Articolele lui
 Candale Silviu (silviu)
Candale Silviu (silviu)
Elemente de combinatorică
Analiza combinatorică este un domeniu al matematicii care studiază modalitățile de numărare ale elementelor mulțimilor finite, precum și de alegere și aranjare a lor. Numeroase concepte specifice acestui domeniu intervin și în probleme de algoritmică.
Produsul cartezian
Fie \( n \in \mathbb{N} \) și mulțimile \(A_1\), \(A_2\)., …, \(A_n\). Produsul cartezian \( A_1 \times A_2 \times … \times A_n \) este mulțimea \(n\)-uplurilor \(\left(x_1,x_2,…,x_n\right)\) cu proprietatea că \(x_1 \in A_1\), \(x_2 \in A_2\), …, \(x_n \in A_n\).
Regula produsului: Dacă mulțimile \(A_1\), \(A_2\)., …, \(A_n\) au respectiv \(k_1\), \(k_2\)., …, \(k_n\) atunci numărul de elemente al produsului cartezian \( A_1 \times A_2 \times … \times A_n \) este \(k_1 \cdot k_2 \cdot … \cdot k_n\).
Submulțimile unei multimi
Fie \(A\) o mulțimi cu n elemente. Atunci ea are \(2^n\) submulțimi:
Exemplu: Mulțimea \(A={1,2,3}\) are \(2^3 = 8\) submulțimi:
- \( \emptyset \)
- \(\left\{1\right\}\), \(\left\{ 2 \right\}\), \(\left\{ 3 \right\}\)
- \(\left\{1,2\right\}\), \(\left\{1,3\right\}\), \(\left\{2,3\right\}\)
- \(\left\{1,2,3\right\}\)
Permutări
Se numește permutare o corespondență biunivocă (bijecție) între o mulțime finită și ea însăși.
Altfel spus, se numește permutare a unei mulțimi finite o aranjare a elementelor sale într-o anumită ordine.
Exemplu: permutările mulțimii {1,2,3} sunt: (1,2,3), (1,3,2), (2,1,3), (2,3,1), (3,1,2) și (3,2,1). Într-o altă reprezentare, acestea sunt:
\( \begin{pmatrix} 1 & 2 & 3 \\ 1 & 2 & 3 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 1 & 3 & 2 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 2 & 1 & 3 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 2 & 3 & 1 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 3 & 1 & 2 \end{pmatrix} \), \( \begin{pmatrix} 1 & 2 & 3 \\ 3 & 2 & 1 \end{pmatrix} \)
Dacă \( \sigma = \begin{pmatrix} 1 & 2 & 3 \\ 3 & 1 & 2 \end{pmatrix} \), atunci \( \sigma(1) = 3 \), \( \sigma(2) = 1 \) și \( \sigma(3) = 2 \).
Numărul de permutări al unei mulțimi cu \(n\) elemente este \( P_n = n! = 1 \cdot 2 \cdot \cdot … \cdot n\). Acest articol conține mai multe despre factorialul unui număr.
Numărul permutărilor unei mulțimi crește foarte repede. Pentru valori mici ale lui n, numărul permutărilor depășește domeniul de valori al datelor întregi, fiind necesară implementarea operațiilor pe numere mari.
Permutări cu repetiție
Considerăm un set de \(n\) obiecte de \(k\) tipuri. Avem \(n_1\) obiecte de tipul 1, \(n_2\) obiected e tipul 2, …, \(n_k\) obiecte de tipul k și \(n_1 + n_2 + … + n_k = n\). Numărul de permutări distincte ale celor n obiecte este:
$$ P_R(n) = \frac{n ! }{n_1 ! \cdot n_2 ! \cdot … \cdot n_k !} $$
Exemplu: Numărul de anagrame distincte ale cuvântului ABABA este:
$$ P_R(2+3) = \frac{(2+3) ! }{ 2 ! \cdot 3 ! } = \frac{1 \cdot 2 \cdot 3 \cdot 4 \cdot 5}{1 \cdot 2 \cdot 1 \cdot 2 \cdot 3} = 10 $$
Acestea sunt: AAABB, AABAB, AABBA, ABAAB, ABABA, ABBAA, BAAAB, BAABA, BABAA, BBAAA.
Aranjamente
Dacă A este o mulțime cu n elemente, submulțimile ordonate cu k elemente ale lui A, 0 ≤ k ≤ n se numesc aranjamente a n elemente luate câte k.
Numărul de aranjamente de \(n\) luate câte \(k\) se notează \( A_{n}^{k} = n \cdot (n-1) \cdot (n-2) \cdot … \cdot (n-k+1) = \frac{ n! }{(n-k)!} \).
La fel ca în cazul permutărilor, pentru determinarea numărului de aranjamente poate fi necesară implementarea operațiilor pe numere mari.
Combinări
Pentru o mulțime dată o combinare reprezintă o modalitate de alegere a unor elemente, fără a ține cont de ordinea lor. Se numesc combinări de k elemente submulțimile cu k elemente ale mulțimii, presupuse cu n elemente. Numărul de asemenea submulțimi se numește combinări de n luate câte k și se notează \(C_n^k\).
Formule:
- \(C_n^k = \frac{A_n^k}{P_k}\)
- \(C_n^k = \frac{n \cdot (n-1) \cdot … \cdot (n-k+1)}{1 \cdot 2 \cdot … \cdot k}\)
- \(C_n^k = \frac{n!}{k!\cdot {(n-k)!}} \)
- \(C_n^k= \begin{cases}
1& \text{dacă } k = 0,\\
\frac{n – k + 1}{k} \cdot { C_n^k } & \text{altfel}.
\end{cases} \) - \(C_n^k= \begin{cases}
1& \text{dacă } n = k \text{ sau } k = 0,\\
{ C_{n-1}^{k-1} } + { C_{n-1}^k } & \text{altfel}.
\end{cases} \); această formulă se regăsește în Triunghiul lui Pascal
Numerele lui Catalan
Termenul general al acestui șir este:
$$ C_n = C_{2n}^{n} – C_{2n}^{n+1} = \frac{1}{n+1}\cdot C_{2n}^{n} = \prod _{k=2}^{n} \frac{n+k}{k}, \text{pentru } n ≥ 0 $$
O formulă recursivă:
$$ C_{n+1} = \sum_{i=0}^{n}{C_i \cdot C_{n-i}} $$
Pentru \(n=0,1,2,3,…\) numere Catalan sunt: \( 1, 1, 2, 5, 14, 42, 132, 429, 1430, 4862, … \).
Există numeroase probleme care au ca rezultat numerele lui Catalan. Amintim:
- \(C_n\) este egal cu numărul de șiruri de
nparanteze deschise șinparanteze închise care se închid corect. Pentrun=3, avem \(C_3 = 5\) variante:((())),(())(),()(()),()()()și(()()). - numărul de cuvinte Dyck de lungime
2*n: formate dinncaractereXșincaractereYși în orice prefix umărul deXeste mai mare sau egal cu numărul deY. Pentrun=3:XXXYYY,XXYYXY,XYXXYY,XYXYXY,XXYXYY. - numărul de șiruri formate din
nde1șinde-1astfel încât toate sumele parțiale să fie nenegative. - \(C_n\) reprezintă numărul de modalități de a paranteza o expresie formată din
n+1operanzi ai unei operatii asociative:((ab)c)d,(a(bc))d,(ab)(cd),a((bc)d),a(b(cd)). - \(C_n\) reprezintă numărul de modalităti de a desena “șiruri de munți” cu
nlinii crescătoare șinlinii descrescătoare. Munții încep și se termină la același nuvel și nu coboară sub acel nivel:
/\
/\ /\ /\/\ / \
/\/\/\ / \/\ /\/ \ / \ / \
- numărul de drumuri laticiale de la punctul
(0,0)la(2*n,0)cu pași din{(1,1),(1,-1)care nu coboară sub axaOx. - \(C_n\) este numărul de modalități de a triangula un poligon cu
n+2laturi:

- \(C_n\) este umărul de drumuri laticiale de la
(0,0)la(n,n)cu pași din{(0,1),(1,0)}care nu depășesc prima diagonală \(y = x\). Următoarea imagine conține drumurile pentrun=4:

- numărul de siruri \( 1 \leqslant a_1 \leqslant a_2 \leqslant … \leqslant a_n \) cu proprietatea că \(a_k \leqslant k \) este \(C_n\).
- \(C_n\) numărul de modalități de a acoperi o scară cu
ntrepte folosindndreptunghiuri. Pentrun=4:

- pe un cerc sunt
2*npuncte. Numărul posibilități de a desenancoarde care nu se intersectează este \(C_n\).
Alte probleme care au care rezultat numărul lui Catalan sunt pe Wikipedia sau în documentul Exercises on Catalan and Related Numbers, Cambridge University Press, Richard P_ Stanley, June 1998.
Partițiile unei mulțimi
Fie \(A={a_1, a_2, …, a_n}\) o mulțime (finită). Se numește partiție a mulțimii \(A\) o familie de submulțimi \(A_1, A_2, …, A_k\) ale lui \(A\) cu proprietățile:
- \( A_i \subseteq A \), \( \forall i = \overline{1,k} \)
- \( A_1 \cup A_2 \cup … \cup A_k = A \)
- \( A_i\cap A_j = \emptyset \), \( \forall i\neq j \)
De exemplu, \(A={1,2,3}\) are următoarele partiții:
- \({1,2,3}\)
- \({1,2},{3}\), \({1,3},{2}\), \({1}, {2,3}\)
- \({1},{2},{3}\)
Numărul de partiții cu \(k\) submulțimi ale unei mulțimi cu \(n\) elemente se numește numărul lui Stirling de speța a doua, notat \(S(n,k)\). El respectă următoarea relație de recurență:
$$ \begin{cases} S(0,0) = 1\\
S(0,n) = S(n,0) = 0\\
S(n+1,k) = k \cdot S(n,k) + S(n,k-1) & \text{pentru } k > 0 \end{cases}
$$
Numerele Strirling de speța a doua pe Wikipedia
Numărul total de partiții ale unei mulțimi cu \(n\) elemente este numărul lui Bell: $$B_n = \sum_{k=0}^n S(n,k)$$
Începând cu \(B_0 = B_1 = 1\), primele numere Bell sunt: \(1, 1, 2, 5, 15, 52, 203, 877, 4140, … \).
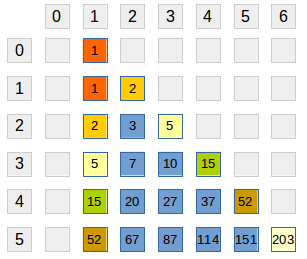
Numerele Bell pot fi construite cu ajutorul așa-numitului triunghi Bell. Vom construi (parțial) un tablou A[][]:
A[0][1] = 1- primul element de pe liniile următoare este egal cu ultimul de pe linia precedentă:
A[i][1] = A[i-1][i] - celelalte elemente ale fiecărei linii sunt egale cu suma celor după elemnte din stânga (linia curentă și linia precedentă):
A[i][j] = A[i][j-1] + A[i-1][j-1], pentruj=2,..., i+1 - primul elelemt de pe fiecare linie este numărul Bell corespunzător:
Bn=A[n][1].
 Candale Silviu (silviu)
Candale Silviu (silviu) Secvențe Escape
Secvențele escape au fost folosite inițial în limbajele C/C++; în prezent sunt folosite în numeroase alte limbaje, precum Java, C# sau PHP. Ele sunt succesiuni de caractere care cu alt înțeles decât cel direct atunci când sunt folosite într-un literal caracter sau șir de caractere, fiind înlocuite cu caractere care nu ar putea fi folosite în mod direct.
Toate secvențele escape încep cu caracterul \ – numit caracter escape și conțin două sau mai multe caractere. Cele care urmează după \ definește caracterul care va apărea în constanta literal. De exemplu, \n este o secvență escape care reprezintă caracterul newline – trecere la rând nou.
De ce sunt necesare?
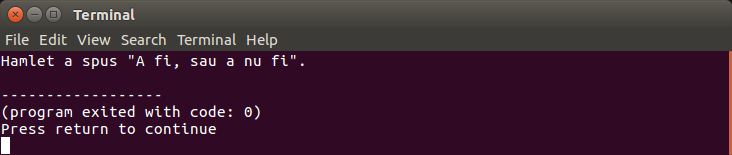
Să scriem un program care să afișeze pe ecran textul Hamlet a spus "A fi, sau a nu fi". – atenție la ghilimelele! După cum știm, un literal de tip șir de caractere este delimitat cu caracterul ghilimele ", deci ar trebui să folosim o instrucțiune C++ de felul următor:
cout << "Hamlet a spus "A fi, sau a nu fi".";
Această instrucțiune este însă greșită: compilatorul identifică șirul "Hamlet a spus ", iar șirul A fi, sau a nu fi nu are înțeles sintactic! Pentru a fi corect vom folosi pentru caracterul " din șir o secvență escape, adică \":
cout << "Hamlet a spus \"A fi, sau a nu fi\".";
Mai sus, secvența escape \" este pentru caracterul " – acesta având alt înțeles pentru compilator.
Lista secvențelor escape
| _ Secvența escape | _ Cod ASCII | _ Caracter |
|---|---|---|
\a |
7 |
Alertă, Beep |
\b |
8 |
Backspace |
\e |
27 |
Escape |
\f |
12 |
Formfeed |
\n |
10 |
NewLine |
\r |
13 |
Carriage Return |
\t |
9 |
Tab orizontal |
\v |
11 |
Tab vertical |
\\ |
92 |
Backslash |
\" |
34 |
Ghilimele |
\' |
39 |
Apostrof |
\? |
63 |
Semn de întrebare |
\0 |
0 |
Caracterul nul, cu înțeles special în șirurile de caractere |
\nnn |
oricare | Caracterul cu codul egal cu valoarea octală nnn |
\xhh |
oricare | Caracterul cu codul egal cu valoarea hexazecimală hh |
Există de asemenea secvențe escape pentru reprezentarea caracterelor non ASCII.
Exemple
Utilizarea ghilimelelor într-un șir de caractere
#include <iostream>
using namespace std;
int main()
{
cout << "Hamlet a spus \"A fi, sau a nu fi\".";
return 0;
}
Trecerea la rând nou
#include <iostream>
using namespace std;
int main()
{
cout << "Vrei 10 la info?\nHai pe pbinfo";
return 0;
}

Secvența escape poate fi folosită într-un caracter (ex. '\n') sau într-un șir de caractere (ex. "\n"). Următoarele două programe acu același efect ca cel de mai sus:
#include <iostream>
using namespace std;
int main()
{
cout << "Vrei 10 la info?" << "\n" << "Hai pe pbinfo";
return 0;
}
#include <iostream>
using namespace std;
int main()
{
cout << "Vrei 10 la info?" << '\n' << "Hai pe pbinfo";
return 0;
}Eratostene și alte ciururi
Ciurul lui Eratostene este o metodă rapidă prin care stabilește despre fiecare număr natural mai mic sau egal cu un n dat dat este prim sau nu. Valoarea lui n trebuie să fie suficient de mică pentru a putea declara un tablou P cu n+1 elemente, un element P[k] având valoarea 1 dacă k este prim, respectiv valoarea 0 dacă k nu este prim.
Următoarea secvență C++ construiește tabloul P[]:
int P[n+1];
for(int i = 0 ; i <= n ; i ++)
P[i] = 1;
P[0] = P[1] = 0;
for(int i = 2 ; i * i <= n ; i ++)
if(P[i] == 1)
for(int j = 2 ; i * j <= n ; j ++)
P[i * j] = 0;
Ideea de mai sus poate fi utilizată pentru a determina diverse rezultate în care intervin divizorii unui număr, rezultate calculate pentru toate numerele mai mici sau egale cu n:
- numărul de divizori
- suma divizorilor
- cel mai mic divizor prim
- cel mai mare divizor prim
- indicatorul lui Euler
Numărul de divizori
- construim un vector
Nr[]. La final,Nr[x]va fi numărul de divizori ai luix; - inițializăm elementele vectorului
Nr[]cu0; - parcurgem vectorul și pentru fiecare element
Nr[i]mărim valorile elementelorNr[k], undek = i * jeste multiplu al luii– dacăieste divizor al luik, atunci trebuie numărat ca atare.
int Nr[DIM + 1];
for(int i = 1 ; i <= DIM ; i ++)
Nr[i] = 0;
for(int i = 1; i <= DIM ; i ++)
for(int j = 1 ; i * j <= DIM ; j ++)
Nr[i * j] ++;
OBS: Un număr x este prim dacă și numai dacă la final Nr[x] este egal cu 2.
Suma divizorilor
- construim un vector
S[]. La final,S[x]va reprezenta suma divizorilor luix; - inițializăm elementele vectorului
S[]cu0; - parcurgem vectorul și pentru fiecare element
S[i]mărim valorile elementelorS[k]cui, undek = i * jeste multiplu al luii– dacăieste divizor al luik, atunci trebuie adunat la suma divizorilor luik.
int S[DIM + 1];
for(int i = 1 ; i <= DIM ; i ++)
S[i] = 0;
for(int i = 1; i <= DIM ; i ++)
for(int j = 1 ; i * j <= DIM ; j ++)
S[i * j] += i;
OBS: Un număr x este prim dacă și numai dacă la final S[x] este egal cu x+1.
Cel mai mic/mare divizor prim
- construim un vector
M[]. La final,M[x]va reprezenta cel mai mic divizor (factor) prim al luix; - inițializăm elementele vectorului
M[x]cux– pentru numerele prime cel mai mic factor prim sunt ele însele; - parcurgem numerele începând de la
2și pentru fiecare număriprim (pentru careM[i] = i) modificăm, dacă este cazul, cel mai mic factor prim pentru toți multiplik = i * jluii.
int M[DIM + 1];
for(int i = 1 ; i <= DIM ; i ++)
M[i] = i;
for(int i = 2; i <= DIM ; i ++)
if(M[i] == i)
for(int j = 2 ; i * j <= DIM ; j ++)
if(M[i * j] == i * j)
M[i * j] = i;
OBS:
- Un număr
xeste prim dacă și numai dacă la finalM[x]este egal cux. - La parcurgerea multiplilor lui
i, vom modifica multiplulk = i * jnumai dacăM[k]este încăk. De exemplu, pentrui=3, nu-l mai modifică peM[6]– a fost deja modificat pentrui=2. - Dacă modificăm
M[k]de pentru fiecarei, deoareceieste considerat în ordine crescătoare, la finalM[k]va memora cel mai mare divizor prim al luik. Următoarea secvență obține acest rezultat – observați că modificările sunt minore:
int M[DIM + 1];
for(int i = 1 ; i <= DIM ; i ++)
M[i] = i;
for(int i = 2; i <= DIM ; i ++)
if(M[i] == i)
for(int j = 2 ; i * j <= DIM ; j ++)
M[i * j] = i;
Indicatorul lui Euler
Indicatorul lui Euler este tratat în acest articol. Reluăm aici numai secvența C/C++:
int F[DIM + 1];
for(int i =1 ; i <= DIM ; i ++)
F[i] = i;
for(int i = 2; i <= DIM ; i ++)
if(F[i] == i)
{
for(int j = 1 ; j * i <= DIM ; j ++)
F[j * i]= F[j * i] / i * (i - 1);
}
OBS: Un număr x este prim dacă și numai dacă la final F[x] este egal cu x-1.
Alte probleme
Încercați să determinați în același mod:
- numărul factorilor primi
- suma/produsul factorilor primi
- etc.
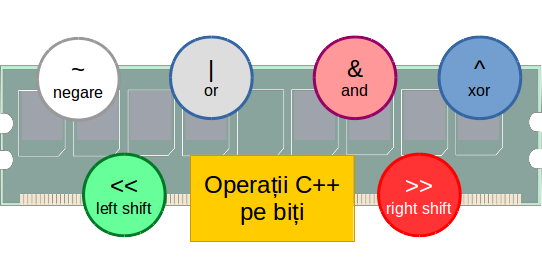
Aplicații ale operațiilor pe biți
Operațiile pe biți, descrise aici sunt foarte rapide și au o serie de aplicații utile în practică. Acesta articol prezintă o parte dintre ele, limbajul de programare folosit fiind C/C++.
Reamintim faptul că biții din reprezentarea internă a unui număr întreg se numerotează începând de la 0, de la dreapta spre stânga.
Înmulțirea cu puteri ale lui 2
Înmulțirea cu o puterea lui 2 se face foarte rapid cu operația de deplasare la stânga pe biți, <<. Astfel, a * 2k este egal cu a << k. Desigur, atenție la overflow!
Împărțirea cu puteri ale lui 2
Câtul împărțirii poate fi determina prin deplasarea la dreapta, >>. Astfel, a / 2k este egal cu a >> k.
Verificarea parității unui număr
Reprezentarea în baza 2 a unui număr par (și reprezentarea sa internă) se termină cu cifra 0, iar a unui număr impar se termină cu 1. Atunci, deoarece reprezentarea lui 1 are un singur bit 1, restul fiind 0, operația n & 1 are rezultat:
0, dacăneste par1, dacăneste impar
ÎN general n & 1 reprezintă ultimul bit din reprezentarea internă a lui n.
Verificarea faptului că un număr este putere a lui 2
Puterile lui 2 au un singur bit 1, ceilalți fiind 0. Mai clar, 2k are doar bitul k egal cu 1, ceilalți fiind 0. În plus, 2k-1 are toate cifrele binare 1 – de fapt, primele k cifre (de la dreapta) sunt 1, celelalte fiind 0. Observăm că aplicăm operația & între 2k și 2k-1 vom obține 0.
Pentru a verifica dacă un număr natural oarecare n este putere a lui 2, calculăm expresia n & (n-1). Rezultatul său este 0 dacă și numai dacă n este putere a lui 2.
În general, n & (n-1) are ca rezultat valoarea lui n în care ultimul bit 1 a fost transformat în 0. Dacă n este putere a lui 2, în rezultatul expresiei anterioare singurul bit 1 al lui n devine 0, deci rezultatul este 0.
Cea mai mare putere a lui 2 care îl divide pe n
Este egală cu 2 la puterea numărul de biți 0 de la sfârșitul reprezentării în baza 2 a lui n. Acest număr poate fi determinat rapid ca rezultat al expresiei n & -n. Analizați reprezentările interne a lui n și a lui -n pentru a înțelege mai bine!
Transformarea unui bit în 1
Fie n un număr întreg (de regulă natural), iar k un număr natural. Ne propunem să transformăm bitul k al lui n în 1, operație numită și setare a bitului k, ceilalți biți rămânând nemodificați – considerăm că valoarea lui k este mai mică decât numărul de cifre binare din reprezentarea internă a lui n (16 pentru short și unsigned short, 32 pentru int și unsigned int, etc.).
Transformarea unui bit în 1, precum și următoarele doua aplicații din acest articol (transformarea unui bit în 0 și determinarea valorii unui bit) se fac aplicând o anumită operație pe biți între numărul n și o mască, determinată convenabil pe baza valorii lui k.
În cazul transformării bitului k în 1, masca va avea doar bitul k egal cu 1, restul biților fiind 0. Astfel, masca este 1 << k, iar operația este n | (1 << k). Rezultatul ei are aceeași reprezentare internă ca n, cu excepția bitului k, care este transformat în 1; dacă bitul k era de la început 1, el nu se va modifica.
Mai precis, setarea bitului k se face prin următoarea atribuire: n = n | (1 << k);.
Transformarea unui bit în 0
Transformarea bitului k a lui n în 0, numită și resetarea bitului k, se face folosind o mască în care toți biții sunt 1, cu excepția bitului k sunt 1, bitul k fiind 0. Această mască este: ~(1 << k), ~ fiind operația de complementare a biților.
Atunci, resetarea bitului k a lui n se poate face cu atribuirea: n = n & ~(1 << k);.
Determinarea valorii unui bit
Pentru a determina bitul k al lui n putem folosi expresia (n >> k) & 1. Prin operația n >> k se elimină ultimele k cife binare ale lui n, iar (n >> k) & 1 reprezintă ultimul bit al lui n >> k, deci bitul k al lui n.
O altă variantă ar fi să folosim masca 1 << k, prin operația n & (1 << k). Rezultatul acestei operații este 0, dacă bitul k este 0, respectiv 2k (adică 1 << k), dacă bitul k este 1.
Proprietăți ale disjuncției exclusive ^
Disjuncția exclusivă are o proprietate interesantă, și anume că n ^ n este 0, indiferent de valoarea lui n. Acest lucru are câteva consecințe:
a ^ b ^ beste egal cua. Putem realizat astfel un mecanism de cripare:- fie
nun număr care trebuie criptat șikun număr care reprezintă cheia de criptare; - pentru criptare folosim operația
n ^ k, prin care obținem numărul criptatc; - pentru decriptare folosim operația
c ^ k, prin care obținem numărul inițialn;
- fie
- dacă avem mai multe valori
xși una singură apare de un număr impar de ori (celelalte apărând de număr par de ori), o putem determina calculând suma XOR a numerelorx, adică:S = 0;- pentru fiecare
xS ^= x;
- rezultatul este
S.
- putem interschimba valorile a două variabile
așib, fără a folosi o variabilă suplimentară:a = a ^ b;b = a ^ b;a = a ^ b;
Algoritmi de umplere
Problemă: Se dă o matrice binară, reprezentând harta unui teren (labirint, clădire, tablă de joc, etc.), în care valorile 0 reprezintă zone libere, iar cele egale cu 1 reprezintă obstacole. Într-o zonă aflată la coordonate cunoscute se află un mobil, care se poate deplasa prin matrice, trecând din zona curenta în una din cele patru zone vecine de pe aceeași linie sau aceeași coloană, dacă este liberă. Să se identifice zonele în care poate să ajungă mobilul.
Problema enunțată mai sus face parte din categoria Algoritmilor de umplere sau FILL, iar prezentul articol este consacrat acestor algoritmi!
Indicatorul lui Euler
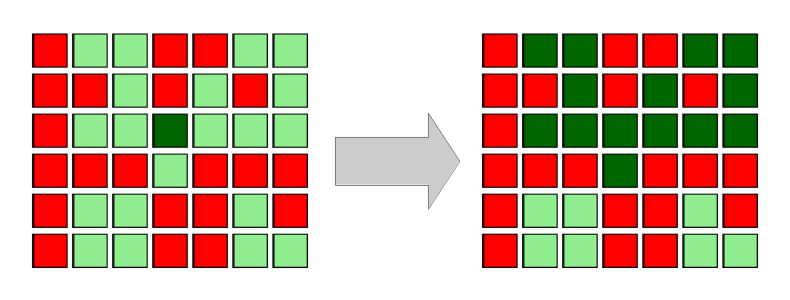
Indicatorul lui Euler sau funcția lui Euler, sau totient se notează cu \( \varphi(n) \) (unde \(n\) este un număr natural nenul ) și reprezintă numărul de numere mai mici sau egale cu \(n\) și prime cu acesta.
Valoarea lui \( \varphi(n) \) poate fi determinată prin numărarea valorilor prime cu \(n\), sau putem aplica următoarea proprietate:
Formula bazată pe descompunerea în factori
Proprietate: Pentru un număr natural \(n\) care are descompunerea în factori primi: \( n = p_{1}^{e_1} \cdot p_{2}^{e_2} \cdot … \cdot p_{k}^{e_k} \), are loc relația: \( \varphi(n)=(p_{1}-1)p_{1}^{e_{1}-1} \cdot(p_{2}-1)p_{2}^{e_{2}-1} \cdot \cdots \cdot (p_{k}-1)p_{k}^{e_{k}-1} \).
O scriere echivalentă este: \(\varphi(n)=n \left(1-\frac{1}{p_{1}}\right) \cdot \left(1-\frac{1}{p_{2}}\right) \cdot \cdots \cdot \left(1-\frac{1}{p_{k}}\right) \)
Exemplu: Pentru \( n = 12\), numerele mai mici decât \( n \), prime cu acesta sunt: \( \text 1, 5, 7, 11\), adică \( 4 \) numere.
Descompunerea în factori este: \( n = 12 = 2^2 \cdot 3^1 \).
Aplicând formula de mai sus obținem \( \varphi(12) = (2-1) \cdot 2^{2-1} \cdot (3-1) \cdot 3^{1-1} = 1 \cdot 2^1 \cdot 2 \cdot 3^0 = 2 \cdot 2 = 4 \).
Observaţie: Dacă \( n \) este număr prim, atunci \( \varphi(n) = n – 1 \).
Teorema lui Euler:
Dacă \(a, n\) sunt două numere naturale prime între ele, atunci:
$$ a^{ \varphi (n) } \equiv 1 \left(\mod n \right) $$
Secvență C++
Următoarea funcție C++ determină valoarea indicatorului lui Euler pentru o valoare n transmisă ca parametru:
int phi(int n)
{
int r = n , d = 2;
while(n > 1)
{
if(n % d == 0)
{
r = r / d * (d - 1);
while(n % d == 0)
n /= d;
}
d ++;
if(d * d > n)
d = n;
}
return r;
}
Complexitatea ei este \(O \left( \sqrt{n} \right) \).
Determinarea indicatorului lui Euler pe toate numerele mai mici sau egale cu n
Uneori – vezi problema #Tramvaie – trebuie să determinăm indicatorul lui Euler pentru multe numere, acestea fiind relativ mici (de exemplu, mai mici decât 1.000.000). În această situație se poate utiliza un algoritm similar cu Ciurul lui Etatostene, bazat tot pe formula de mai sus: \( \varphi(n)=n \left(1-\frac{1}{p_{1}}\right) \cdot \left(1-\frac{1}{p_{2}}\right) \cdot \cdots \cdot \left(1-\frac{1}{p_{k}}\right) \). În plus, dacă \( p \) este număr prim, atunci \( \varphi(p) = p -1 \).
Algoritmul este următorul, pentru a determina valoarea indicatorului lui Euler pentru toate numerele mai mici sau egale cu DIM:
- declarăm un tabloul
F[]cuDIM + 1elemente; la final,F[x]va reprezenta indicatorul lui Euler pentrux - inițializăm fiecare element
F[i] = i; scopul acestei inițializari este dublu:- pe de o parte în formula pentru indicatorul lui Euler al lui
nprodusul începe cun; - pe de altă parte, dacă pe parcurs
F[p]este egal cup, deducem căpeste număr prim și va influența indicatorul lui Euler pentru toți multipli săi.
- pe de o parte în formula pentru indicatorul lui Euler al lui
- parcurgem cu
pnumerele de la2laDIM: - dacă
F[p]este egal cup, înseamnă căpeste număr prim:- decrementăm
F[p], aducându-l la valoarea corectă a indicatorului pentru numere prime; (A) - parcurgem toți multipli
kai luipmai mari decât acesta și actualizăm valoarea lui \( F[k] = F[k] * (1 – \frac{1}{p})\). (B)
- decrementăm
OBS: Pașii (A) și (B) pot fi integrați într-un singur pas de tip (B). Cum?
Secvență C++
int F[DIM + 1];
for(int i =1 ; i <= DIM ; i ++)
F[i] = i;
for(int i = 2; i <= DIM ; i ++)
if(F[i] == i)
{
F[i] --;
for(int j =2 ; j * i <= DIM ; j ++)
F[j * i]= F[j * i] / i * (i - 1);
}
Algoritmul lui Lee
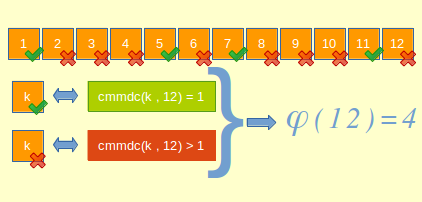
Algoritmul lui Lee este folosit pentru determinarea ieșirii dintr-un labirint sau în alte probleme similare cu aceasta.
Considerăm un labirint reprezentat printr-o matrice cu n linii și m coloane, în care elementele egale cu 0 reprezintă camere libere, iar cele egale cu 1 reprezintă camere blocat. Un mobil se deplasează prin labirint, trecând dintr-o cameră în alta dacă acestea se învecinează pe linie sau pe coloană. Determinați numărul minim de pași pe care îi face mobilul pentru a ieși din labirint (a ajunge pe chenarul matricei).
Pentru rezolvarea problemei procedăm astfel:
- marcăm în matrice elementele libere cu
0, iar obstacolele cu-1(valorile pozitive sunt folosite în alt scop) - marcăm poziția de start cu
1 - pentru fiecare
k=1,2,3,...- analizăm elementele marcate cu valoarea
kși marcăm cuk+1toți vecinii săi care sunt liberi și nemarcați - dacă pentru un anumit
knu găsim niciun element egal cuk, ne oprim
- analizăm elementele marcate cu valoarea
Lee cu coadă
Dacă pentru fiecare k parcurgem toate elementele matricei labirint pentru a identifica elementele egale cu k, algoritmul de mai sus este neeficient.
O soluție mult mai bună este să folosim o coadă:
- marcăm poziția de început cu
1și o adăugăm în coadă - expandăm coada. Cât timp coada este nevidă:
- scoatem din coadă un element, cu coordonatele
(i,j) - analizăm vecinii acestuia:
- dacă vecinul curent
(iv,jv) este liber și nemarcat, îl marcăm în matrice cu o valoare mai mare cu1decât elementul(i,j)–A[iv][jv] = A[i][j] + 1;– și îl adăugăm în coadă.
- dacă vecinul curent
- scoatem din coadă un element, cu coordonatele
Implementare C++
Pentru mai multe modalități de implementare a cozii vezi articolul Fill cu coadă. În continuare vom folosi varianta cu containerul
void Lee(int istart ,int jstart)
{
queue<pair<int,int>> Q;
//initializare coada
Q.push(make_pair(istart , jstart));
//marcare pozitie de start
A[istart][jstart] = 1;
while(! Q.empty()) // cat timp coada este nevida
{
int i = Q.front().first, j = Q.front().second; // determinam elementul de la inceputul cozii
for(int k = 0 ; k < 4 ; k ++)
{
int iv = i + di[k], jv = j + dj[k]; // coordonatele vecinului
if(iv >= 1 && iv <= n && jv >= 1 && jv <= m // element în matrice
&& A[iv][jv] == 0) // element liber si nemarcat
{
// marcam elementul vecin cu o valoare mai mare
A[iv][jv] = A[i][j] + 1;
// il adaugam in coada
Q.push(make_pair(iv , jv));
}
}
Q.pop(); // eliminam din coada
}
}
Reconstituirea traseului
În unele probleme se dau două poziții în matricea labirint, (istart,jstart) și (istop,jstop) și se cere determinarea celui mai scurt traseu de la poziția (istart,jstart) la poziția (istop,jstop).
Operația se va realiza începând de la poziția finală spre cea inițială. Dacă poziția curentă a traseului are coordonatele (i,j), atunci poziția de dinainte va fi acel vecin (iv,jv) pentru care A[i][j] == A[iv][jv] + 1. Dacă sunt mai mulți asemenea vecini, oricare dintre ei este corect.
Deoarece elementele traseului se determină în ordine inversă, nu putem să afișăm direct coordonatele elementelor de pe traseu. Avem două soluții:
- să reconstituim traseul folosind un subprogram recursiv, care să aibă ca parametri coordonatele elementului curent, autoapelul să se facă pentru coordonatele vecinului aflat în traseul determinat înaintea elementului curent, iar afișarea să se facă la revenirea din autoapel;
- să reconstitui traseul iterativ și să memorăm coordonatele elementelor de pe traseu într-o structură corespunzătoare (tablou unidimensional de structuri, vector din STL, pereche de tablouri unidimensionale), iar la final să afișam elementele structurii de date în ordine inversă.
Reconstituire recursivă
void Traseu(int i, int j , int lg)
{
if(A[i][j] == 1)
{
cout << lg << "\n";
cout << i << " " << j << "\n";
}
else
{
int p = -1;
for(int k = 0 ; k < 4 && p == -1 ; k ++)
if(A[i][j] == A[i+di[k]][j+dj[k]] + 1)
p = k;
Traseu1(i + di[p] , j + dj[p] , lg + 1);
cout << i << " " << j << "\n";
}
}
Funcția C++ de mai sus afișează mai întâi lungimea traseului, apoi coordonatele elementelor de pe traseu. Desigur, lungimea traseului putea fi determinată în mod direct, din matrice. Apelul principal va fi:
Traseu(istart , jstart , 1);
Reconstituire nerecursivă
void Traseu2(int istop, int jstop)
{
vector<pair<int,int>> V;
int i = istop , j = jstop;
V.push_back(make_pair(i , j));
do
{
int p = -1;
for(int k = 0 ; k < 4 && p == -1 ; k ++)
if(A[i][j] == A[i+di[k]][j+dj[k]] + 1)
p = k;
i = i + di[p] , j = j + dj[p];
V.push_back(make_pair(i , j));
}
while(A[i][j] != 1);
cout << V.size() << '\n';
for(vector<pair<int,int>>::reverse_iterator I = V.rbegin() ; I != V.rend() ; I ++)
cout << I->first << " " << I->second << '\n';
}
Pentru memorarea coordonatelor elementelor de pe traseu am folosit un vector din STL. Bineînțeles, am fi putut folosi și un tablou standard C și, de asemenea, am fi putut parcurge vectorul cu un indice în loc de iterator.
Programare dinamică - introducere
Programarea dinamică este o metodă de rezolvare a unor probleme de informatică în care se cere de regulă determinarea unei valori maxime sau minime, sau numărarea elementelor unei mulțimi.
Similar cu metoda Divide et Impera, problema se împarte în subprobleme:
- de aceeași natură cu problema inițială;
- de dimensiuni mai mici;
- spre deosebire de Divide et Impera, problemele nu mai sunt independente, ci se suprapun – probleme superpozabile!
- rezolvarea optimă a problemei inițiale depinde de rezolvarea optimă a subproblemelor – principiul optimalității!
Observație: Subproblemele se mai numesc și stări ale problemei.
 Problemă: Se dă o scară cu
Problemă: Se dă o scară cu N trepte. Un individ se află în partea de jos a scării și poate să urce câte o treaptă la un pas, sau câte două trepte la un pas. În câte moduri poate urca scara?
Exemplu: Observăm că dacă scara are o treaptă, ea poate fi urcată într-un singur mod, iar dacă are două trepte, sunt două modalități de a urca scara: doi pași de o treaptă sau un un pas de două trepte. Pentru N=4, scara poate fi urcată în 5 moduri:
1 1 1 11 1 21 2 12 1 12 2
Rezolvare: Este o problemă de numărare; dacă numerotăm treptele, observăm că pe treapta N se poate ajunge de pe treapta N-1 (cu un pas de o treaptă) sau de pe treapta N-2 (cu un pas de două trepte), cazurile N=1 și N=2 fiind particulare. Atunci, numărul de variate de a urca N trepte este egal cu numărul de variante de a urca N-1 trepte, plus numărul de variante de a urca N-2 trepte. Deducem deci următoarea relație de recurență, în care \( T(n) \) reprezintă numărul de modalități de a urca o scară cu n trepte:
$$ T(n) = \begin{cases}1, & n = 1\\ 2, & n = 2\\ T(n-1)+T(n-2), & n > 2 \end{cases} $$
Constatăm că formula anterioară respectă proprietățile descrise mai sus pentru probleme rezolvabile prin programare dinamică: subprobleme de același tip, de dimensiuni mai mici și care se suprapun; în determinarea lui \(T(n)\) intervine \(T(n-1)\) și \(T(n-2)\). În determinarea lui \(T(n-1)\) apare din nou \(T(n-2)\), ș.a.m.d., situație care face ca utilizarea recursivității să fie foarte ineficientă.
De fapt, putem observa că formula de mai sus este de fapt definiția șirului lui Fibonacci, despre care am văzut deja că are o soluție de complexitate \(O(n) \), construind termenii în ordine crescătoare, folosind eventual un tablou unidimensional (sau doar trei variabile simple).
Determinarea relației de recurență este o caracteristică a programării dinamice, și una dintre dificultățile principale în rezolvarea problemei. Capacitatea de a identica relațiile de recurență – și deci de a rezolva problema – se dezvoltă treptat, prin rezolvarea de probleme.
Odată identificată relația de recurență, este necesară stabilirea unui algoritm de rezolvare a recurenței. Datorită suprapunerii subproblemelor, utilizarea recursivității este foarte neeficientă. De regulă se folosește o structură de date suplimentară – tablou unidimensional, bidimensional sau cu mai multe dimensiuni (în funcție de numărul variabilelor care intervin în relația de recurență).
Soluția problemei se află într-un element al tabloului sau se poate determina folosind o parte a elementelor acestuia. Elementele tabloului se vor determina unul câte unul, până când sunt determinate toate elementele necesare pentru aflarea soluției!
Pentru problema scării, notăm tabloul necesar cu V[]. Este un tablou unidimensional deoarece în relația de recurență apare o singură variabilă (n); formula recursivă devine:
V[1] = 1,V[2]=2;V[n] = V[n-1] + V[n-2], pentrun>2;
Inițializăm primele două elemente ale tabloului, iar celelalte elemente vor fi construite unul după altul, de la stânga spre dreapta. Rezultatul se va găsi în V[n].
V[1] = 1, V[2] = 2;
for(int i = 3 ; i <= n ; i ++)
V[n] = V[n-1] + V[n-2];
cout << V[n];
Metoda folosită mai sus pentru rezolvarea recurenței se numește bottom-up. Tabloul se construiește “de jos în sus”, element cu element, până la cel căutat. Toate elementele tabloului au fost completate cu valori.
O altă metodă de rezolvare a recurenței este top-down, “de sus în jos”. Metoda folosește recursivitatea, dar, pentru a evita rezolvarea de mai multe ori a subproblemelor, folosește memoizarea: soluția fiecărei subprobleme rezolvate este memorată într-un tablou și când trebuie să rezolvăm aceeași subproblemă cunoaștem deja soluția!
Următoarea secvență rezolvă problema scării (șirul lui Fibonacci) folosind memoizarea:
long long V[100];
long long T(int n)
{
if(V[n] != 0)
return V[n];
if(n < 3)
V[n] = n;
else
V[n] = T(n-1) + T(n-2);
return V[n];
}
Concluzii
- o problemă se rezolvă prin metoda programării dinamice dacă se poate descompune în subprobleme superpozabile și care respectă principiul optimalității;
- se identifică relația de recurență pentru subprobleme și structura de date ajutătoare;
- se rezolvă recurența, folosind metoda bottom-up sau top-down.
STL lower_bound, upper_bound
Standard Template Library – STL conține două funcții extrem de utile care realizează căutarea binară, lower_bound și upper_bound. Ele se găsesc în headerul algorithm și realizează căutarea atât pentru vectori STL cât și pentru tablourile unidimensionale standard C. În ambele cazuri elementele structurii de date trebuie să fie ordonate după un anumit criteriu, iar funcțiile au următoarele rezultate:
lower_bound– cel mai din stânga element care este mai mare sau egal cu valoarea căutată;upper_bound– cel mai din stânga element care este strict mai mare decât valoarea căutată.
Observație: STL conține și funcția binary_search, care caută într-o structură de date o anumită valoare și returnează true dacă o găsește și false în caz contrar. Funcția lower_bound furnizează informații suplimentare, fiind astfel mai utilă în practică.
Căutarea în vectori STL
Antetele funcțiilor sunt:
Iterator lower_bound(Iterator p, Iterator u, Valoare v);Iterator lower_bound(Iterator p, Iterator u, Valoare v, Comparator fcmp);
Valoare este un tip de date oarecare pentru care este definită relația de ordine < sau funcția comparator fcmp, iar p și u sunt iteratori la elemente ale unui vector STL de tip vector<Valoare>.
Funcția caută în secvența [p,u) cel mai din sțânga element mai mare sau egal cu v și returnează iterator la acel element, sau u, dacă nu există un asemenea element nu există. Dacă elementele vectorului sunt ordonate după un alt criteriu decât <, se folosește o funcție de comparare fcmp.
Iterator upper_bound(Iterator p, Iterator u, Valoare v);Iterator upper_bound(Iterator p, Iterator u, Valoare v, Comparator fcmp);
Funcția caută în secvența [p,u) cel mai din sțânga element mai mare strict decât v și returnează iterator la acel element, sau u, dacă nu există un asemenea element nu există. Dacă elementele vectorului sunt ordonate după un alt criteriu decât <, se folosește o funcție de comparare fcmp.
În funcțiile de mai sus, numele parametrilor au următoarea semnificație:
p– primulu– ultimulv– valoarea de căutatf– comparator (funcție de comparare)
Important: Elementul u nu face parte din secvența în care se caută valoarea v.
Exemplu
vector<int> A;
int k;
....
auto I = lower_bound(A.begin(), A.end(), k); // I este iterator
if(I == A.end() || *I != k)
cout << k << " nu apare în vector";
else
cout << k << " apare în vector pe poziția " << I - A;
Căutarea în tablouri unidimensionale standard C
Antetele funcțiilor sunt:
Valoare * lower_bound(Valoare * p, Valoare * u, Valoare v);Valoare * lower_bound(Valoare * p, Valoare * u, Valoare v, Comparator fcmp);
Valoare este un tip de date oarecare pentru care este definită relația de ordine < sau funcția comparator fcmp, iar p și u sunt pointeri la Valoare șî reprezintă adresele unor elemente ale unui tablou declarat Valoare A[dim];.
Funcția caută în secvența [p,u) cel mai din sțânga element mai mare sau egal cu v și returnează pointer la acel element, sau u, dacă nu există un asemenea element nu există. Dacă elementele vectorului sunt ordonate după un alt criteriu decât <, se folosește o funcție de comparare fcmp.
Iterator upper_bound(Iterator p, Iterator u, Valoare v);Iterator upper_bound(Iterator p, Iterator u, Valoare v, Comparator fcmp);
Funcția caută în secvența [p,u) cel mai din sțânga element mai mare strict decât v și returnează pointer la acel element, sau u, dacă nu există un asemenea element nu există. Dacă elementele vectorului sunt ordonate după un alt criteriu decât <, se folosește o funcție de comparare fcmp.
Exemplu 1
#include <iostream>
#include <algorithm>
int main()
{
int n = 10, v[]={10, 20, 30, 40, 50, 60, 70, 80, 90, 100}; // indexare de la zero
//lower_bound: cel mai din stânga iterator i pentru care v[i] >= x
std::cout << std::lower_bound(v , v + n , 20) - v << std::endl; // 1, v[1] >= 20
std::cout << std::lower_bound(v , v + n , 25) - v << std::endl; // 2, v[2] >= 25
//upper_bound: cel mai din stânga iterator i pentru care v[i] > x
std::cout << std::upper_bound(v , v + n , 20) - v << std::endl; // 2, v[2] > 20
std::cout << std::upper_bound(v , v + n , 25) - v << std::endl; // 2, v[2] > 25
return 0;
}
Exemplu 2
int A[1000], n; // indexat de la 0 la n - 1
int k;
....
int * q = lower_bound(A, A + n, k); // q este pointer
if(q == A + n || *q != k)
cout << k << " nu apare în tablou";
else
cout << k << " apare în tablou la indicele " << q - A;
Funcția de comparare
Dacă elementele vectorului (tabloului) satisfac altă relație de ordine, va trebui să definim o funcție de comparare, fcmp, sau să folosim un predicat din STL. De exemplu, dacă vectorul (tabloul) are elementele în ordine descrescătoare putem folosi greater. De exemplu:
int A[1000], n; // indexat de la 0 la n - 1 int k; .... int * q = lower_bound(A, A + n, k, greater<int>());
În cazul unei relații de ordine mai complexe, se poate defini o funcție de comparare, în felul următor:
bool fcmp(Valoare A, Valoare B);
Funcția are doi parametru de același tip cu elementel tabloului (vectorului) în care face căutarea și va returna true, dacă primul parametru, A, este strict înaintea lui B în ordinea dorită și false în caz contrar.
Referințe
Interfața CodeBlocks
Uneori interfața CodeBlocks suferă modificări, lipsind anumite componente ale ferestrei. De exemplu, poate să aibă aspectul următor:
Acest articol prezintă modul în care afișam sau ascundem cele mai importante/frecvent utilizate componente ale interfeței CodeBlocks.
Manager
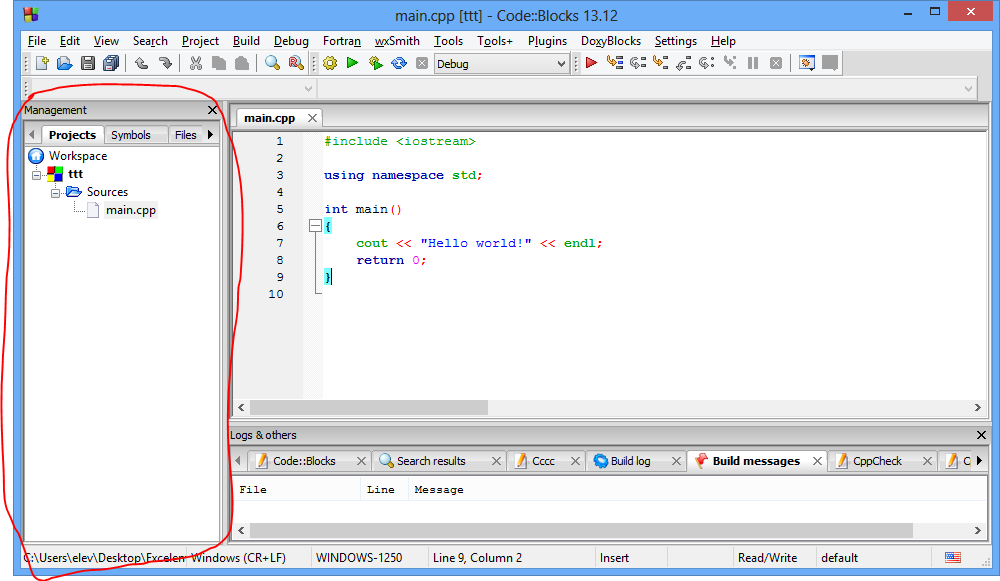
Panoul Manager este important deoarece aici sunt afișate fișierele care fac parte din proiectul CodeBlocks.
Afișarea lui poate fi oprită/realizată din meniul View->Manager sau scurtătura Shift+F2.
Logs
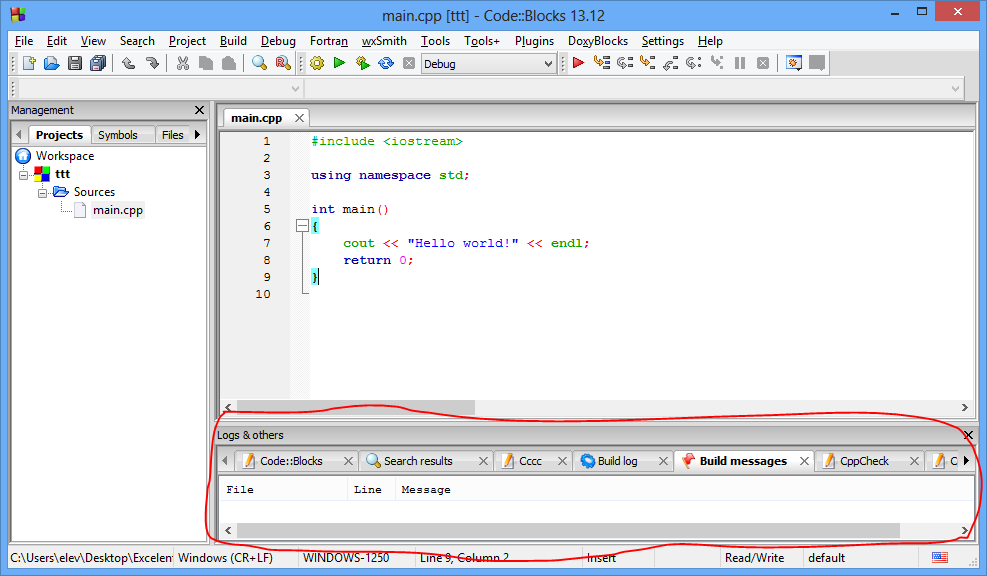
Panoul Logs este important deoarece aici sunt afișate erorile de sintaxă și avertismentele generate la compilarea programului C++.
Afișarea lui poate fi oprită/realizată din meniul View->Logs sau scurtătura F2.
Editor tabs
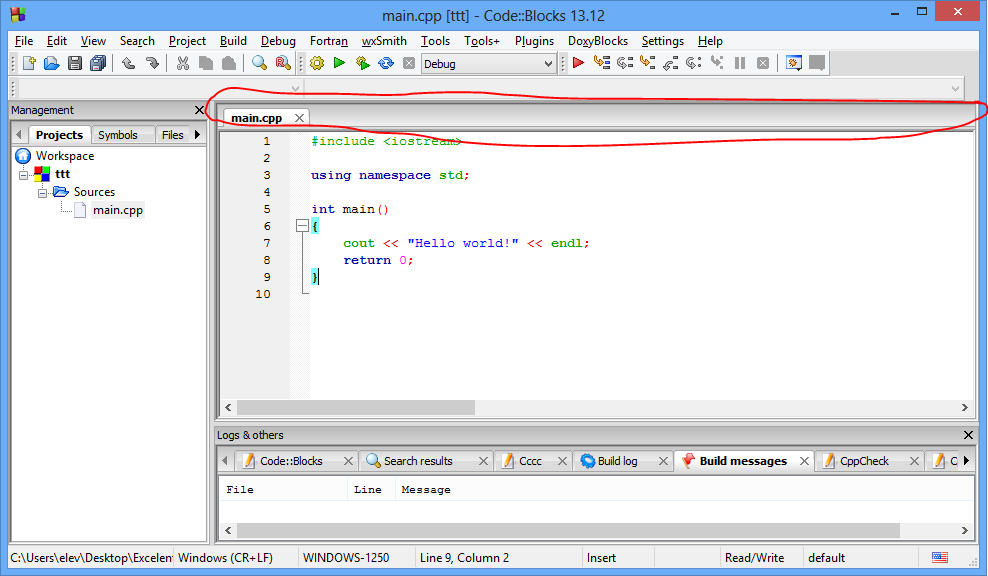
Dacă avem mai multe fișiere deschise (situație tipică în cazul programelor care fac operațiile de intrare/ieșire cu fișiere) folosim pentru trecerea de la un document la altul tab-urile afișate deasupra zonei de editare.
Afișarea tab-rilor de editare poate fi oprită/realizată din meniul View->Hide editor tabs.
Barele de unelte
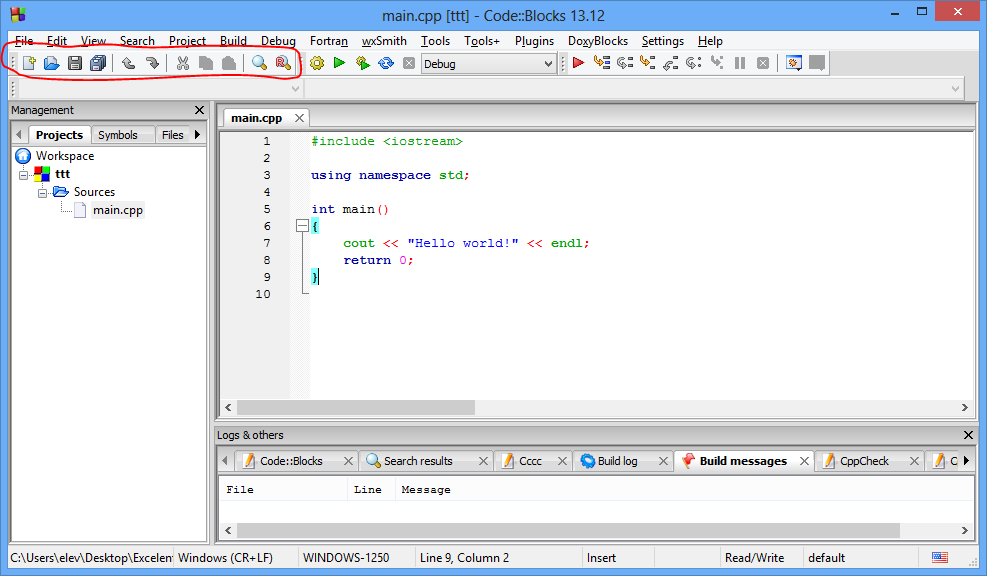
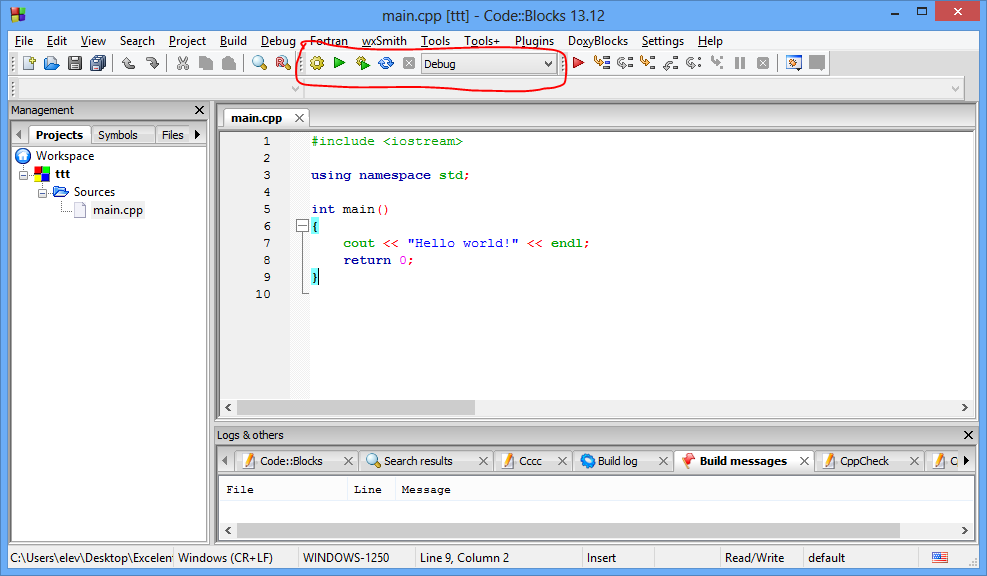
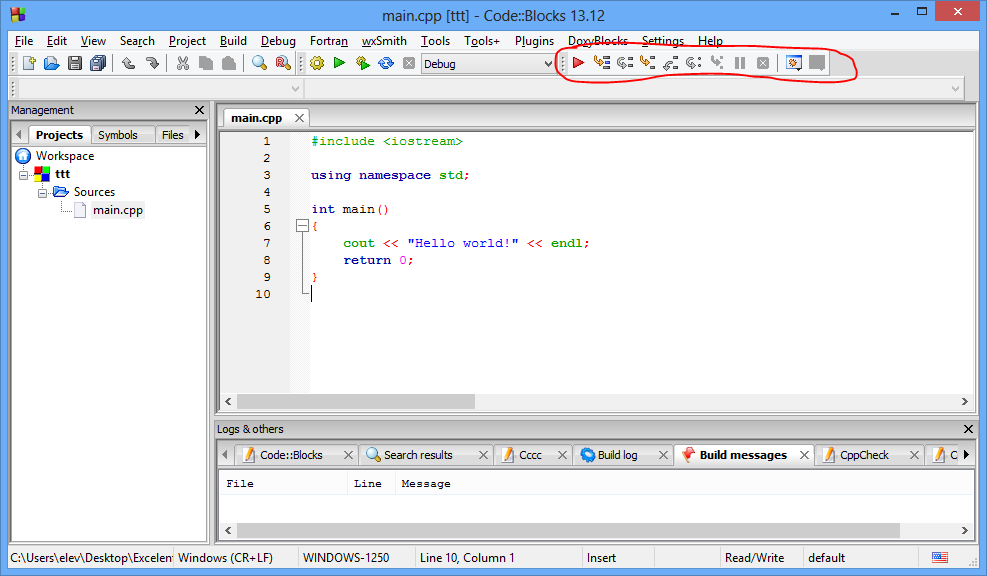
Barele de unelte conțin butoane cu care accesăm rapid anumite opțiuni ale aplicației. Vizibilitatea lor este controlată prin:
- View->Toolbars->Main
- View->Toolbars->Compiler
- View->Toolbars->Debugger
- etc.
Andocarea panourilor
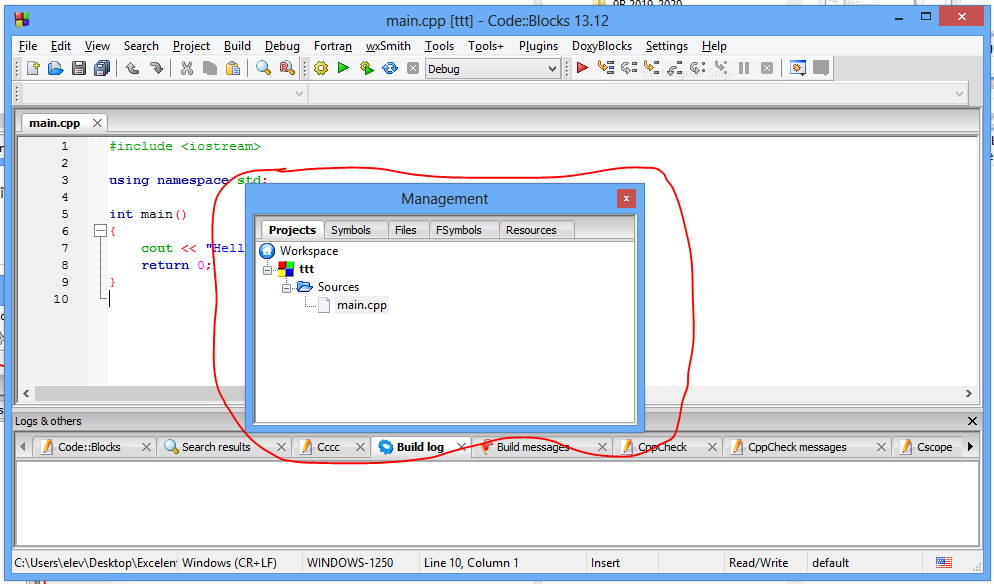
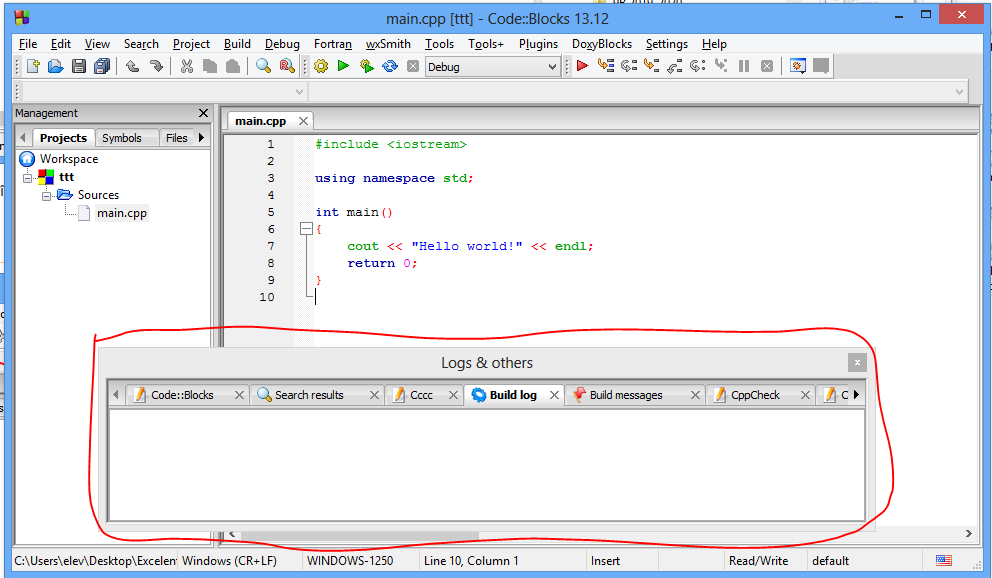
Implicit panourile Manager și Logs sunt andocate (“lipite”) la marginea ferestrei CodeBlocks: marginea din stânga, respectiv de jos. Andocarea poate fi anulată, panourile devenind ferestre flotante pe desktop. Pentru a le reandoca la marginea ferestrei, trageți panoul de bara de nume spre marginea dorita a ferestrei și eliberați-o acolo.
Spor la codat!