Articole recomandate
Studiu structura tablourilor de tip bool
Atat la concursuri si olimpiade cat si in aplicatii practice, de multe ori se intalneste problema eficientei spatiului, cel mai grav caz al acesteia fiind stocarea unui tablou care contine valori de tip bool. Toate seturile de instructiuni moderne (x86, x64, ARM) pot adresa memorie doar la nivel de octet. Din aceasta cauza, aplicatii care necesita granularitate mai mare pentru elemente ce nu necesita ocuparea unui intreg octet trebuie ori sa sacrifice timp de executie pentru a combina mai multe elemente intr-un singur octet, ori sa sacrifice memorie, punand un singur element per octet si ignorand spatiul ramas neutilizat.
Exista un zvon ca tablourile din C sunt optimizate automat de compilator pe sisteme Linux in cadrul Olimpiadei de Informatica.
Deoarece mediul incurajat in cadrul Olimpiadei este Code::Blocks cu compilatoarele gcc/g++ MinGW, e natural ca si comisia de evaluare sa foloseasca aceleasi compilatoare pe Windows si variantele lor de linux pentru evaluarea pe linux. De aceea, acestea sunt compilatoarele folosite in demonstratiile urmatoare.
Pe langa tablourile simple mostenite din C, standardul C++ ofera doua metode principale pentru stocarea eficienta a tablourilor de booleeni: std::vector<bool> si std::bitset.
Scopul acestui articol este studierea diverselor tipuri de tablouri de booleeni, analizand atat codul assembler produs de compilator cat si comportamentul programului compilat.
Vector global (.bss)
volatile bool v[8 * 1024 * 1024];
int main() {
v[0] = true;
v[1] = false;
v[123] = true;
return v[123];
}
Codul de mai sus a fost compilat cu gcc la diferite nivele de optimizare (neoptimizat, optimizat pentru viteza cu -O2, optimizat pentru viteza si memorie cu -Os care implica -O2):
$ gcc --versiongcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609$ gcc global.c -o global-neoptimizat $ gcc global.c -O2 -o global-o2 $ gcc global.c -Os -o global-os
La toate cele 3 binare sectiunea .bss (cea in care stocate variabilele globale) are dimensiunea 0x800020 = 8MiB si un pic. Considerand ca nu se irosesc 7/8 din sectiune, se poate spune ca vectorul ocupa aproape tot spatiul acesta, deci elementele ocupa un octet fiecare.
Pentru redundanta se poate analiza si codul compilat:
Neoptimizat
00000000004004d6 <main>:
4004d6: 55 push rbp
4004d7: 48 89 e5 mov rbp,rsp
4004da: c6 05 7f 0b 20 00 01 mov BYTE PTR [rip+0x200b7f],0x1 # 601060 <v>
4004e1: c6 05 79 0b 20 00 00 mov BYTE PTR [rip+0x200b79],0x0 # 601061 <v+0x1>
4004e8: c6 05 ec 0b 20 00 01 mov BYTE PTR [rip+0x200bec],0x1 # 6010db <v+0x7b>
4004ef: 0f b6 05 e5 0b 20 00 movzx eax,BYTE PTR [rip+0x200be5] # 6010db <v+0x7b>
4004f6: 0f b6 c0 movzx eax,al
4004f9: 5d pop rbp
4004fa: c3 ret
Primele doua instructiuni pregatesc stiva pentru functia main. Acestea sunt, in general, prezente in toate functiile si se numesc “preambulul”.
Urmatoarele 3 mov-uri seteaza valori din vector. Se poate observa ca se adreseaza la nivel de octet, nu de bit.
Primul movzx copiaza valoarea v[123] in registrul eax, iar a doua sterge tot in afara de ultimii 4 biti ai registrului, in caz ca ar fi fost altceva in afara de 0 si 1.
pop rbp se intoarce la stiva functiei precedente, marcand sfarsitul lui main, iar ret returneaza valoarea din registrul eax.
-O2
00000000004003e0 <main>:
4003e0: c6 05 79 0c 20 00 01 mov BYTE PTR [rip+0x200c79],0x1 # 601060 <v>
4003e7: c6 05 73 0c 20 00 00 mov BYTE PTR [rip+0x200c73],0x0 # 601061 <v+0x1>
4003ee: c6 05 e6 0c 20 00 01 mov BYTE PTR [rip+0x200ce6],0x1 # 6010db <v+0x7b>
4003f5: 0f b6 05 df 0c 20 00 movzx eax,BYTE PTR [rip+0x200cdf] # 6010db <v+0x7b>
4003fc: c3 ret
A disparut preambulul deoarece nu se declara nimic pe stiva. Registrul eax nu mai este redus la ultimii 4 biti, operatie care oricum nu era necesara deoarece doar ultimul bit era folosit. In rest, elementele tot ocupa un octet.
-Os
00000000004003e0 <main>:
4003e0: c6 05 79 0c 20 00 01 mov BYTE PTR [rip+0x200c79],0x1 # 601060 <v>
4003e7: c6 05 73 0c 20 00 00 mov BYTE PTR [rip+0x200c73],0x0 # 601061 <v+0x1>
4003ee: c6 05 e6 0c 20 00 01 mov BYTE PTR [rip+0x200ce6],0x1 # 6010db <v+0x7b>
4003f5: 0f b6 05 df 0c 20 00 movzx eax,BYTE PTR [rip+0x200cdf] # 6010db <v+0x7b>
4003fc: c3 ret
Ma asteptam ca macar aici sa cedeze timp pentru memorie si sa foloseasca instructiuni pe biti, dar nu e cazul. Codul rezultat e identic cu cel de la -O2.
Vector pe stiva
int main() {
volatile bool v[8 * 1024 * 1024];
v[0] = true;
v[1] = false;
v[123] = true;
return v[123];
}
Compilarea a fost facuta exact ca mai devreme:
$ gcc --versiongcc (Ubuntu 5.4.0-6ubuntu1~16.04.5) 5.4.0 20160609$ gcc stiva.c -o stiva-neoptimizat $ gcc stiva.c -O2 -o stiva-o2 $ gcc stiva.c -Os -o stiva-os
Deoarece dimensiunea stivei nu e specificata in headerele executabilului, marimea vectorului poate fi determinata prin analiza dinamica cu un debugger sau prin analiza statica a codului compilat.
Neoptimizat
0000000000400546 <main>:
400546: 55 push rbp
400547: 48 89 e5 mov rbp,rsp
40054a: 48 81 ec 10 00 80 00 sub rsp,0x800010
400551: 64 48 8b 04 25 28 00 mov rax,QWORD PTR fs:0x28
400558: 00 00
40055a: 48 89 45 f8 mov QWORD PTR [rbp-0x8],rax
40055e: 31 c0 xor eax,eax
400560: c6 85 f0 ff 7f ff 01 mov BYTE PTR [rbp-0x800010],0x1
400567: c6 85 f1 ff 7f ff 00 mov BYTE PTR [rbp-0x80000f],0x0
40056e: c6 85 6b 00 80 ff 01 mov BYTE PTR [rbp-0x7fff95],0x1
400575: 0f b6 85 6b 00 80 ff movzx eax,BYTE PTR [rbp-0x7fff95]
40057c: 0f b6 c0 movzx eax,al
40057f: 48 8b 55 f8 mov rdx,QWORD PTR [rbp-0x8]
400583: 64 48 33 14 25 28 00 xor rdx,QWORD PTR fs:0x28
40058a: 00 00
40058c: 74 05 je 400593 <main+0x4d>
40058e: e8 8d fe ff ff call 400420 <__stack_chk_fail [at] plt>
400593: c9 leave
400594: c3 ret
Un lucru nou fata de varianta cu vectorul global este aparitia detectarii de stack smashing. Dupa primele 3 instructiuni care constituie preambulul urmeaza 2 instructiuni care pun o valoare secreta imediat dupa sfarsitul vectorului. Registrul rax e folosit ca valoare intermediara, asa ca trebuie resetat la 0 cu xor eax,eax. La sfarsit se verifica daca valoarea secreta a ramas neschimbata. Daca nu mai e aceiasi se considera ca programul nu a functionat corect si se apeleaza __stack_chk_fail.
In rest, instructiunile de la 400560 la 40057c sunt foarte similare cu cele de la global-neoptimizat.
-O2
0000000000400450 <main>:
400450: 48 81 ec 18 00 80 00 sub rsp,0x800018
400457: 64 48 8b 04 25 28 00 mov rax,QWORD PTR fs:0x28
40045e: 00 00
400460: 48 89 84 24 08 00 80 mov QWORD PTR [rsp+0x800008],rax
400467: 00
400468: 31 c0 xor eax,eax
40046a: c6 04 24 01 mov BYTE PTR [rsp],0x1
40046e: c6 44 24 01 00 mov BYTE PTR [rsp+0x1],0x0
400473: c6 44 24 7b 01 mov BYTE PTR [rsp+0x7b],0x1
400478: 0f b6 44 24 7b movzx eax,BYTE PTR [rsp+0x7b]
40047d: 48 8b 94 24 08 00 80 mov rdx,QWORD PTR [rsp+0x800008]
400484: 00
400485: 64 48 33 14 25 28 00 xor rdx,QWORD PTR fs:0x28
40048c: 00 00
40048e: 75 08 jne 400498 <main+0x48>
400490: 48 81 c4 18 00 80 00 add rsp,0x800018
400497: c3 ret
400498: e8 83 ff ff ff call 400420 <__stack_chk_fail [at] plt>
Varianta aceasta foloseste un preambul dubios, ne mai salvand rbp si rsp. Stack smash detection arata la fel. Asemenea optimizarii la varianta globala, a disparut a doua instructiune movzx.
-Os
0000000000400450 <main>:
400450: 48 81 ec 18 00 80 00 sub rsp,0x800018
400457: 64 48 8b 04 25 28 00 mov rax,QWORD PTR fs:0x28
40045e: 00 00
400460: 48 89 84 24 08 00 80 mov QWORD PTR [rsp+0x800008],rax
400467: 00
400468: 31 c0 xor eax,eax
40046a: c6 44 24 08 01 mov BYTE PTR [rsp+0x8],0x1
40046f: c6 44 24 09 00 mov BYTE PTR [rsp+0x9],0x0
400474: c6 84 24 83 00 00 00 mov BYTE PTR [rsp+0x83],0x1
40047b: 01
40047c: 0f b6 84 24 83 00 00 movzx eax,BYTE PTR [rsp+0x83]
400483: 00
400484: 48 8b 94 24 08 00 80 mov rdx,QWORD PTR [rsp+0x800008]
40048b: 00
40048c: 64 48 33 14 25 28 00 xor rdx,QWORD PTR fs:0x28
400493: 00 00
400495: 74 05 je 40049c <main+0x4c>
400497: e8 84 ff ff ff call 400420 <__stack_chk_fail [at] plt>
40049c: 48 81 c4 18 00 80 00 add rsp,0x800018
4004a3: c3 ret
Codul arata foarte similar cu cel de la -O2, singura diferenta fiind ca vectorul nu e in acelasi loc relativ cu rsp (banuiesc ca pentru aliniere).
Analiza dinamica
Deoarece rezultatele celor 3 executabile sunt similare, voi demonstra doar pe cel neoptimizat.
Initial deschid programul cu gdb, afisez instructiunile din main si pun un breakpoint undeva in mijlocul functiei.
$ gdb stiva-neoptimizat(gdb) set disassembly-flavor intel(gdb) disassemble mainDump of assembler code for function main:
0x0000000000400546 <+0>: push rbp
0x0000000000400547 <+1>: mov rbp,rsp
0x000000000040054a <+4>: sub rsp,0x800010
0x0000000000400551 <+11>: mov rax,QWORD PTR fs:0x28
0x000000000040055a <+20>: mov QWORD PTR [rbp-0x8],rax
0x000000000040055e <+24>: xor eax,eax
0x0000000000400560 <+26>: mov BYTE PTR [rbp-0x800010],0x1
0x0000000000400567 <+33>: mov BYTE PTR [rbp-0x80000f],0x0
0x000000000040056e <+40>: mov BYTE PTR [rbp-0x7fff95],0x1
0x0000000000400575 <+47>: movzx eax,BYTE PTR [rbp-0x7fff95]
0x000000000040057c <+54>: movzx eax,al
0x000000000040057f <+57>: mov rdx,QWORD PTR [rbp-0x8]
0x0000000000400583 <+61>: xor rdx,QWORD PTR fs:0x28
0x000000000040058c <+70>: je 0x400593 <main+77>
0x000000000040058e <+72>: call 0x400420 <__stack_chk_fail [at] plt>
0x0000000000400593 <+77>: leave
0x0000000000400594 <+78>: ret End of assembler dump.(gdb) break *main+26Breakpoint 1 at 0x400560(gdb) runStarting program: /home/trupples/test-bool/stiva-neoptimizat
Breakpoint 1, 0x0000000000400560 in main ()(gdb) p/ux $ebp$6 = 0xffffe4c0(gdb) p/ux $esp$7 = 0xff7fe4b0
Registrii ebp si esp delimiteaza zona functiei curente de pe stiva. Diferenta dintre ei e de 0xffffe4c0 - 0xff7fe4b0 = 0x800010 = 8MiB si un pic.
std::vector
Documentatia c++ mentioneaza ca depinzand de implementarea bibliotecii, std::vector<bool> poate fi optimizat pentru spatiu. Deoarece containerele stdlib sunt declarate in heap, nu conteaza daca referinta la vector e pe stiva sau globala, asa ca am compilat un singur program. Functia malloc_stats va afisa informatii despre heap, inclusiv cata memorie a fost alocata. E posibil ca vectorul sa nu fie singurul lucru de pe heap, dar cu siguranta va ocupa majoritatea spatiului, alte obiecte fiind neglijabile.
#include<vector>#include<malloc.h>#include<stdio.h>int main() { fprintf(stderr, "Inainte de declararea vectorului:\n"); malloc_stats(); std::vector<bool> v(8*1024*1024); v[0] = true; v[1] = false; v[123] = true; fprintf(stderr, "\n\nDupa declararea vectorului:\n"); malloc_stats(); return v[123];}
$ g++ stdvector.cpp -o stdvector$ ./stdvectorInainte de declararea vectorului:
Arena 0:
system bytes = 204800
in use bytes = 72720
Total (incl. mmap):
system bytes = 204800
in use bytes = 72720
max mmap regions = 0
max mmap bytes = 0Dupa declararea vectorului:
Arena 0:
system bytes = 204800
in use bytes = 72720
Total (incl. mmap):
system bytes = 1257472
in use bytes = 1125392
max mmap regions = 1
max mmap bytes = 1052672
E de asteptat ca dimensiunea vectorului sa fie de 8 ori mai mica fata de ce am vazut anterior, deci in jur de 1024 * 1024 = 1048576 octeti. Se observa faptul ca intre primul malloc_stats() si al doilea declararea vectorului a alocat 1125392 - 72720 = 1052672 octeti, deci intr-adevar std::vector<bool> foloseste memoria eficient.
std::bitset
Bitset trebuie sa fie eficient din punctul de vedere al memoriei deoarece acesta este principalul lui scop. In cazul acesta nu se foloseste alocare dinamica, bitsetul rezervandu-si loc pe stiva. Dimensiunea bitsetului se poate calcula in ambele moduri folosite la sectiunea cu un vector simplu de bool-uri pe stiva.
#include<bitset>
int main() {
std::bitset<8*1024*1024> v;
v[0] = true;
v[1] = false;
v[123] = true;
return v[123];
}
$ g++ bitset.cpp -o bitset$ gdb ./bitset(gdb) break *main+27Breakpoint 1 at 0x400721(gdb) runStarting program: /home/trupples/test-bool/bitset
Breakpoint 1, 0x0000000000400721 in main ()(gdb) p/ux $esp$1 = 0xffefe4a0(gdb) p/ux $ebp$2 = 0xffffe4d0
Am folosit analiza dinamica, punand un breakpoint dupa preambul, astfel incat stiva sa fie pregatita intre adresa ebp si esp. Diferenta intre cei doi registri arata ca bitset-ul ocupa aproximativ 1MiB, dupa cum era de asteptat.
Concluzie
In concluzie, compilatorul gcc nu va optimiza pentru spatiu un tablou simplu de bool-uri, nici cu nivel de optimizare -O2, insa daca e nevoie de un tablou de bool-uri care ar depasi in mod normal limita de memorie exista doua alternative:
std::bitset, in cazul in care e destul spatiu pe stiva
std::vector<bool>, in cazul in care trebuie folosit heap-ul.
Merita mentionat faptul ca std::bitset poate fi mai incet decat std::vector<bool>: https://stackoverflow.com/a/4159130
 Dragomir Ioan (ftsl)
Dragomir Ioan (ftsl) Dispozitive de intrare/ieșire
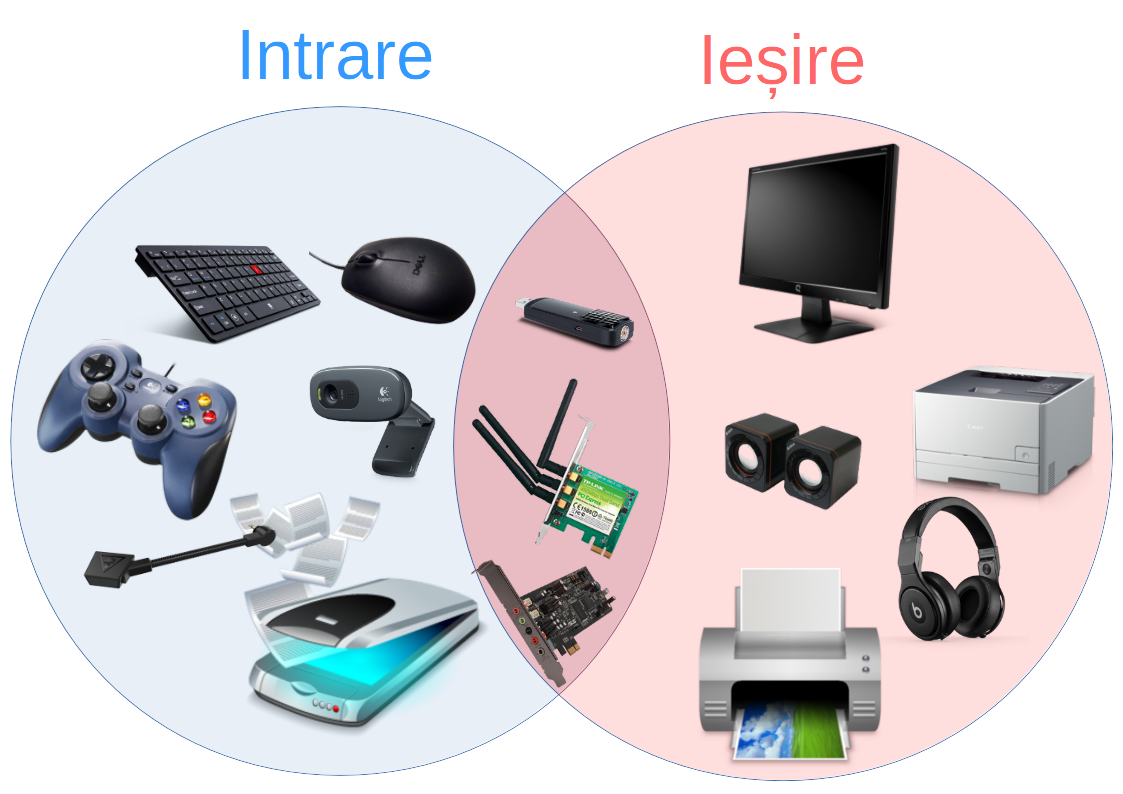
Dispozitivele de intrare/ieșire realizează transferul de informații în/din calculator.
Se împart în trei categorii:
- dispozitive de intrare
- dispozitive de ieșire
- dispozitive de intrare-ieșire
 Candale Silviu (silviu)
Candale Silviu (silviu) Tastatura

Tastatura este dispozitivul standard de intrare al calculatorului – este principalul dispozitiv periferic prin care utilizatorii pot introduce date în calculator.
Există mai multe tipuri de tastaturi. Noi folosim de regulă tastatura standard US (United States), adică tastatura standard din Statele Unite ale Americii. Tastatura standard US este similară cu următoarea:

Există și tastaturi adaptate pentru diverse țări, inclusiv România:
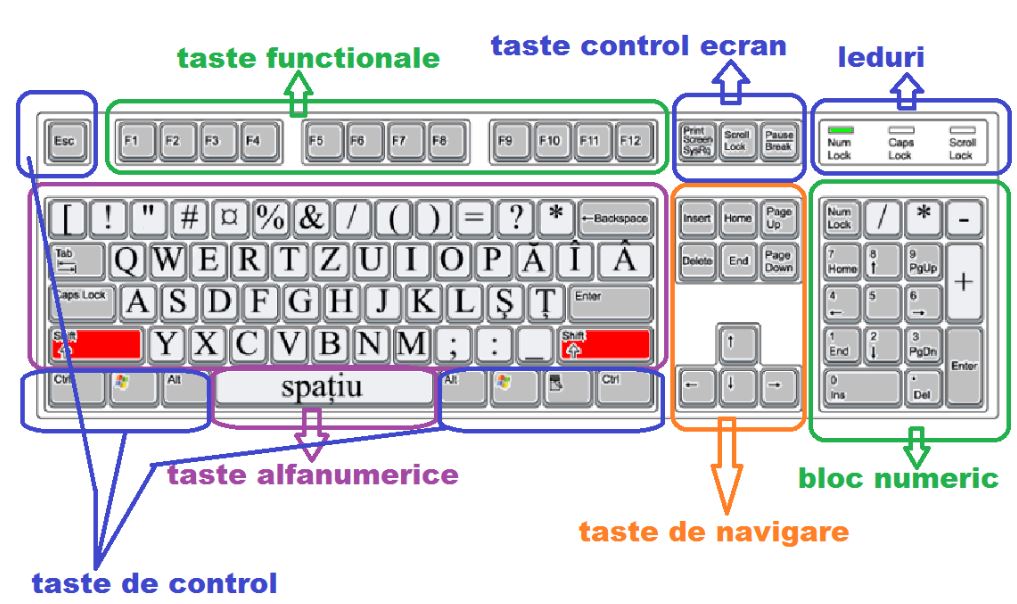
Notă: Sistemul de operare (Windows, Linux, etc.) poate fi configurat să folosească diverse aranjamente pentru tastatură. Aceasta înseamnă că putem folosi o tastatură fizică românească ca pe o tastatură standard US, sau invers. Aranjamentele de tastatură au diverse denumiri în versiunile Windows sau Linux. Aici găsiți un tutorial pentru adăugarea unui aranjament de tastatură specific limbii române pentru Windows 10.
Tastatura este compusă din peste 100 de butoane, care se numesc taste, cu diverse semnificații; unele conține caractere (litere, cifre, semne de punctuație, semne speciale), altele desemnează acțiuni (Insert, Esc, Backspace, etc).
Tastele trebuie apăsate ușor. Dacă le vom apăsa violent, tastatura se va defecta. Dacă vom ține apăsată o tastă prea mult timp, efectul va fi multiplicat (de exemplu, vor apărea mai multe litere pe ecran).
De regulă tastatura se folosește pentru scrierea unui text. Să vedem cum o folosim:
- când scriem un text, pe ecran clipește o liniuță. Ea se numește cursor de editare (pe scurt cursor) și ne arată unde va apărea caracterul corespunzător tastei apăsate;
- caracterele vor apărea pe ecran unele după altele, pe același rând. Dacă vrem să trecem la următorul rând apăsăm tasta Enter;
Ce caractere există pe tastatură?
- literele mici ale alfabetului englez:
a b c d ... x y z– sunt26de litere mici - literele mici ale alfabetului englez:
A B C D ... X Y Z - spațiul: se scrie cu tasta Space – tasta lungă din partea de jos a tastaturii
- cifrele:
0 1 2 3 4 5 6 7 8 9 - semne de punctuație:
. , ; : " ' ` ! ? - operatori matematici:
+ - = * / - paranteze:
() {} [] - caractere speciale:
~,$,#,%,^,&,_,\,|,@
- semne de punctuație:
Cum scriem literele?
- pentru scrie literele mici, apăsăm tastele corespunzătoare (A, B, C, etc);
- pentru a scrie literele mari, ținem apăsată tasta Shift și apăsăm tasta corespunzătoare literei dorite(Shift+A, Shift+B, Shift+C, etc.);
- dacă activăm tasta Caps Lock, semnificația tastelor literă se schimbă: când apăsă o tastă literă se va scrie litera mare, când apăsăm Shift și tasta literă se va scrie litera mică corespunzătoare;
- pentru a separa cuvintele, folosim tasta Space;
- pentru a insera un spațiu mai mare, folosim tasta Tab. Aceasta poate fi folosită și pentru unele alinieri;
Cum scriem alte caractere?
- unele taste conțin câte două caractere – de exemplu
1și!: pe acestea le vom scrie astfel:- caracterul de jos – în exemplu
1– se va scrie apăsând direct tasta corespunzătoare, 1; - caracterul de jos – în exemplu
!– se va scrie apăsând Shift și tasta corespunzătoare: în exemplu Shift+1;
- caracterul de jos – în exemplu
Cum ștergem caractere scrise?
- când apăsăm tasta Backspace se șterge caracterul din stânga cursorului;
- când apăsăm tasta Delete se șterge caracterul din stânga cursorului;
Cum mutăm cursorul în text?
- cea mai simplă formă de a muta cursorul în text este să facem click cu mouse-ul în poziția dorită;
- tastele cu săgeți se folosesc pentru deplasarea cursorului în text, pe direcția indicată de acestea: la stânga, la dreapta, în sus sau în jos;
- tastele Home, End, Page Up, Page Down deplasează și ele cursorul în text, astfel:
- Home mută cursorul la începutul rândului
- End mută cursorul la sfârșitul rândului
- Page Up mută cursorul cu un ecran mai sus
- Page Down mută cursorul cu un ecran mai jos
- dacă apăsăm tasta Ctrl și săgețile sau Home, End, Page Up, Page Down, cursorul se va deplasa mai repede pe direcția dorită. Încercați singuri!
Cum folosim scurtături?
- tastele Shift, Ctrl și Alt se numesc taste reci. De regulă, simpla apăsare a lor nu are efect. Ele se folosesc în combinație cu alte taste, obținând scurtături (shortcut).
- semnificația scurtăturilor depinde de programul în care lucrăm. Totuși, există o serie de scurtături universale, valabile în foarte multe programe:
- Ctrl+C – copiază într-o memorie specială (Clipboard) un obiect selectat. Acesta poate fi un fișier, un bloc de text o bucată dintr-o imagine. Obiectele din Clipboard pot fi apoi lipite cu Ctrl+V.
- Ctrl+A – selectează to textul
- Ctrl+S – salvează fișierul deschis
- Ctrl+O – deschide un fișier
- F1 – de regulă afișează informații despre programul folosit
- Alt+F4 – închide fereastra curentă
- Alt+Tab – comută între ferestrele deschise
Resurse online
Recursivitate
Recursivitatea reprezintă proprietatea unor noțiuni de a se defini prin ele însele.
Exemple:
- factorialul unui număr: \( N! = N \cdot (N-1)! \);
- ridicarea la putere: \( a^n = a \cdot a^{n-1} \);
- termenul unei progresii aritmetice: \( a_n = a_{n-1} + r \);
- șirul lui Fibonacci: \( F_n = F_{n-1} + F_{n-2} \);
- etc.
Să observăm că aceste reguli nu se aplică întotdeauna. Dacă ar fi așa, pentru \( 3! \) am obține:
\(3! = 3 \cdot 2!\), \(2! = 2 \cdot 1!\), \(1! = 1 \cdot 0!\), \(0! = 0 \cdot (-1)!\)
De aici am putea deduce că \( 0! = 0\) și înlocuind în relațiile de mai sus obținem că \( n! = 0\), pentru orice număr natural \( n \). Bineînțeles, nu este corect. De fapt, formula recursivă pentru \( n! \) se aplică numai pentru \( n > 0 \), iar prin definiție \( 0! = 1\) .
Astfel, identificăm următoarea definiție pentru \( n! \), acum completă: \( n! = \begin{cases}
1& \text{dacă } n = 0,\\
n \cdot (n-1)!& \text{dacă } n > 0.
\end{cases} \)
Similar, pentru toate formulele de mai sus exista cel puțin o situație în care formula recursivă nu se mai poate aplica, iar rezultatul se determină în mod direct.
În C++, recursivitatea se realizează prin intermediul funcțiilor, care se pot autoapela.
Ne amintim că o funcție trebuie definită iar apoi se poate apela. Recursivitatea constă în faptul că în definiția unei funcție apare apelul ei însăși. Acest apel, care apare în însăși definiția funcției, se numește autoapel. Primul apel, făcut în altă funcție, se numește apel principal.
Exemplu C++
Să scriem o funcție C++ care returnează factorialul unui număr natural transmis ca parametru. Varianta nerecursivă (iterativă) este următoarea:
int fact(int n){
int p = 1;
for(int i = 1 ; i <= n ; i ++)
p = p * i;
return p;
}
Să observăm că această funcție determină rezultatul corect pentru valori ale lui n mai mari sau egale cu 0 (valori mici, practic n <= 12). Funcția determină corect rezultatul și pentru n == 0.
O variantă recursivă pentru determinarea lui n!, care folosește observațiile de mai sus, este:
int fact(int n){
if(n == 0)
return 1;
else
return n * fact(n-1);
}
Cum funcționează recursivitatea?
Ne amintim că toate variabilele locale din definiția unei funcții precum și valorile parametrilor formali se memorează la apel în memoria de tip STIVĂ (STACK).
Pentru fiecare apel al unei funcții se adaugă pe stivă o zonă de memorie în care se memorează variabilele locale și parametrii pentru apelul curent. Această zonă a stivei va exista până la finalul apelului, după care se va elibera. Dacă din apelul curent se face un alt apel, se adaugă pe stivă o nouă zonă de memorie, iar conținutul zonei anterioare este inaccesibil până la finalul acelui apel. Aceste operații se fac la fel și dacă al doilea apel este un autoapel al unei funcții recursive.
Să considerăm acum următoarea secvență:
int fact(int n){
int f;
if(n == 0)
return 1;
else
f = fact(n - 1) * n;
return f;
}
int main(){
int x = fact(3);
cout << x;
return 0;
}
Să urmărim pas cu pas execuția acestui program:
| Pas | Conținut stivă | Observații |
|---|---|---|
int x = |
x = ?? | În zona curentă a stivei se alocă memorie pentru variabila x. Să o numim Zona 0. |
fact(3) |
Zona 1: n = 3, f = 3 * fact(2) = ?? Zona 0: x = ?? | În apelul principal are loc autoapelul fact(3). Se alocă o nouă zonă pe stivă, pentru acest apel, Zona 1. Deoarece n>0, are loc apelul fact(2). |
fact(2) |
Zona 2: n = 2, f = 2 * fact(1) = ?? Zona 1: n = 3, f = 3 * fact(2) = ?? Zona 0: x = ?? | În Zona 1 a stivei se face autoapelul fact(2). Se alocă o nouă zonă pe stivă, pentru acest apel, Zona 2. Deoarece n>0, are loc autoapelul fact(1). |
fact(1) |
Zona 3: n = 1, f = 1 * fact(0) = ?? Zona 2: n = 2, f = 2 * fact(1) = ?? Zona 1: n = 3, f = 3 * fact(2) = ?? Zona 0: x = ?? | În Zona a stivei se face autoapelul fact(1). Se alocă o nouă zonă pe stivă, pentru acest apel, Zona 3. Deoarece n>0, are loc autoapelul fact(0). |
fact(0) |
Zona 4: n = 0, f = 1 Zona 3: n = 1, f = 1 * fact(0) = ?? Zona 2: n = 2, f = 2 * fact(1) = ?? Zona 1: n = 3, f = 3 * fact(2) = ?? Zona 0: x = ?? | În Zona 3 a stivei se face autoapelul fact(0). Se alocă o nouă zonă pe stivă, pentru acest apel, Zona 4. Suntem în cazul particular și nu mai are loc autoapelul. Rezultatul autoapelului fact(0) este 1. Zona 4 se eliberează. |
fact(1) |
Zona 3: n = 1, f = 1 * 1 = 1 Zona 2: n = 2, f = 2 * fact(1) = ?? Zona 1: n = 3, f = 3 * fact(2) = ?? Zona 0: x = ?? | Se revine în apelul fact(1), adică în Zona 3. Se calculează f=1 și se termină și autoapelul fact(1) cu valoarea 1. Se eliberează Zona 3. |
fact(2) |
Zona 2: n = 2, f = 2 * 1 = 2 Zona 1: n = 3, f = 3 * fact(2) = ?? Zona 0: x = ?? | Se revine în apelul fact(2), adică în Zona 2. Se calculează f=2 și se termină și autoapelul fact(2) cu valoarea 2. Se eliberează Zona 2. |
fact(3) |
Zona 1: n = 3, f = 3 * 2 = 6 Zona 0: x = ?? | Se revine în apelul fact(3), adică în Zona 1. Se calculează f=6 și se termină și autoapelul fact(3) cu valoarea 6. Se eliberează Zona 1. |
cout << x; return 0; |
Zona 0: x = 6 | Se revine în apelul funcției main, adică în Zona 0. Se calculează x=6 și se afișează această valoare. După instrucțiunea return 0; se eliberează Zona 0. Execuția programului se încheie. |
Observații: La fiecare apel al funcției fact avem variabilele n și f. Ele însă sunt variabile diferite, cu valori diferite, memorate în zone diferite ale stivei. La un moment dat, se pot folosi numai variabilele din zona de memorie curentă, cea din “vârful” stivei.
Observații
- este obligatoriu ca în definiția unei funcții recursive să apară cazul particular (în care să nu aibă loc autoapelul). În caz contrar autoapelurile vor avea loc “la nesfârșit”. De fapt, în urma prea multor autoapeluri, stiva se va ocupa în totalitate și execuția programului se va întrerupe.
- este obligatoriu ca, pentru cazurile neelementare, valorile la autoapel a parametrilor să se apropie de valorile din cazul elementar. Altfel se va întâmpla situația descrisă mai sus: stiva se va ocupa în totalitate și programul se va opri, fără a determina/afișa rezultatele dorite :).
Cum facem autoapelul?
Autoapelul se face în conformitate cu antetul funcției recursive. Astfel:
- dacă funcția recursivă este de tip non-void, autoapelul se va face într-o expresie;
- dacă funcția recursivă este de tip void, autoapelul se va face într-o instrucțiune de sine stătătoare; dacă funcția întoarce valori, se vor folosi parametri de ieșire.
Exemple:
| Funcție de tip void | Funcție de tip non-void |
|---|---|
void fact(int n, int &r){
if(n == 0)
r = 1;
else{
fact(n - 1 , r);
r = r * n;
}
}
int main(){
int a;
fact(4, a);
cout << a;
return 0;
}
|
int fact(int n){
int r;
if(n == 0)
r = 1;
else
r = n * fact(n - 1);
return r;
}
int main(){
int a;
a = fact(4);
cout << a;
return 0;
}
|
Alte formule recursive
- calculul combinărilor: \( {n \choose k} = \begin{cases}
1& \text{dacă } n = k \text{ sau } k = 0,\\
{ {n-1} \choose {k-1} } + { {n-1} \choose k } & \text{altfel}.
\end{cases} \), unde \( n \choose k \) înseamnă “combinări denluate câtek”
- calculul combinărilor: \( {n \choose k} = \begin{cases}
1& \text{dacă } k = 0,\\
\frac{n – k + 1}{k} \cdot { n \choose {k-1} } & \text{altfel}.
\end{cases} \)
- cel mai mare divizor comun a două numere: \( cmmdc(a,b) = \begin{cases}
a& \text{dacă } b = 0,\\
cmmdc(b , a \% b) & \text{dacă } b > 0.
\end{cases} \)
- operații cu cifrele unui număr natural, de exemplu:
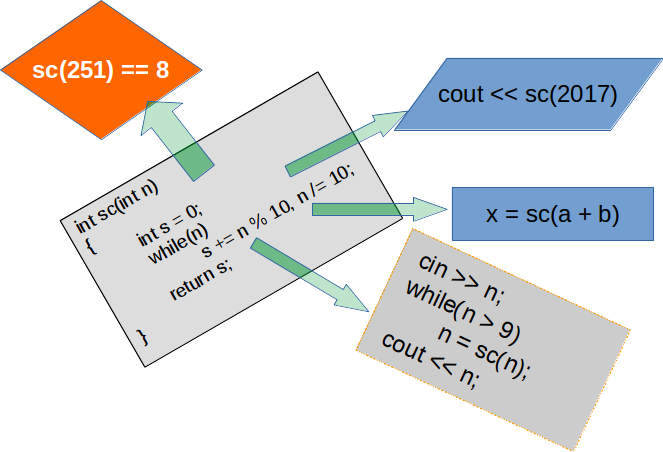
- suma cifrelor: \( sumcif(n) = \begin{cases}
n& \text{dacă } n < 10,\\
n \% 10 + sumcif(n/10) & \text{dacă } n \geqslant 10.
\end{cases} \) - numărul de cifre: \( nrcif(n) = \begin{cases}
1& \text{dacă } n < 10,\\
1 + nrcif(n/10) & \text{dacă } n \geqslant 10.
\end{cases} \) - cifra maximă: \( cifmax(n) = \begin{cases}
n& \text{dacă } n < 10,\\
max(n \% 10 , cifmax(n/10)) & \text{dacă } n \geqslant 10.
\end{cases} \)
- suma cifrelor: \( sumcif(n) = \begin{cases}
Tipuri de recusivitate
- recursivitate directă: în definiția funcției
Fapare apelul funcțieiF; - recursivitate indirectă: în definiția funcției
Fapare apelul funcțieiG, iar în definiția funcțieiGapare apelul luiF.
Fun

Dacă v-a plăcut imaginea de mai sus, căutați pe net droste effect
Subprograme
Un subprogram este o colecție de tipuri de date, variabile, instrucțiuni care îndeplinesc o anumită sarcină (calcule, citiri, afișări), atunci când este apelat (folosit) de un program sau de un alt subprogram.
Pentru a înțelege conceptul de subprogram, să considerăm două probleme:
Problema 1: Se dau două numere naturale n și m. Să se determine suma dintre oglinditul lui n și oglinditul lui m.
Până acum, pentru a rezolva această problemă, trebuia să determinăm, folosind două secvențe de program aproape identice, oglinditele celor două numere, iar apoi să facem suma. O soluție mai simplă este să construim un subprogram care determină oglinditul unui număr natural oarecare, să-l apelăm de două ori pentru a determina oglinditul lui n și al lui m, apoi să facem suma rezultatelor.
Problema 2: Se citește un tablou cu n elemente, numere întregi. Să se ordoneze crescător elementele tabloului și apoi să se afișeze.
Putem rezolva această problemă, în mai multe moduri, folosind cunoștințe pe care le avem deja. Dacă dorim să o rezolvăm folosind subprograme, vom construi trei subprograme:
citire– care citește elementele vectoruluisortare– care ordonează elementele vectoruluiafisare– care afișează elementele vectorului
Astfel, programul care rezolvă problema constă în apelul celor trei subprograme, în ordinea potrivită. Am reușit să descompunem rezolvarea unei probleme complexe în mai multe subprobleme, mai simple, care pot fi rezolvate de mai multe persoane, dacă este cazul.
Constatăm că utilizarea subprogramelor are câteva avantaje:
- reutilizarea codului – după ce am scris un subprogram îl putem apela (folosi) de oricâte ori este nevoie;
- modularizarea programelor – subprogramele ne permit să împărțim problema dată în mai multe subprobleme, mai simple;
- reducerea numărului de erori care pot să apară în scrierea unui program
- depistarea cu ușurință a erorilor – fiecare subprogram va fi verificat la crearea sa, apoi verificăm modul în care apelăm subprogramele
Subprogramele pot fi de două tipuri:
- funcții – subprograme care determină un anumit rezultat, o anumită valoare, pornind de la anumite date de intrare. Spunem că valoarea este returnată de către funcție, iar aceasta va fi apelată ca operand într-o expresie, valoarea operandului în expresie fiind de fapt valoarea rezultatului funcției.
- proceduri – subprograme care se folosesc într-o instrucțiune de sine stătătoare, nu într-o expresie. Ele îndeplinesc o sarcină, au un efect și nu returnează un rezultat. De exemplu, citirea unor variabile, afișarea unor valori, transformarea unor date, etc.
În limbajul C/C++, există doar subprograme de tip funcție. Pentru proceduri se folosește o formă particulară a funcțiilor.
Căutarea binară
Introducere
Căutarea unei valori într-un vector se poate face în două moduri:
- secvențial – presupune analizarea fiecărui element al vectorului într-o anumită ordine (de obicei de la stânga la dreapta). Când se găsește valoarea căutată parcurgerea vectorului se poate opri. În cel mai rău caz, pentru un vector cu
nelemente parcurgerea facenpași, complexitatea timp a căutării secvențiale esteO(n) - binar. Căutarea binară se poate face într-un vector numai dacă elementele acestuia sunt în ordine (de obicei crescătoare) după un anumit criteriu (de obicei criteriul este chiar relația de ordine naturală între numere, cuvinte, etc). Căutarea binară presupune împărțirea vectorului în secvențe din ce în ce mai mici, înjumătățindu-le și continuând cu jumătatea în care se poate afla valoarea dorită (conform ordinii elementelor din vector).
Algoritm pseudocod
Algoritmul căutării binare este următorul:
Date de intrare:
- un vector
v[]cunelemente, indexate de la1lan, ordonate crescător și o valoarexcare se va căuta.
Date de ieșire:
- un indice
pozdacă valoareaxapare în vectorulv[]sau0în caz contrar.
Algoritm pseudocod:
st ← 1
dr ← n
poz ← 0
CÂTTIMP st≤dr SI poz=0 EXECUTĂ
m ← (st + dr) DIV 2
DACĂ v[m] = x ATUNCI
poz = m
ALTFEL
DACĂ v[m] < x ATUNCI
st ← m + 1
ALTFEL
dr ← m - 1
SFDACĂ
SFDACĂ
SFCÂTTIMP
DACĂ poz≠0 ATUNCI
// x apare în vector pe poziția poz
ALTFEL
// x nu apare în vector
SFDACĂ
Notă: În algoritmul de mai sus a DIV b reprezintă câtul împărțirii lui a la b, iar cu V ← EXPR s-a notat atribuirea la variabila V a rezultatului expresiei EXPR.
Altă variantă a căutării binare
De multe ori nu este suficient să știm dacă o valoare dată apare sau nu în vector. Sunt numeroase situații în care trebuie să aflăm un indice al vectorului (element al vectorului) care respectă o anumită condiție în raport cu valoarea dată. De exemplu:
- să se determine cel mai mare indice
pozpentru carev[poz] ≤ x; - să se determine cel mai mare indice
pozpentru carev[poz] < x; - etc.
Algoritmul de mai jos determină cel mai mare indice poz pentru care v[poz] ≤ x. El poate fi folosit și pentru a verifica dacă x apare în vector, astfel: dacă la final v[poz] = x, atunci x apare în vector, in caz contrar nu apare.
st ← 1
dr ← n
poz ← n + 1
CÂTTIMP st ≤ dr EXECUTĂ
m ← (st + dr) DIV 2
DACĂ v[m] ≥ x ATUNCI
poz ← m
dr ← m - 1
ALTFEL
st ← m + 1
SFDACĂ
SFCÂTTIMP
DACĂ v[poz] = x ATUNCI
// x apare în șir pe poziția poz
ALTFEL
// x nu apare în șir (în acest caz, v[poz] > x)
SFDACĂ Șmenul lui Mars - Difference Array
Șmenul lui Mars în vector
Să presupunem că avem un vector A[] cu n elemente, indexate de la 1 la n, inițial nule, în care se fac mai multe operații Adună(s,d,X) prin care toate elementele din secvența delimitată de indicii s d cresc cu valoarea X. Se cere afișarea elementelor din A după efectuarea acestor operații.
Metoda descrisă în continuare este cunoscută în lumea olimpicilor la informatică sub numele de “Șmenul lui Mars”, atribuită fostului olimpic Marius Andrei. De asemenea, se regăsește sub numele “Difference Array”, de exemplu pe www.geeksforgeeks.org. Vezi Șmenul lui Mars pe infoarena.ro!
Operațiile pot fi efectuate eficient construind un vector suplimentar B[], cu n+1 elemente, astfel încât A[i]=B[1]+B[2]+...+B[i]. Vectorul A[] este vector de sume parțiale pentru vectorul B[].
Operația Adună(s,d,X) devine:
B[s] += X; B[d+1] -= X;
La final, elementele lui A se reconstituie astfel: A[i]=B[1]+B[2]+...+B[i]
A[1] = B[1];
for(int i = 2 ; i <= n ; i ++)
A[i] = A[i-1] + B[i];
Șmenul lui Mars în matrice
Cunoscută și sub denumirea de Șmenul lui Mars 2D, această tehnica se aplică în rezolvarea problemelor la care se cere, pentru o matrice dată A[][] mărirea cu o valoare dată X a tuturor elementelor din submatricea determinată de colțul stânga-sus (i1,j1) și colțul dreapta-jos (i2,j2). Această operație se aplică de mai multe ori, pentru diverse submatrice și diverse valori ale lui X și se cere determinarea elementelor din A[][] după aceste operații.
Putem proceda similar ca în cazul unidimensional, construind o matrice suplimentară M[][], astfel incât matricea A[][] reprezintă matrice de sume parțiale pentru M[][].
Operațiile date devin:
M[i1][j1] += x; M[i1][j2+1] -= x; M[i2+1][j1] -= x; M[i2+1][j2+1] += x;
Observații:
- Matricea
M[][]are cu o linie și o coloană mai mult decât matriceaA[][]. - Fiecare operație prin care se măresc elementele dintr-o submatrice are complexitate constantă.
Exemplu
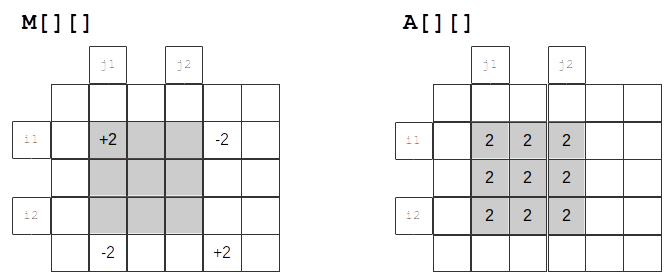
Refacerea matricei A[][] se face ținnând cont de faptul că este matrice de sume parțiale pentru M[][]:
for(int i = 1 ; i <= n ; i ++) for(int j = 1; j <= m ; j ++) A[i][j] = M[i][j] + A[i-1][j] + A[i][j-1] - A[i-1][j-1];
Ciurul lui Eratostene
Introducere
Ciurul lui Eratostene reprezintă o metodă de determinare a tuturor numerelor prime mai mici sau egale cu o valoare dată, n. În practică, valoarea lui n trebuie să fie una rezonabilă, ea depinzând de restricțiile de timp și memorie aplicate problemei.
Ciurului Eratostene se aplică în felul următor – în continuare lucrăm cu n=30:
- se scriu toate numerele naturale de la
1lan=30:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- se taie din lista numărul
1, care nu este prim
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- se identifică următorul număr netăiat,
2. Acest este prim, iar din listă se vor tăia toți multipli săi, mai mari decât acesta.
| 2 | 3 | 5 | 7 | 9 | |||||
| 11 | 13 | 15 | 17 | 19 | |||||
| 21 | 23 | 25 | 27 | 29 |
- se identifică următorul număr netăiat,
3. Acest este prim, iar din listă se vor tăia toți multipli săi, mai mari decât acesta. Unii dintre ei au fost deja tăiați, deoarece sunt și multipli ai lui2.
| 2 | 3 | 5 | 7 | ||||||
| 11 | 13 | 17 | 19 | ||||||
| 23 | 25 | 29 |
- se identifică următorul număr netăiat,
5. Acest este prim, iar din listă se vor tăia toți multipli săi, mai mari decât acesta. Unii dintre ei au fost deja tăiați, deoarece sunt și multipli ai lui2sau3.
| 2 | 3 | 5 | 7 | ||||||
| 11 | 13 | 17 | 19 | ||||||
| 23 | 29 |
- se identifică următorul număr netăiat,
7. Acesta este prim, dar totodată7*7>30căutarea numerelor prime s-a încheiat. Toate numerele care nu au fost tăiate sunt prime.
Animație
Algoritm
Pentru identificarea numerelor prime într-un algoritm/program, vom folosi un vector caracteristic, v[], cu următoarea semnificație:
\( v[x]=\begin{cases} 0& \text{dacă $x$ prim},\\1& \text{dacă $x$ nu este prim}.\end{cases} \)
Vom porni de la un vector cu toate elementele nule, apoi vom marca pe rând cu 1 toate numerele care sunt multipli ai unor numere mai mici. Un algoritm pseudocod care realizează acest operații este:
pentru i←0,n execută
V[i] ← 0
sf_pentru
V[0] ← 1
V[1] ← 1
pentru i ← 2,sqrt(n) execută
dacă V[i] = 0 atunci
pentru j ← 2, [n/i] execută
V[i*j] ← 1
sf_pentru
sf_dacă
sf_pentru
Probleme similare
Mecanismul prin care se identifică numerele prime specific Ciurului lui Eraostene poate fi folosit și la determinarea altor rezultate. De exemplu, vrem să aflăm pentru un n dat (nu prea mare) câți divizori are fiecare număr natural din intervalul [1,n].
Pentru acesta, vom construi un vector V, în care v[x] reprezintă numărul de divizori ai lui x. Pentru a construi acest vector, vom parcurge numerele de la 1 la n, și pentru fiecare număr x vom identifica multiplii săi. Pentru fiecare y multiplu al lui x vom incrementa valoarea lui v[y].
Un algoritm pseudocod este:
pentru i←1,n execută
V[i] ← 0
sf_pentru
pentru x ← 1,n execută
pentru y ← x, n , x execută
V[y] ← V[y] + 1
sf_pentru
sf_pentru
Algoritmul lui Prim
Considerăm un graf neorientat ponderat (cu costuri) conex G. Se numește arbore parțial un graf parțial al lui G care este arbore. Se numește arbore parțial de cost minim un arbore parțial pentru care suma costurilor muchiilor este minimă.
Dacă graful nu este conex, vorbim despre o pădure parțială de cost minim.
Algoritmul lui Prim permite determinarea unui arbore parțial de cost minim (APM) într-un graf ponderat cu N noduri.
Descrierea algoritmului
Determinarea APM-ului se face astfel:
- se stabilește un nod de plecare; acesta va fi rădăcina arborelui, care se va crea pas cu pas, prin adăugarea de noi noduri;
- în mod repetat:
- se alege un nod neadăugat încă în arborele curent pentru care muchia dintre el și un nod din arbore are cost minim;
- se adăugă nodul în arbore;
- când nu se mai poate face alegerea unui asemenea nod, fie au fost adăugate toate nodurile, fie graful nu este conex și au fost adăugate în arbore toate nodurile din componenta conexă a nodul inițial;
- dacă graful nu este conex, continuăm cu următoarea componentă conexă.
Observație: arborele parțial de cost minim al unui graf neorientat nu este unic, însă toate APM-urile vor avea același cost.
Exemplu
Mai jos este descris modul în care se aleg nodurile care se adaugă în arbore pentru un graf ponderat cu N=9 noduri:
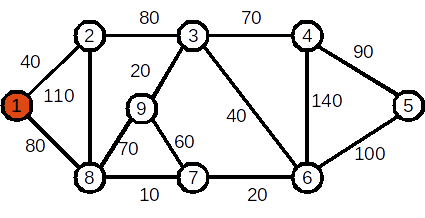
Nodul ințial este 1. Costul curent al APM este 0
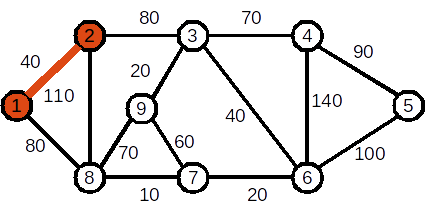
Se adaugă nodul 2. Muchia folosită este (1,2). Costul curent al APM este 40
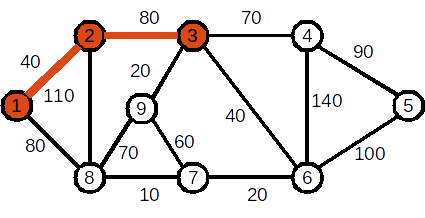
Se adaugă nodul 3. Muchia folosită este (2,3). Costul curent al APM este 120
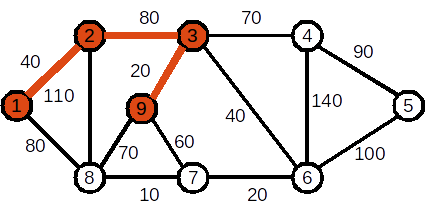
Se adaugă nodul 9. Muchia folosită este (3,9). Costul curent al APM este 140
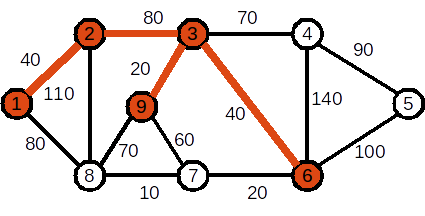
Se adaugă nodul 6. Muchia folosită este (3,6). Costul curent al APM este 180
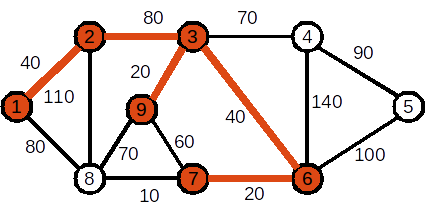
Se adaugă nodul 7. Muchia folosită este (6,7). Costul curent al APM este 200
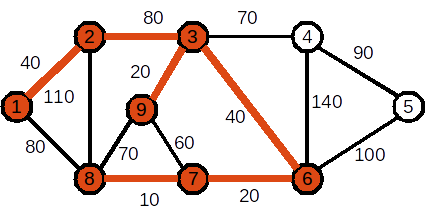
Se adaugă nodul 8. Muchia folosită este (7,8). Costul curent al APM este 210
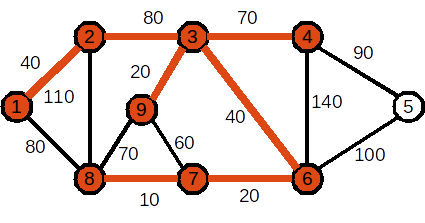
Se adaugă nodul 4. Muchia folosită este (3,4). Costul curent al APM este 280
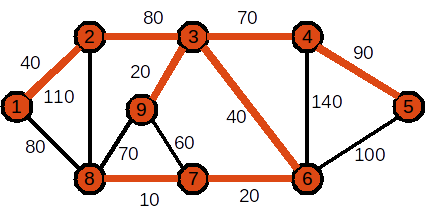
Se adaugă nodul 5. Muchia folosită este (4,5). Costul curent al APM este 370
Algoritmul poate fi implementat în mai multe moduri, cu complexități diferite.
Varianta \(N^3\)
- în mod repetat (de cel mult
N-1ori):- se aleg două noduri adiacente, un nod din arbore și un nod din afara acestuia, astfel încât muchia determinată de cele două noduri să aibă costul minim
- nodul ales din afara arborelui curent se va adăuga în arbore
Varianta \(N^2\)
Față de varianta anterioară se evită căutarea propriu zisă a nodului din arbore, căutându-se efectiv numai nodul din afara acestuia. Pentru aceasta se păstrează un șir d[] cu următoarea semnificație: pentru un nod k încă neadăugat în arbore, d[k] reprezintă costul minim al unei muchii având o extremitate k și o extremitate în arbore; dacă o asemenea muchie nu există d[k] = INFINIT.
Dacă determinarea succesivă a nodurilor din afara arborelui se face prin parcurgerea șirului d[], complexitatea devine O(N2).
Varianta \(N \log N\)
Se poate evita parcurgerea șirului d[] prin memorarea nodurilor din arbore într-o structură de date de tip heap, în vârful heap-ului fiind nodul k pentru care d[k] are valoare minimă. În acest fel complexitatea algoritmului devine O(N logN).
Vezi și
Baze de date
Introducere
O bază de date este o colecție de date care modelează un univers (instituție, organizație, eveniment, etc.). Acest univers este format din mai multe elemente care interacționează, elementele de același tip făcând parte dintr-o entitate. Fiecare entitate are anumite atribute și conține mai multe elemente; fiecare element al unei entități are același set de atribute, dar elementele diferă între ele prin valorile atributelor.
Exemplu
Pentru gestionarea unei școli se va folosi o bază de date cu numele scoala. Entitățile care fac parte din această bază de date sunt (cel puțin) ELEV, PROFESOR, CLASE:
- entitatea ELEV va conține informații despre fiecare elev;
- entitatea PROFESOR va conține informații despre fiecare profesor din școală;
- entitatea CLASA va conține informații despre fiecare clasă;
Fiecare entitate va avea (cel puțin) următoarele atribute:
ELEV
nume
prenume
data_nasterii
PROFESOR
nume
prenume
vechime
adresa
email
CLASA
denumire
nivel_invatamant
specializare
Desigur, elevii și profesorii pot avea și alte caracteristici (număr la pantof, preferințe muzicale), dar acestea nu sunt relevante pentru școală. Atributele entităților vor corespunde proprietăților relevante pentru universul descris de baza de date.
Elementele acestor entități pot fi privite astfel:
ELEV
| nume | prenume | data_nasterii |
|---|---|---|
| Marin | Gheorghe | 2007-12-25 |
| Andreescu | Ionela | 2002-10-06 |
| Pop | Constantin | 2006-04-12 |
| Ionescu | Flavia | 2008-07-19 |
PROFESOR
| nume | prenume | vechime | adresa | |
|---|---|---|---|---|
| Rus | Daniel | 25 | București, str. Florilor, 5 | rus.daniel@mail.ro |
| Georgescu | Clara | 7 | clara@cnrr.ro | |
| Man | Sebastian | 17 |
CLASA
| denumire | nivel | specializare |
|---|---|---|
| 12 A | 12 | Matematică-informatică |
| 8 B | 8 | |
| 10 D | 10 | Științele naturii |
Entitatea corespunde tabelului.
Atributele corespund coloanelor din tabel.
Elementele corespund liniilor din tabel.
Sistem de gestiune a bazelor de date

Un Sistem de Gestiune a Bazelor de Date (SGBD) este o aplicație software care realizează o serie de operații specifice cu bazele de date:
- crearea bazei de date
- ștergerea, modificarea, importul/exportul bazei de date
- crearea unei entități
- gestionarea atributelor unei entități: adăugare, modificare, ștergere
- gestionarea elementelor unei entități: adăugare, modificare, ștergere
- controlul accesului
- etc.
De-a lungul timpului au fost implementate mai multe modele pentru bazele de date. În prezent este (încă) folosit pe scară largă modelul relațional. În acest model, entitățile sunt privite ca niște mulțimi, având ca elemente înregistrările. Astfel, într-o entitate nu putem avea mai multe înregistrări cu exact aceleași valori ale atributelor (ar exista mai multe elemente egale în mulțime), iar cu entitățile (sau parte a lor) se pot face operații de reuniune, intersecție, specifice mulțimilor.
Exemple de SGBD-R – sisteme de gestiune a bazelor de date relaționale: MySQL, Microsoft SQL Server, Microsoft Access, Oracle, SQLite.
Terminologie
Diversele sisteme de gestiune a bazelor de date folosesc termeni diferiți pentru conceptele specifice bazelor de date. În continuare prezentăm o listă de noțiuni sinonime, într-o ordine ierarhică:
- baza de date
- entitate, tabel, tabelă
- structura unei entități: atribut, câmp, coloană
- datele dintr-o entitate: elemente, instanțe, înregistrări, linii
Cheie, cheie primară, chei străină
Fiecare valoare din baza de date trebuie să fie accesibilă. Orice valoare din baza de date se află într-o entitate și este valoare corespunzătoare unui anumit atribut al unui anumit element.
Entitățile și atributele pot fi identificate prin numele lor, dar elementele entității nu au nume. Pentru a le identifica a fost realizat un alt mecanism de identificare, numit cheie.
O cheie este un atribut sau ansamblu de atribute dintr-o entitate care identifică elemente unei entități.
O cheie primară este un atribut al unei entități (sau ansamblu de atribute) care are valori unice pentru fiecare element al entității. Astfel, cheia primară identifică în mod unic fiecare element al entității din care face parte. Pentru a facilita operațiile cu date, fiecare entitate trebuie să aibă o cheie primară.
Este posibil ca o entitate să aibă mai multe atribute (grupuri de atribute) cu valori unice la nivelul entității, dar numai una poate fi aleasă ca fiind cheie primară, celelalte sunt chei candidat. De exemplu, pentru persoane există codul numeric personal și seria/numărul cărții de identitate. Doar una dintre ele poate fi cheie primară, cealaltă find cheie candidat.
O cheie primară este:
- obligatorie – fiecare entitate are o singură cheie primară
- unică – nu există două elemente ale entității cu aceleași valori ale cheii primare
- simplă sau compusă – o cheie primară simplă este un singur atribut al entității. O cheie primară compusă cuprinde mai multe atribute ale entității
- non null – valoarea cheii primare nu poate fi vidă
- stabilă – după ce au fost create, valorile cheilor primare se schimbă foarte rar
- ne-reutilizabilă – dacă se șterge un element al entității, nu se asociază altui element valoarea cheii primare a elementului șters
Pentru a stabili legături între entități se folosește un mecanism numit chei străine. O cheie străină are următoarele caracteristici:
- este un atribut al unei entități ale cărui valori sunt în relație cu valorile dintr-o altă entitate;
- asigură faptul că elementele unei entități au elemente corespondente în altă entitate;
- respectă reguli de integritate: valorile cheii străine dintr-o entitate sunt chei primare în altă entitate.
Atribute obligatorii și opționale. Valoarea NULL
Observăm că atributele cheie primară și cheie străină sunt obligatorii – pentru fiecare element al entității trebuie să fie cunoscută valoarea sa. Există și alte atribute obligatorii: fiecare elev șî fiecare profesor au nume, prenume, data nașterii, dar există și atribute care nu sunt obligatorii. Poate nu este obligatoriu să fie cunoscută adresa tuturor profesorilor și este posibil ca nu toți profesorii să aibă adrese de email.
Constatăm astfel că atributele unei entități pot fi:
- obligatorii – pentru fiecare element al entității trebuie să fie cunoscută valoarea atributelor obligatorii;
- opționale
- valoarea acestor atribute este cunoscută doar pentru a parte a elementelor. De exemplu, doar o parte a profesorilor au o adresă de email;
- atributele au sens doar pentru anumite elemente ale entității. De exemplu, data căsătoriei au sens numai pentru profesorii căsătoriți.
Pentru atributele opționale putem avea valoarea NULL.
NULL = constantă care desemnează o valoare necunoscută sau inaplicabilă.
Reprezentarea atributelor unei entități se face astfel:
- atributele sunt scrise cu litere mici, fiecare pe câte o linie;
- atributele cheie primară sunt precedate de caracterul #;
- atributele obligatorii sunt precedate de caracterul *;
- atributele opționale sunt precedate de caracterul ∘.
Exemplu
Considerăm baza de date scoala. Fiecare entitate va fi înzestrată cu o cheie primară. O modalitate frecvent folosită constă în adăugarea unui câmp suplimentar (id), valorile sale fiind independente de valorile celorlalte atribute – de multe ori valorile sale se incrementează automat, la adăugarea de noi elemente în entitate.
Cele trei entități vor avea următoarea structură:
ELEV
# id_elev
* nume
* prenume
* data_nasterii
PROFESOR
# id_profesor
* nume
* prenume
* vechime
∘ adresa
∘ email
CLASA
# id_clasa
* denumire
* nivel_invatamant
∘ specializare
După adăugarea cheii, elementele entităților bazei de date scoala pot fi privite astfel:
ELEV
| id_elev | nume | prenume | data_nasterii |
|---|---|---|---|
| 1 | Marin | Gheorghe | 2007-12-25 |
| 5 | Andreescu | Ionela | 2002-10-06 |
| 2 | Pop | Constantin | 2006-04-12 |
| 3 | Ionescu | Flavia | 2008-07-19 |
PROFESOR
| id_profesor | nume | prenume | vechime | adresa | |
|---|---|---|---|---|---|
| 1 | Rus | Daniel | 25 | București, str. Florilor, 5 | rus.daniel@mail.ro |
| 4 | Georgescu | Clara | 7 | clara@cnrr.ro | |
| 3 | Man | Sebastian | 17 |
CLASA
| id_clasa | denumire | nivel | specializare |
|---|---|---|---|
| 1 | 12 A | 12 | Matematică-informatică |
| 2 | 8 B | 8 | |
| 3 | 10 D | 10 | Științele naturii |
Nu trebuie să considerăm cheile primare ca un sistem de numerotare a elementelor entității. Ordinea elementelor nu este obligatoriu identică cu cea a valorilor cheii, iar anumite valori pot să lipsească!
Relații între entități

După cum spuneam elementele entităților dintr-o bază de date interacționează – între entitățile baze de date există relații.
O relație este o asociere între elementele a două entități. De exemplu, între entitățile elev și clasa există relația de apartenență a elevilor la clasă. Această relație poate fi exprimată prin următoarele două afirmații:
- Fiecare clasă poate conține 0 sau mai mulți elevi.
- Fiecare elev trebuie să aparțină unei singure clase.
O altă relație între elev și clasa este dată de calitatea de șefi ai clasei a unor elevi:
- Fiecare clasă trebuie să aibă un singur șef al clasei.
- Fiecare elev poate să fie șef al unei singure clasei.
Cuvintele evidențiate în propozițiile de mai sus, prin îngroșare și înclinare, reprezintă cele două caracteristici ale relației:
- cardinalitate – arată numărul elementelor din entitatea A îi corespund unui element din entitatea B, și invers;
- opționalitate – arată dacă corespondența dintre elementul (elemenetele) din A și cele din B este obligatorie sau opțională.
Relațiile dintre entități pot fi:
- unu la unu (one-to-one)
- unu la mai mulți (one-to-many)
- mai mulți la unu (many-to-one)
- mai mulți la mai mulți (many-to-many)
Relațiile între entități se realizează prin intermediul cheilor – primare și străine.
Unu la unu
Într-o relație unu la unu, la fiecare element dintr-o entitate A îi corespunde cel mult un element din altă entitate B, dar pot exista elemente în entitatea B care nu au corespondenți în A.
De exemplu, fiecărei clase (A) îi corespund exact un șef al clasei (B), dar există elevi (B) care nu sunt șefi pentru nicio clasă (A). Atributele entității clase devin:
CLASA
# id_clasa
* denumire
* nivel_invatamant
∘ specializare
* id_elev_sef
Atributul id_elev_sef este cheie străină, valorile sale regăsindu-se în cheia primară id_elev al entității elevi.
Similar, fiecărei clase (A) îi corespund exact un profesor diriginte (B), dar există profesori (B) care nu sunt diriginți la nicio clasă (A). La atributele entității clase se adaugă id_profesor_diriginte, care este cheie străină, valorile sale regăsindu-se în cheia primară id_profesor al entității profesori.
Unu la mai mulți, mai mulți la unu
Într-o relație de tip unu la mai mulți, fiecare element din entitatea A îi corespund mai multe (zero sau mai multe) elemente din entitatea B, însă fiecare element din entitatea B are un singur element corespondent în entitatea A.
De exemplu, fiecare clasă (A) conține mai mulți elevi (B), dar fiecare elev face parte din exact o clasă. Entitatea elevi va avea următoarea structură:
ELEV
# id_elev
* nume
* prenume
* data_nasterii
* id_clasa
Atributul id_clasa este cheie străină, valorile sale regăsindu-se în cheia primară id_clasa al entității clase.
Mai mulți la mai mulți
Într-o relație de tip mai mulți la mai mulți, fiecare element din entitatea A poate avea mai multe elemente corespondente în entitatea B și fiecare element din B poate avea mai multe elemente corespondente în A.
De exemplu, un profesor (A) predă la mai multe clase (B) și la o clasă (B) predau mai mulți profesori (A).
Relațiile mai mulți la mai mulți se stabilesc prin intermediul unei entități suplimentare, numită entitate asociativă. În cazul nostru, relațiile dintre profesori și clase se stabilesc prin intermediul entități încadrare, cu atributele:
id_clasa– cheie străină cu valori din atributulid_clasaal entitățiiclaseid_profesor– cheie străină cu valori din atributulid_clasaal entitățiiprofesorinumăr_ore– numărul de ore pe care îl predă un anumit profesor la o anumită clasă.
ÎNCADRARE
# id_clasa
# id_profesor
* număr_ore
Perechea (id_clasa, id_profesor) reprezintă cheia primară pentru entitatea nou creată.
Normalizarea
Poate v-ați întrebat de ce nu se unifică toate informațiile despre elevi (nume, prenume, clasa, diriginte, etc.) într-o singură entitate. Acest lucru ar fi posibil, însă în entitatea obținută am avea numeroase date duplicate: pentru fiecare elev, entitatea ar conține informații redundante despre clase și diriginți. Datele redundante nu sunt dorite: măresc considerabil dimensiunea bazei de date, încetinesc operațiile cu entitățile bazei de date și sunt foarte greu de întreținut. Dacă un profesor își schimbă domiciliul, vrem să modificăm într-un singur loc!
Normalizarea este procesul (alcătuit din etape) prin care se modifică structura entităților în scopul de a reduce redundanța datelor și a mări coerența lor.
- Redundanța se referă dublarea datelor – stocarea acelorași date în mai multe entități simultan, fără ca acest lucru să fie necesar.
- Coerența se referă la caracterul unitar al datelor: conformitatea cu un anumit format, încadrarea între anumite limite, lipsa contradicțiilor, etc.
După fiecare etapă a normalizării, baza de date este adusă într-o anumită formă normală.
Modelul matematic al normalizării definește cinci forme normale. În practică sunt frecvent utilizate primele trei:
- FN1, prima formă normală (1NF, first normal form)
- FN2, a doua formă normală (2NF, second normal form)
- FN3, a treia formă normală (3NF, third normal form)
Fiecare formă normală este mai puternică decât celelalte. O bază de date aflată în forma FN3 este în același timp în formele FN1 și FN2. Un nivel de normalizare mai ridicat va mări probabil numărul de entități ale bazei de date, în comparație cu o formă normală mai scăzută. Descompunerea unei entități în mai multe trebuie să fie:
- fără pierderi – divizarea tabelelor nu provoacă pierderi de informații
- cu păstrarea dependențelor – divizarea tabelelor nu provoacă pierderi între relații
Atributele cheie primară și cheie străină nu se consideră date redundante.
Prima formă normală
Un tabel în prima formă normală:
- atributele conțin doar valori atomice
- nu are grupuri de atribute care se repetă
O valoare atomică nu poate fi împărțită într-un mod care să aibă sens. De exemplu, numele unei persoane va ocupa două atribute, nume și prenume.
Un grup care se repetă este un grup de două sau mai multe atribute de același tip. De exemplu, un profesor poate avea una, două sau trei adrese de email. Nu vom plasa în entitatea profesor atributele email1, email2, email3, ci vom crea o nouă entitate, adrese_email, cu structura:
idid_profesoremail.
În această entitate atributul id_profesor este cheie străină, iar entitățile profesor și adrese_email se află în relația one-to-many.
A doua formă normală
O entitate în prima formă normală a cărei cheie primară este simplă este automat în a doua formă normală. În caz contrar, pentru a fi în a doua formă normală este necesar ca entitatea să nu aibă dependențe funcționale parțiale.
O entitate are o dependență funcțională parțială dacă există atribute non cheie care depind doar de o parte a atributelor care formează cheia primară. Acestea ar trebui actualizate la orice modificare a valorilor din cheia primară.
De exemplu, considerăm entitatea incadrare cu structura:
(id_clasa, id_profesor)– cheie primară compusădisciplina– disciplina predată la clasătelefon_profesor– numărul de telefon al profesorului
Atributul telefon_profesor este dependent numai de atributul id_profesor, ceea ce nu este corect. Entitatea nu respectă a doua formă normală. Pentru a corecta, numărul de telefon al profesorului trebuie precizat ca atribut în entitatea profesor.
A treia formă normală
O entitate este în a treia formă normală dacă este în a doua formă și nu are dependențe tranzitive. Dependența tranzitivă apare când dacă valoarea unui atribut non cheie determină valoarea altui atribut non-cheie.
Considerăm tabelul elev cu structura:
id– cheie primarănume,prenumeid_clasadenumire_clasa
Valorile atributului denumire_clasa depind de valorile atributului id_clasa, care nu este cheie primară. Acest atribut trebuie să apară numai în entitatea clase, pentru a evita această dependență.