebuie să aștepte la rând pentru reumplerea rezervoarelor cu apă, astfel încât consideră că cea mai bună soluție este să instaleze mai multe robinete pentru alimentarea roboților. Roboții pornesc dimineața cu rezervoarele umplute. Doi roboți nu își pot umple rezervorul în același moment de la același robinet.
Se cunosc: intervalul de timp t cât cei n roboți lucrează (exprimat în secunde), numărul de secunde di necesare pentru a parcurge distanța de la izvor la stratul asociat, numărul de secunde ui necesar pentru udarea acestui strat și faptul că umplerea rezervorului propriu cu apă durează exact o secundă pentru fiecare robot (t, n, di , ui – numere naturale, 1 ≤ t ≤ 20000, 1 ≤ n ≤ 100, 1 ≤ di ≤ 1000, 1 ≤ ui ≤ 1000, i = 1, 2, ..., n).
Cerințe:
a. Enumerați roboții care se întâlnesc la izvor la un anumit moment de timp mt (1 ≤ mt ≤ t). Justificați răspunsul.
Notă: roboții se identifică prin numărul lor de ordine. (3 puncte)
b. Care este numărul minim de robinete suplimentare minRobineteSuplim pe care trebuie să le instaleze grădinarul astfel încât roboții să nu aștepte deloc unul după altul pentru reumplerea rezervorului? Justificați răspunsul. (2 puncte)
c. Scrieți un subalgoritm care determină numărul minim de robinete suplimentare minRobineteSuplim. Parametrii de intrare sunt numerele n și t, șirurile d și u cu câte n elemente fiecare, iar parametrul de ieșire este minRobineteSuplim. (10 puncte)
Exemplu 1: dacă t = 32, n = 5, d = (1, 2, 1, 2, 1), u = (1, 3, 2, 1, 3) atunci minRobineteSuplim = 3. Explicație: robotul care se ocupă de stratul 1 are nevoie de o secundă pentru a ajunge la strat, o secundă pentru a uda stratul și de încă o secundă pentru a se întoarce la izvor; el se întoarce la izvor pentru a-și reumple rezervorul după 1 + 1 + 1 = 3 secunde de la ora de plecare (5:00:00), deci la ora 5:00:03; el își reumple rezervorul într-o secundă și pornește înapoi spre strat la ora 5:00:04; revine la ora 5:00:07 pentru a-și reumple rezervorul, continuând ritmul de udare a straturilor, ș.a.m.d.; deci, primul, al doilea, al patrulea și al cincilea robot se întâlnesc la izvor la ora 05:00:23; în consecință, este nevoie de 3 robinete suplimentare.
Exemplu 2: dacă t = 37, n = 3, d = (1, 2, 1), u = (1, 3, 2), atunci minRobineteSuplim = 1.

MySQL
![]() MySQL este cel mai popular sistem de gestiune a bazelor de date open-source, şi unul dintre cele mai performante SGBD existente în prezent.
MySQL este cel mai popular sistem de gestiune a bazelor de date open-source, şi unul dintre cele mai performante SGBD existente în prezent.
Este un server de baza de date SQL robust, rapid, multi-threaded (utilizează fire de execuţie concurente), şi multi-user (permite deservirea simultană a mai multor utilizatori). Aceste calităţi îl recomandă ca back-end pentru aplicaţiile Web dinamice.
Există numeroase interfeţe de acces la bazele date MySQL din diverse limbaje de programare: C/C++, Java, PHP, precum şi aplicaţii numeroase aplicaţii client – care permit conectarea la server şi rularea de comenzi pe acesta.