Articolele lui
 Candale Silviu (silviu)
Candale Silviu (silviu)
Limbajul HTML - lucrul cu text
Paginile web conțin text. Limbajul HTML oferă o serie de elemente ce permit lucrul cu acesta:
- împărțirea textului în secțiuni
- formatarea textului
Limbajul HTML a evoluat în timp. La început, elementele erau gândite să precizeze direct modul de afișare în pagină a conținutului. De exemplu, elementul <b> precizează că textul este îngroșat, folosit pentru a întări textul. În timp, limbajul HTML a devenit semantic, elementele precizând rolul lor în pagină, nu modul de afișare. Astfel, pentru a întări o porțiune de text se folosește elementul <strong>. Efectul vizual implicit este același cu cel al marcajului <b>.
Elementele care descriu modul de afișare a conținutului, precum și atributele care descriu aspectul conținutului au devenit în prezent învechite (deprecated, obsolete) și se recomandă evitarea lor. Pentru a descrie aspectul elementelor din pagină se folosesc foile de stil în cascadă (CSS).
Elemente block și elemente inline
Elementele cu efect vizual în pagina web pot fi clasificate după modul în care se afișează în pagină:
- elementele block se afișează în pagină unele sub altele, pe verticală;
- elementele inline se afișează în pagină pe orizontală, unele după altele și de regulă fac parte din elemente block.
Elementul p
Când avem un text mai lung, îl împărțim în paragrafe, pentru a ușura citirea lui. Paragrafele se definesc în HTML prin intermediul elementului <p>, un element de tip bloc.
<p> Un paragraf oarecare. </p>
Elementul <p> poate avea atributul align, cu valorile posibile left, center, right sau justify, care stabilește modul în care este aliniat pe orizontală conținutul paragrafului, dar este un atribut învechit. Valoarea sa implicită este left, adică paragraful va avea conținutul aliniat la stânga.
<p align="left"> Un paragraf aliniat la stânga. </p> <p align="right"> Un paragraf aliniat la dreapta. </p> <p align="center"> Un paragraf aliniat la centru. </p>
Între blocul definit de elementul <p> și blocul de text anterior se lasă un spațiu.
Titluri
În pagina web se pot introduce titluri. Afișarea lor diferă între ele și diferă de restul paginii.
Sunt șase categorii de titluri, definite prin intermediul elementelor <h1>, <h2>, <h3>, <h4>, <h5>, <h6>. Elementul <h1> definește titlul de importanță maximă, iar <h6> pe cel de importanță minimă.
Conținutul titlurilor poate fi aliniat cu atributul align, care este însă învechit.
<h1>Titlu 1</h1> <h2>Titlu 2</h2> <h3>Titlu 3</h3> <h4>Titlu 4</h4> <h5>Titlu 5</h5> <h6>Titlu 6</h6> <p>Un paragraf oarecare</p>
Citate
În pagina web se pot introduce citate, prin intermediul elementelor <blockquote> și <q>.
<blockquote> este un element block. De regulă se afișează cu o margine vizibilă în partea stângă. Poate avea atributul cite, a cărui valoare este adresa URL a documentului citat. Dacă se dorește afișare în text a documentului citat se poate folosi elementul <cite>.
Elementul <q> este un element inline – se folosește pentru a introduce un citat în interiorul unui block de text – de exemplu în interiorul unui paragraf. Și el are atributul cite, cu același înțeles.
<blockquote cite="https://www.huxley.net/bnw/four.html">
<p>Words can be like X-rays, if you use them properly—they’ll go through anything. You read and you’re pierced.</p>
<footer>—Aldous Huxley, <cite>Brave New World</cite></footer>
</blockquote>
<p>Aldous Huxley sayd: <q cite="Brave New World">Words can be like X-rays</q>!</p>
Linii orizontale
Pentru a separa secțiunile unei pagini se pot folosi linii orizontale, prin intermediul elementului <hr>. Acesta are următoarele atribute, toate învechite:
align, cu valorile posibileleft,centerșiright– precizează alinierea liniei în blocul din care face parte;color– stabilește culoarea liniei;size– stabilește înălțimea (grosimea) liniei, în pixeliwidth– stabilește lungimea liniei, în pixeli sau procente
<hr> <hr align="right" width="150" color="red" size="10"> <hr width="150" color="green" size="5">
Blocuri de text preformatat
În pagina web caracterele albe consecutive sunt implicit ignorate. Dacă totuși dorim să afișam un text exact așa cum este scris, putem folosi marcajul <pre>, care definește un bloc de text preformatat. Conținutul său va fi afișat în pagină exact așa cum este scris în documentul HTML, folosind un corp de literă monospațiat.
<pre>Un text preformatat, în care sunt vizibile spatiile albe! </pre>
Elementele div și span
Elementul <div> este un element de tip block generic, care poate fi utilizat în foarte multe moduri. Nu are niciun efect asupra conținutului sau aranjării în pagină dacă nu are atașat CSS.
Elementul <span> este un element inline generic, utilizabil în foarte multe moduri. La fel ca <div>, un are efect asupra conținutului sau aranjării în pagină dacă nu are atașat CSS.
<div style="border: solid 1px red; padding:5px; margin:5px;"> Un bloc DIV. <div style="border: solid 1px red; padding:5px; margin:5px;">Alt DIV.</div> <div style="border: solid 1px green; padding:5px; margin:5px;">Acest DIV contine un <span style="border: dotted 1px red">SPAN</span>.</div> </div>
Atributul style este folosit pentru formatarea elementelor prin intermediul CSS.
Elemente de frază
Elementele de frază ne permit să dăm un înțeles specific unei secțiuni din document:
<em>...</em>– pentru evidențiere; textul conținut se afișează înclinat (cursiv);<strong>...</strong>– pentru evidențiere; textul conținut se afișează îngroșat (aldin);<code>...</code>– pentru inserarea unui fragment de cod de calculator; este afișat cu un font monospațiat;<kbd>...</kbd>– pentru inserarea unui caracter sau secvențe de caractere introduse de la tastatură; este afișat de regulă cu un font monospațiat;<samp>...</samp>– pentru inserarea text care reprezintă date de ieșire pentru un program de calculator; este afișat de regulă cu un font monospațiat;<var>...</var>– pentru a insera nume de variabile dintr-un text matematic sau dintr-un program de calculator; textul conținut se afișează înclinat (cursiv);<abbr>...</abbr>– pentru a insera o abrevier sau un acronim; textul conținut se afișează de regulă evidențiat într-un anume fel (de exemplu prin subliniere cu o linie); atributultitleare un înțeles semantic – trebuie să conțină doar textul care este abreviat;
<p>
<em>Text evidentiat</em> cu font inclinat.
</p>
<p>
<strong>Text evidentiat</strong> cu font ingrosat.
</p>
<p>
<code>Cod de calculator</code>.
</p>
<p>
<kbd>CTRL</kbd> + <kbd>S</kbd> realizeaza salvarea documentelor.
</p>
<p>
<samp>Date de iesire</samp> - font monospatiat.
</p>
<p>
<var>x + y + z</var> - o expresie matematica.
</p>
<p>
Invatam <abbr title="HyperText Markup Language">HTML</samp>!
</p>  Candale Silviu (silviu)
Candale Silviu (silviu) Limbajul HTML - introducere
Introducere
Limbajul HTML este folosit pentru a descrie conținutul paginilor web și este folosit împreună cu alte tehnologii, precum CSS și Javascript.
HTML înseamnă HyperText Markup Language.
Documentele html conțin cod HTML. Ele sunt încărcate în browser, de pe calculatorul local sau de pe Internet. Conținutul său este interpretat de browser; acesta mai încarcă și alte fișiere, de exemplu imagini, precizate în document, și afișează pagina web.
Documentele HTML conțin doar text. Acesta poate fi creat cu orice editor de texte, de exemplu Notepad, dar un editor specializat poate ajuta în realizarea mai rapidă a documentului. Exemple de editoare de text utile în realizarea documentelor HTML: Notepad++, Komodo Edit, Sublime Text Editor, etc.
Pe internet există numeroase locuri unde putem învăța limbajul HTML, și nu numai. Dintre acestea, amintim:
- W3Schools – o platformă de învățare cu tutoriale de mici dimensini, simple și clare, foarte potrivite pentru începători;
- Khan Academy – o suită de lecții interactive, gândite să fie parcurse pas cu pas;
- MDN Web Docs – o platformă a fundației Mozilla – care conține atât tutoriale, cât și referințe complete pentru tehnologiile folosite în crearea unei pagini web.
Ciclul de proiectare a unei pagini web
- editarea documentul html folosind un editor de text;
- salvarea cu extensia
.html; - afișarea paginii web folosind un browser – de exemplu Mozilla Firefox sau Google Chrome.
Primul document HTML
Scrieți codul de mai jos într-un editor de text.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Prima pagină</title>
</head>
<body>
<!-- acest text este un comentariu -->
<h1>Salut</h1>
<hr>
<p> Aceasta este prima pagină web.</p>
<p> <a href="https://www.pbinfo.ro">Link spre pbinfo.</a> </p>
</body>
</html>
Mai departe:
- salvați fișierul cu numele
salut.html, într-un folder pe disc. Extensiahtmleste importantă! - deschideți folderul unde l-ați salvat și deschideți fișierul cu un browser!
Explicația exemplului
- declarația
<!DOCTYPE html>precizează că documentul respectă standardul HTML5. - elementul
<html>este elementul râdăcină al oricărui document html. - elementul
<head>conține informații despre document care nu se vor afișa în pagina web. - elementul
<title>precizează titlul document, așa cum va fi afișat în bara de titlu a browser-ului. - elementul
<meta charset="utf-8">precizează că documentul este scris folosind codificareUTF-8pentru caractere. Aceasta permite utilizarea caracterelor cu diacritice, specifice limbii române:ă,â,î,ș,ț. - elementul
<body>conține ceea ce se afișează în fereastra browser-ului. - elementul
<h1>definește un titlu de cel mai important nivel. - elementul
<hr>definește o linie orizontală (horizontal rule) - elementul
<p>definește un paragraf (aliniat) oarecare. - elementul
<a>definește o ancoră; prin intermediul lui se introduc în pagina web link-uri. - secvența
<!-- ... -->este un comentariu. Browserul îl ignoră și nu îl afișează în pagina web; el are importanță numai pentru cei care editează documentul html.
Structura unui document html
Un document html este alcătuit din elemente, sau marcaje (engl. elements): html, head, body, title, h1, p, a , meta, hr.
Elementele sunt inserate în document prin intermediul etichetelor (engl. tags). Acestea conțin elementul între simbolurile <>.
- Majoritatea elementelor sunt definite prin intermediul a două etichete: eticheta de deschidere (ex.
<h1>) și eticheta de închidere (ex.</h1>), iar între cele două etichete se află conținutul elementului:<h1>Salut</h1>. - Există și elemente cu o singură etichetă, de exemplu
hr. Eticheta de închidere nu este necesară, deoarece aceste elemente nu au conținut.
Unele elemente pot avea atribute (engl. attributes). Ele furnizează informații suplimentare despre element și se scriu în eticheta de deschidere. Un atribut are de regulă o valoare (engl value), dar există și atribute care nu au valori – simpla prezență a atributului în element este suficientă. Pentru atributele care au valori, ele se dau în forma atribut="valoare"!
De exemplu, în elementul <a href="https://www.pbinfo.ro">Link spre pbinfo.</a>, href este un atribut, iar https://www.pbinfo.ro; valoarea sa stabilește destinația link-ului.
- elementele și atributele lor se scriu cu litere mici
- valorile se scriu între ghilimele duble:
"
Spații albe
Browser-ele ignoră spațiile albe (caracterele spațiu, tab, sfârșit de rând). Următoarele secvențe au același efect.
<p> Aceasta este prima pagină web.</p>
<p>
Aceasta este prima pagină web.
</p>
<p>
Aceasta este
prima
pagină web.
</p>
Pentru a insera un spațiu de dimensiuni mai mari, putem folosi o construcție specială a limbajului HTML: . Ea se numește entitate HTML (engl. HTML entity).
Pentru trece la rând nou în interiorul unui paragraf, putem folosi elementul <br> (break).
Operații logice
Operațiile logice lucrează cu valori de adevăr. Le folosim instinctiv în viața de zi cu zi, dar uneori ne pun în dificultate atunci când trebuie să le aplicăm într-un algoritm.
Valori de adevăr. Propoziții adevărate și false
Operațiile logice se fac cu valori de adevăr (notate TRUE / FALSE, sau ADEVĂRAT / FALS) sau propoziții care au ca rezultat valori de adevăr. De exemplu:
- “Orașul Sibiu este în România.” – este o propoziție adevărată, are valoarea
ADEVĂRAT; - “Orașul Sibiu este în Bulgaria.” – este o propoziție falsă, are valoare
FALS.
Exemple din matematică:
- numărul
19este impar –ADEVĂRAT 10se divide cu3–FALS- comparații:
3 ≠ 4–ADEVĂRAT10 < 5–FALSx > 3– nu știm rezultatul; depinde de valoarea luix!!
Exemple din algoritmică (C/C++):
19%2==1–ADEVĂRAT, în C/C++ rezultatul este110%3==0–FALS, în C/C++ rezultatul este03 != 4–ADEVĂRAT, în C/C++ rezultatul este110 < 5–FALS, în C/C++ rezultatul este0x > 3– nu știm rezultatul; depinde de valoarea luixdin momentul in care se face comparația!!
De multe ori o propoziție logică conține variabile, iar valoarea de adevăr a ei depinde de valorile variabilelor.
Două propoziții logice, care depind de anumite variabile, sunt echivalente dacă, pentru orice valori ale variabilelor, sunt fie amândouă adevărate, fie amândouă false. De exemplu, propoziția “numărul natural n este par” este echivalentă cu propoziția “restul împărțirii numărului natural n la 2 este 0”.
Operațiile logice
Negarea
Negarea este o operație foarte folosită în viața de zi cu zi. Prin negare, propoziția “Orașul Sibiu este în România.” devine “Orașul Sibiu nu este în România.”, care este FALSĂ. Prin negarea unei propoziții adevărate se obține o propoziție falsă, iar prin negarea unei propoziții false se obține o propoziție adevărată.
În C/C++, negarea este o operație unară, cu prioritate mare, iar operatorul său este !. Ea poate fi aplicată pentru orice valori numerice (și nu numai), dar de regulă se aplică asupra altor valori logice.
- dacă
peste o expresie cu valoarea0(FALS), atunci!pare valoarea1(ADEVĂRAT). - dacă
peste o expresie cu valoarea diferită de0(ADEVĂRAT), atunci!pare valoarea0(FALS).
Exemple:
int x = 10; cout << !(x == 10); // 0: x == 10 este adevărat și are rezultat 1, 1 negat este 0 cout << !x == 10; // tot 0, dar se efectuează mai întâi !x, adică !10, cu rezultat 0, apoi 0 == 10, cu rezultat fals, adică 0 cout << !(x < 5); // 1: x < 5 este fals, adică 0, 0 negat este 1
Conjuncția
Conjuncția realizează “compunerea” a două propoziții prin intermediul cuvântului ȘI. Exemple:
- Propoziția “Orașul Sibiu este în România.” ȘI “Orașul Craiova este în România.” este obținută prin compunerea a două propoziții adevărate și este la rândul său adevărată;
- Propoziția “Orașul Sibiu este în România.” ȘI “Orașul Craiova este în Bulgaria.” este obținută prin compunerea unei propoziții adevărate cu una falsă și este la rândul său falsă;
- Propoziția “Orașul Sibiu este în Bulgaria.” ȘI “Orașul Craiova este în România.” este obținută prin compunerea unei propoziții false cu una adevărate și este la rândul său falsă;
- Propoziția “Orașul Sibiu este în Bulgaria.” ȘI “Orașul Craiova este în Bulgaria.” este obținută prin compunerea a două propoziții false și este la rândul său falsă.
Astfel, conjuncția a două propoziții este ADEVĂRAT dacă ambele propoziții sunt adevărate, în toate celelalte cazuri este FALSĂ.
În C/C++ simbolul conjuncției este &&. La fel ca negarea, și conjuncția poate fi aplicată pentru orice valori numerice (și nu numai), dar de regulă se aplică asupra altor valori logice.
Fie p și q două valori numerice:
- dacă
peste nenul șiqeste nenul, atunci(p&&q)==1; - dacă
peste nenul șiqeste nul, atunci(p&&q)==0; - dacă
peste nul șiqeste nenul, atunci(p&&q)==0; - dacă
peste nul șiqeste nul, atunci(p&&q)==0;
Exemple:
cout << (1 < 2 && 2 == 1 + 1); // 1; ADEVĂRAT ȘI ADEVĂRAT este ADEVĂRAT cout << (1 < 2 && 2 != 1 + 1); // 0; ADEVĂRAT ȘI FALS este FALS cout << (1 == 2 && 2 == 1 + 1); // 0; FALS ȘI ADEVĂRAT este FALS cout << (1 == 2 && 2 != 1 + 1); // 0; FALS ȘI FALS este FALS
Disjuncția
Disjuncția realizează “compunerea” a două propoziții prin intermediul cuvântului SAU. Exemple:
- Propoziția “Orașul Sibiu este în România.” SAU “Orașul Craiova este în România.” este obținută prin compunerea a două propoziții adevărate și este la rândul său adevărată;
- Propoziția “Orașul Sibiu este în România.” SAU “Orașul Craiova este în Bulgaria.” este obținută prin compunerea unei propoziții adevărate cu una falsă și este la rândul său adevărată;
- Propoziția “Orașul Sibiu este în Bulgaria.” SAU “Orașul Craiova este în România.” este obținută prin compunerea unei propoziții false cu una adevărate și este la rândul său adevărată;
- Propoziția “Orașul Sibiu este în Bulgaria.” SAU “Orașul Craiova este în Bulgaria.” este obținută prin compunerea a două propoziții false și este la rândul său falsă.
Astfel, disjuncția a două propoziții este ADEVĂRATĂ dacă cel puțin una dintre ele este adevărată; dacă ambele propoziții sunt false, disjucția lor este FALSĂ.
În C/C++ simbolul disjuncției este ||. La fel ca negarea și conjuncția, și disjuncția poate fi aplicată pentru orice valori numerice (și nu numai), dar de regulă se aplică asupra altor valori logice.
Fie p și q două valori numerice:
- dacă
peste nenul șiqeste nenul, atunci(p || q)==1; - dacă
peste nenul șiqeste nul, atunci(p || q)==1; - dacă
peste nul șiqeste nenul, atunci(p || q)==1; - dacă
peste nul șiqeste nul, atunci(p || q)==0;
Exemple:
cout << (1 < 2 || 2 == 1 + 1); // 1; ADEVĂRAT SAU ADEVĂRAT este ADEVĂRAT cout << (1 < 2 || 2 != 1 + 1); // 1; ADEVĂRAT SAU FALS este ADEVĂRAT cout << (1 == 2 || 2 == 1 + 1); // 1; FALS SAU ADEVĂRAT este ADEVĂRAT cout << (1 == 2 || 2 != 1 + 1); // 0; FALS SAU FALS este FALS
Exerciții
7 11 17 19 28 509
Legile lui De Morgan
Acestea stabilesc niște reguli legate de situația în care aplicăm operația de negare asupra unor conjuncții și disjuncții. Formal, ele se exprimă astfel:
Fie p și q două expresii logice. Atunci:
!(p && q) ↔ !p || !q!(p || q) ↔ !p && !q
Prin ↔ se înțelege echivalența a două propoziții.
Exemplu
Fie n un număr natural. Dorim o condiție care să fie adevărată dacă și numai dacă n are exact două cifre. Această condiție este: “mai mare sau egal cu 10 și mai mic decât 100”. Expresia C/C++ este: n >= 10 && n < 100.
Care este condița inversă? Adică, cum exprimăm faptul că n nu are exact două cifre? Dacă n nu are exact două cifre înseamnă că n are o cifră sau n are cel puțin trei cifre. Adică “este mai mic decât 10 sau mai mare sau egal cu 100”. În C/C++: n < 10 || n >= 100.
Adică !(n >= 10 && n < 100) este echivalent cu n < 10 || n >= 100.
Atenție: nu există nicio valoare pentru care n < 10 && n >= 100.
Exerciții
15 18 61 476 529
Subșir crescător de lungime maximă
n elemente, numere naturale. Determinați un cel mai lung subșir crescător al șirului.
De exemplu, pentru n=10 și șirul A=(5, 10, 7, 4, 5, 8, 9, 8, 10, 2), cel mai lung subșir crescător va conține 5 elemente (5, 7, 8, 9, 10) sau (4, 5, 8, 9, 10).
Problema este una clasică și se rezolvă prin programare dinamică. Subșirul cerut se mai numește și subșir crescător maximal.
O soluție \(O(n^2)\)
Determinarea lungimii maxime
Pentru a determina lungimea maximă a unui subșir crescător al lui A, vom construi un șir suplimentar LG[], cu proprietatea că LG[i] este lungimea maximă a unui subșir care se începe în A[i]. Atunci lungimea maximă a unui subșir crescător va fi cel mai mare element din tabloul LG.
Vom construi șirul LG progresiv, începând de la ultimul element din A, bazându-ne pe următoarele observații:
LG[i] ≥ 1,∀iLG[n] = 1- vom determina
LG[i]astfel: analizăm toate elementeleA[j], cuj>iși îl alegem pe acela pentru careLG[j]este maxim șiA[i]≤A[j]. Fiejmaxindicele acestui element. AtunciLG[i]devineLG[i] = LG[jmax] + 1– elementulA[i]se lipește de subșirul care începe înA[jmax].
Secvență C++:
LG[n] = 1;
for(int i = n - 1 ; i > 0 ; i --)
{
LG[i] = 1;
for(int j = i + 1 ; j <= n; ++ j)
if(A[i] <= A[j] && LG[i] < LG[j] + 1)
LG[i] = LG[j] + 1;
}
După construirea șirului LG, lungimea subșirului maximal se determină ca fiind cea mai mare valoare din tabloul LG.
int pmax = 1;
for(int i = 2 ; i <= n ; i ++)
if(LG[i] > LG[pmax])
pmax = p;
cout << LG[pmax];
Reconstituirea subșirului
Există mai multe modalități de reconstituire a subșirului maximal. De asemenea, trebuie spus că pot exista mai multe șiruri maximale; în unele probleme poate fi determinat oricare, în altele trebuie determinat un subșir cu proprietăți suplimentare.
O soluție constă în construirea unui șir suplimentar, Next cu următoarea semnificație: Next[i] este următorul element în subșirul crescător maximal care începe cu A[i]. Dacă nu există un element următor, atunci LG[i] = -1. Acest tabloul se construiește în același timp cu LG, astfel:
LG[n] = 1, Next[n] = -1;
for(int i = n - 1 ; i > 0 ; i --)
{
LG[i] = 1 , Next[n] = -1;
for(int j = i + 1 ; j <= n; ++ j)
if(A[i] <= A[j] && LG[i] < LG[j] + 1)
LG[i] = LG[j] + 1, Next[i] = j;
}
Pentru a afișa subșirul, vom extrage informațiile necesare din șirul Next, pornind de la indicele pmax determinat mai sus:
int p = pmax;
do
{
cout << p << " ";
p = Next[p];
}
while(p != -1);
Putem reconstitui subșirul fără a construi șirul Next. La fiecare pas al structurii repetitive de mai sus vom determina un indice pUrm cu proprietatea că LG[pUrm]==LG[p]-1 și A[p] ≤ A[pUrm]:
int p = pmax;
do
{
cout << p << " ";
int pUrm = p + 1;
while(pUrm <= n && ! (A[pUrm] >= A[p] && LG[pUrm] == LG[p] - 1))
pUrm ++;
if(pUrm <= n)
p = pUrm;
else
p = -1;
}
while(p != -1);
Altă soluție \(O(n^2)\)
Putem regândi algoritmul de mai sus, astfel încât LG[i] să reprezinte lungime a maximă a unui subșir maximal care se termină în A[i].
- evident,
LG[1]=1; - pentru fiecare element
A[i]din șirul dat, vom parcurge elementele din fața sa și îl vom alege peA[p]atfel încâtA[p]≤A[i]șiLG[p]este maxim. În acest caz,A[i]se adaugă la subșirul care se încheie înA[p], adicăLG[i]devineLG[p]+1.
Lungimea subșriului maximal este cea mai mare valoare din LG, iar recosntituirea lui se face asemănător cu metoda de mai sus, folosind un șir de predecesori Prev[], unde Prev[i] este elementul din fața lui A[i] în subșirul crescător maximal care se încheie în A[i].
O soluție \(O(n \cdot \log n)\)
Algoritmul de mai sus are complexitate pătratică. Următoarea idee permite obținerea unui algoritm \(O(n \cdot \log{n})\).
Vom construi șirul D[], unde D[j] reprezintă un element al șirului A în care se termină un subșir crescător maximal de lungime j. Numărul de elemente pe care le va avea la final tabloul D va reprezenta lungimea subșirului crescător maximal al întregului șir A.
Vom construi șirul D în felul următor:
- fie
klungimea șiruluiD. Inițializămk=1șiD[k]=A[1]; - parcurgem șirul
A, începând de la al doilea element:- dacă
A[i]≥D[k], îl adăugăm peA[i]în șirulD– subșirul crescător maximal al luiAcrește cu încă un element - dacă
A[i]<D[k], vom înlocui cuA[i]pe cel mai mai mic element dinDcare este mai mare decât acesta
- dacă
ATENȚIE: Șirul D[] nu conține un subșir crescător al șirului A[]!
Exemplu
Pentru A=(5, 10, 7, 4, 5, 8, 9, 8, 10, 2).
Inițial k=1; D[k]=5; parcurgem șirul A, începând de la al doilea element:
i |
A[i] |
Condiție | Acțiune | D[] |
| 1 | 5 | - | - | (5) |
| 2 | 10 | A[i]>=D[k] |
adăugare | (5, 10) |
| 3 | 7 | A[i]<D[k] |
înlocuire | (5, 7) |
| 4 | 4 | A[i]<D[k] |
înlocuire | (4, 7) |
| 5 | 5 | A[i]<D[k] |
înlocuire | (4, 5) |
| 6 | 8 | A[i]>=D[k] |
adăugare | (4, 5, 8) |
| 7 | 9 | A[i]>=D[k] |
adăugare | (4, 5, 8, 9) |
| 8 | 8 | A[i]<D[k] |
înlocuire | (4, 5, 8, 8) |
| 9 | 10 | A[i]>=D[k] |
adăugare | (4, 5, 8, 8, 10) |
| 10 | 2 | A[i]<D[k] |
înlocuire | (2, 5, 8, 8, 10) |
Observații
- valorile din șirul
Dsunt în ordine crescătoare - fiecare element din șirul
Amodifică exact un element din șirulD(prin adăugare sau înlocuire).
Aceste observații ne permit să folosim căutarea binară pentru a stabili elementul din D care va fi înlocuit la fiecare pas: vom căuta primul element din D care este mai mare decât A[i]. Acest lucru poate fi realizat manual sau folosind funcția STL upper_bound. Complexitatea va fi \(O(n \cdot \log k)\).
Secvență C++
k = 1, D[k] = A[1];
for(int i = 2 ; i <= n ; i ++)
{
if(A[i] >= D[k])
P[++k] = A[i];
else
{
int st = 1 , dr = k , poz = k + 1;
while(st <= dr)
{
int m = (st + dr) / 2;
if(D[m] > A[i])
poz = m , dr = m - 1;
else
st = m + 1;
}
D[poz] = A[i];
}
}
cout << k << endl;
Reconstituirea subșirului
Pentru a reconstitui sub șirul crescător maximal vom folosi încă un șir P[], unde P[i] reprezintă poziția în șirul D unde a fost plasat (prin adăugare sau prin înlocuire) A[i]. Acesta este construit, pas cu pas, odată cu șirul D[]. Dacă un element A[i] face parte din subșirul crescător maximal, atunci P[i] reprezintă poziția sa în subșir.
Pentru exemplul de mai sus, șirul P[] va fi la final (1,2,2,1,2,3,4,4,5,1).
Reconstituirea propriu-zisă a subșirului se face în felul următor:
- fie
k– lungimea subșirului crescător maximal; - căutăm în șirul
P[]un element egal cuk. FieIkpoziția sa. AtunciA[Ik]reprezintă ultimul element al subșirului crescător maximal – cel de pe pozițiak; - căutăm în șirul
P[]un element egal cuk-1, anterior elementului de indiceIk. FieIk-1poziția sa. - analog se caută în
P[]valorilek-2, k-3, ..., 2, 1. - subșirul crescător maximal va fi
(A[I1], A[I2], ..., A[Ik]).
Secvența C++
În secvența de mai jos șirul I[] construit va conține indicii elementelor din A[] care fac parte din subșirul comun maximal.
k = 1;
D[k] = A[1];
P[1] = 1;
for(int i = 2 ; i <= n ; i ++)
if(A[i] >= D[k])
D[++k] = A[i], P[i] = k;
else
{
int st = 1 , dr = k , p = k + 1;
while(st <= dr)
{
int m = (st + dr) / 2;
if(D[m] > A[i])
p = m, dr = m - 1;
else
st = m + 1;
}
D[p] = A[i];
P[i] = p;
}
int j = n;
for(int i = k ; i >= 1 ; i --)
{
while(P[j] != i)
j --;
I[i] = j;
}
Probleme propuse
Numărul de drumuri în matrice
Introducere
Considerăm o matrice (labirint, teren, etc.) cu n linii și m coloane și un mobil aflat inițial în elementul de coordonate (1,1) – colțul stânga-sus, care se poate deplasa din elementul curent, de coordonate (i,j) în unul dintre elementele de coordonate (i+1,j) – aflat pe linia următoare, și (i,j+1) – aflat pe următoarea coloană. Să se determine în câte moduri poate ajunge mobilul în elementul de coordonate (n,m) – colțul dreapta-jos.
Problema are cel puțin două soluții, una care folosește metoda programării dinamice și una care se bazează pe combinatorică.
Rezolvare cu programare dinamică
Să constatăm mai întâi că numărul de drumuri căutat depinde de n și m – la mintea cocoșului, am putea spune. În general, numărul de drumuri de la poziția (1,1) la poziția (i,j) depinde de i și j, și numai de acestea. Atunci, formula recursivă care calculează rezultatul pentru (i,j) va depinde numai de i și de j!
Ne propunem să determinăm numărul de modalități în care mobilul ajunge de la poziția (1,1) în poziția (i,j). Fie acest număr \(F_{i,j}\). Constăm următoarele:
- în orice element de pe linia
1se poate ajunge într-un singur mod, dinspre stânga, deoarece în poziția(1,j)se poate ajunge numai din poziția(1,j-1). Astfel, \(F_{1,j} = 1\). - în orice element de pe coloana
1se poate ajunge într-un singur mod, dinspre linia anterioară, deoarece în poziția(i,1)se poate ajunge numai din poziția(i-1,1). Astfel, \(F_{i,1} = 1\). - în poziția
(i,j)(cui>1șij>1) se poate ajunge în două moduri:- de sus, din poziția
(i-1,j); - din stânga, din poziția
(i,j-1);
- de sus, din poziția
- atunci numărul de posibilități de a ajunge în poziția
(i,j)este numărul de posibilități de a ajunge în poziția(i-1,j)adunat cu numărul de posibilități de a ajunge în poziția(i,j-1). Astfel, \(F_{i,j} = F_{i-1,j} + F_{i,j-1}\). - rezultatul este \(F_{n,m}\).
În concluzie:
\( F_{i,j} = \begin{cases}
1& \text{dacă } i = 1 \text{ sau } j = 1, \\
F_{i-1,j} + F_{i,j-1}& \text{ dacă } i > 1 \text{ și } j > 1
\end{cases} \)
Deoarece formulele se suprapun, implementarea recursivă este foarte lentă. În consecință vom folosi o structură de date suplimentară, mai precis un tablou bidimensional în care A[i][j] reprezintă numărul de modalități de a ajunge din poziția (1,1) în poziția (i,j).
Acest tablou poate fi construit în maniera bottom-up:
int n, m, A[NN][NN]; ... for(int i = 1 ; i <= n ; ++ i) A[i][1] = 1; for(int j = 1 ; j <= m ; ++ j) A[1][j] = 1; for(int i = 2 ; i <= n ; ++ i) for(int j = 2 ; j <= m ; ++ j) A[i][j] = (A[i-1][j] + A[i][j-1]) % 9901; cout << A[n][m];
De asemenea, recurența poate fi rezolvată în maniera top-down, cu memoizare:
int n, m, A[NN][NN];
int F(int i , int j)
{
if(A[i][j] != 0)
return A[i][j];
if(i == 1 || j == 1)
A[i][j] = 1;
else
A[i][j] = (F(i-1,j) + F(i,j-1)) % 9901;
return A[i][j];
}
...
cout << F(n,m);
Rezolvare folosind calcul combinatorial
Pentru această soluție, să observăm că oricare traseu din poziția (1,1) în poziția (n,m), are respectă regulile de deplasare, va face exact n-1 pași spre dreapta și exact m-1 pași în jos. Traseele diferă numai prin ordinea acestor pași, nu prin numărul lor!
Atunci numărul de trasee este egal cu numărul de combinații de n-1 pași spre stânga și m-1 pași spre în jos; altfel spus n+m-2 pași, dintre care n-1 sunt în jos, adică: \(C_{n+m-2}^{n-1}\).
Observații
- numărul de trasee crește foarte repede. Pentru valori relativ mici ale lui
nșimse produce overflow. Pentru valori mai mari ale acestora este necesară implementarea operațiilor cu numere mari! - de multe ori, pentru a rezolva problema cu valori mai mari ale lui
nșim, fără însă a implementa operații cu numere mari, se cere determinarea restului împărțirii rezultatului la o valoare datăMOD, adică realizarea operațiilor moduloMOD! - rezolvarea cu programare dinamică are complexitatea timp \(O(n \cdot m)\). Spațiul de memorie poate fi optimizat, folosind doar două tablouri unidimensionale, unul pentru linia curentă și celălalt pentru linia precedentă. Asta deoarece în calculul valorilor de pe linia curentă
ise folosesc doar elemente de pe aceasta și de pe linia precedentă,i-1. - complexitatea rezolvării cu combinări este cea a algoritmului de determinare a combinărilor. Acestea pot fi determinate fie folosind formula uzuală, fie folosind triunghiul lui Pascal.
Probleme propuse
Secvența de sumă maximă
Introducere
Se dă un tablou A cu n elemente întregi. Să se determine o secvență pentru care suma elementelor este maximă.
Problema este una clasică și admite diverse soluții. Vom vedea în continuare trei soluții, de complexități diferite! Să observăm însă că, dacă elementele ar fi pozitive, atunci secvența cerută ar fi întreg tabloul.
În continuare vom numi secvență candidat o secvență care ar putea fi secvența cerută.
Soluția 1
Prima soluție are complexitatea \(O(n^3)\) și poate fi folosită când valoarea lui n este în jur de 100.
Fiecare secvență a vectorului poate fi secvență candidat. Vom identifica toate secvențele delimitate de indicii i j, cu 1 ≤ i ≤ j ≤ n. Pentru fiecare secvență, vom determina suma elementelor care o compun și vom reține secvența de sumă maximă:
int st = 0 , dr = 1 , Smax = -2000000000 , S;
for(int i = 1 ; i <= n ; ++ i)
for(int j=i;j<=n;++j)
{
S = 0;
for(int k = i ; k <= j ; ++ k)
S += A[k];
if(S > Smax)
Smax = S, st = i, dr = j;
}
cout << Smax << endl;
cout << st << " " << dr;
Soluția 2
Soluția anterioară poate fi îmbunătățită folosind sume partiale pentru a determina suma elementelor din secvența i j. În acest mod complexitatea scade la \(O(n^2)\) și poate fi folosită când valoarea lui n este în jur de 1000.
SP[0] = 0;
for(int i =1 ; i <= n ; i ++)
SP[i] = SP[i-1] + A[i];
int st = 0 , dr = 1 , Smax = -2000000000 , S;
for(int i = 1 ; i <= n ; ++ i)
for(int j=i;j<=n;++j)
{
S = SP[j] - SP[i-1];
if(S > Smax)
Smax = S, st = i, dr = j;
}
cout << Smax << endl;
cout << st << " " << dr;
Soluția 3
Ultima soluție, de complexitate liniară – \(O(n)\) pleacă de la ideea că dacă într-o secvență (PQ), formată prin reuniunea (lipirea) secvențelor (P) și (Q), suma elementelor din secvența (P) este negativă, atunci suma elementelor din sevența (Q) este mai mare decât suma elementelor din secvența (PQ). În cest caz secvența (PQ) nu mai este secvență candidat, dar (Q) este (probabil) secvență candidat.
Procedăm astfel:
- parcurgem tabloul și adunăm elementul curent
A[i]laS– acesta reprezentând suma elementelor dintr-o secvență candidat; - dacă
Seste mai mare decât suma maximă, actualizăm rezultatele; - dacă
Sdevine negativ, îl reinițializăm la0; tot acum reinițializăm și poziția de început a secvenței candidat.
int st , dr, Smax = -2000000000 , S = -1, start;
for(int i = 1 ; i <= n ; ++ i)
{
if(S < 0)
S = 0, start = i;
S += A[i];
if(S > Smax)
Smax = S, st = start, dr = i;
}
cout << Smax << endl;
cout << st << " " << dr;
Soluția de mai sus poate fi utilizată pentru valori mai mari ale lui n, de exemplu 100000 sau 1000000. De asemenea, poate fi ușor modificată încât să se evite folosirea tabloului, determinând rezultatul direct din citire. Astfel, complexitatea spațiu a algoritmului devine \(O(1)\).
Probleme propuse
Ordonare lexicografică pentru numere
Introducere
Problema #divimax cere, printre altele, determinarea celui mai mare număr care poate fi obținut prin concatenarea unor numere cunoscute.
De exemplu, pentru 15 234 1024, rexultatul va fi 234151024. La prima vedere, trebuie să sortăm numerele în ordine lexicografică inversă. Într-adevăr, ordonând numerele lexicografic invers, obținem 234 15 1024, iar prin concatenare obținem rezultatul de mai sus.
Dacă însă numere sunt 441 24 4, ordinea lexicografică (inversă) este 441 4 24. Prin concatenare obținem 441424, dar luându-le în ordinea 4 441 24 obținem un număr mai mare, 444124. Problema apare și atunci când dorim să obținem cel mai mic număr care poate fi obținut prin concatenarea unor numere date – simpla ordonare lexicografică nu este suficientă.
Problema
Considerăm următoarea cerință: Se dau două numere naturale A și B. Să se stabilească ordinea celor două valori, atfel încât numărul obținut prin concatenare să fie mai mic. Pentru 1024 și 15, răspunsul este 1024 15, iar pentru 331 3, răspunsul este 331 3.
Algoritm
Procedăm astfel:
- considerăm numărul
x, obținut prin concatenarea luiAcuB; - considerăm numărul
y, obținut prin concatenarea luiBcuA; - dacă
x < y, atunci ordinea dorită esteA B; - în caz contrar, ordinea este
B A.
Secvențe C++
Următoarele funcții C++ verifică dacă pentru a obține prin concatenarea numerelor A și B un număr mai mic le păstrăm sau nu ordinea. Returnează true dacă ordinea este A B, respectiv false dacă ordinea este B A. Ele pot fi folosite pentru a sorta un tablou folosind funcția STL sort().
Prima variantă construiește cele două numere descrise mai sus și le compară. Valorile lui A și B trebuie să fie suficient de mici încât să le putem concatena fără overflow!
bool Compare(int A , int B){
int pA = 1, pB = 1, x = A, y = B;
do pA *= 10, x /= 10; while(x);
do pB *= 10, y /= 10; while(y);
return 1LL * A * pB + B < 1LL * B * pA + A;
}
Următoarea secvență folosește funcția std::to_string(), construiește două stringuri și le verifică ordinea (lexicografică). Din păcate este lentă!
bool Compare(int A , int B){
return to_string(A) + to_string(B) < to_string(B) + to_string(A);
}
Următoarea secvență construiește două tablouri cu cifrele celor două numere obținute prin concatenare și compară lexicografic tablourile.
bool Compare(int A , int B){
int v[30], u[30];
v[0] = u[0] = 0;
while(A)
v[++v[0]] = A % 10, A /= 10;
while(B)
u[++u[0]] = B % 10, B /= 10;
std::reverse(v + 1, v + v[0] + 1);
std::reverse(u + 1, u + u[0] + 1);
int lgv = v[0] , lgu = u[0];
for(int i = 1 ; i <= lgu; i ++)
v[++v[0]] = u[i];
for(int i = 1 ; i <= lgv; i ++)
u[++u[0]] = v[i];
//aici v[0] == u[0]
for(int i = 1 ; i <= v[0] ; i ++)
if(v[i] < u[i])
return true;
else
if(v[i] > u[i])
return false;
return false;
}
Observații:
- în secvența de mai sus, dimensiunile tablourilor
vșiuse memorează înV[0], resectivu[0]; reverseeste o funcție STL, disponibilă în headerulalgorithm, care oglindește tabloul- utilizăm faptul că, prin construcția lor, cele două tablouri au aceeași lungime. În caz contar, algoritmul este incomplet!
Liste liniare simplu înlănțuite alocate dinamic
O listă liniară simplu înlănțuită conține elemente (noduri) a căror valori constau din două părți: informația utilă și informația de legătură. Informația utilă reprezintă informația propriu-zisă memorată în elementul liste (numere, șiruri de caractere, etc.), iar informația de legătură precizează adresa următorului element al listei. În C/C++ putem folosi următorul tip de date pentru a memora elementele unei liste liniare simplu înlănțuite alocate dinamic:
struct nod{
int info;
nod * urm;
};
Câmpul info al tipului nod reprezintă informația utilă – în acest caz un număr întreg, iar câmpul urm este de tip pointer la nod și reprezintă informația de legătură.
În program vom folosi o variabilă de tip pointer (de exemplu prim) pentru a memora adresa primului element al listei și fiecare element al listei, începând cu primul, va memora în câmpul urm adresa elementului următor. Excepție face ultimul element al listei care va memora în câmpul urm valoarea NULL.
Observații:
- La început
primva avea valoareaNULL, cu semnificația că lista este vidă. Dacă la un moment dat lista redevine vidă (de exemplu se șterg toate elementele ei) variabilaprimva avea valoareaNULL. - Elementele listei sunt variabile dinamice, create cu ajutorul operatorului C++
newși gestionate prin intermediul pointerilor. Variabilaprimeste de tip pointer, dar este (în cele ce urmează) statică. - Fiind variabile dinamice, pentru elementele listei se alocă memorie în HEAP.
- Informațiile de legătură ocupă memorie. Spațiul de memorie ocupat de un pointer depinde de versiunea compilatorului folosit; în general este de
4octeți. Astfel, fiecare element al unei liste de tipul de mai sus va ocupa în memorie4+4=8octeți. - Accesul la un nod al listei se face prin parcurgerea nodurilor care îl preced.
O secvență C++ care conține declarațiile corespunzătoare poate fi:
struct nod{
int info;
nod * urm;
};
nod * prim = NULL;
În continuare vom prezenta secvențe/funcții C++ pentru principalele operații:
- crearea unui element nou,
- adăugarea unui element la sfârșitul listei,
- adăugarea unui element la începutul listei,
- parcurgerea listei,
- ștergere unui element din listă,
- inserarea unui element în listă.
Funcțiile care urmează vor avea ca parametru adresa primului element al listei și eventual alți parametri. În funcție de situație, parametrul care reprezintă adresa primului element ale listei va fi transmis prin valoare sau prin referință.
Crearea unui element nou
Numeroase operații cu liste solicită crearea unui nou element/nod. Pentru aceasta trebuie să ținem cont de următoarele:
- Nodurile sunt variabile dinamice. Crearea unui nou nod înseamnă crearea unei variabile dinamice. Acest lucru se face cu ajutorul operatorului C++
new, care are ca rezultat adresa variabilei nou create. Aceasta va fi memorată într-un pointer de tipnod *. Să-l numimp:nod * p = new nod; - Nodurile sunt variabile de tip structură, cu câmpurile
infoșiurm. Accesul la câmpuri se va face prin intermediul pointerilor, cu ajutorul operatorului->, astfel:p->infoșip->urm. Accesul la câmpuri se poate face și după dereferențierea pointer-ului:(* p).infoși(* p).urm. - Nodul nou creat va fi inclus într-o listă.
p->urmva memora adresa următorului element, sauNULLdacă nu există următorul element! - Rezumat:
peste pointer lanod; este de tipnod *;*peste variabila de tipnod– este nod din listăp->infoeste informația utilă din nodul listei, de tipintp->urmeste pointer. Memorează adresa elementului următor!
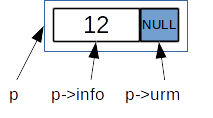
Secvența C++:
nod * p = new nod; p->info = ..... ; // cin >> p->info; p->urm = NULL;
Ne imaginăm lista în felul următor; săgețile simbolizează legăturile dintre nodurile listei. Vârful săgeții reprezintă elementul următor. Ultimul element nu are săgeată. Valoarea corespunzătoare din câmpul urm este NULL.
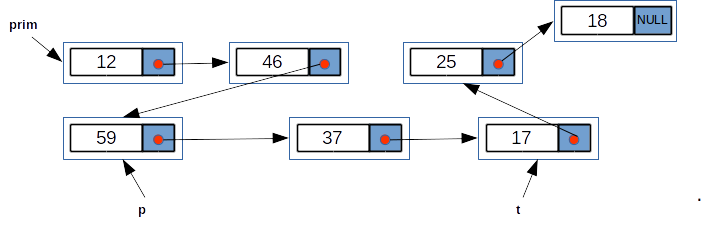
În exemplul de mai sus au loc următoarele relații:
- valoarea pointerului
primeste adresa elementului cu valoarea12; prim->info==12prim->urm->info==46prim->urmeste adresa elemenului cu valoarea46prim->urm->urm==pp->info==59p->urm->urm==tt->info==17t->urm->info==25t->urm->urm->info==18t->urm->urm->urm==NULLt->urm->urm->urm->infonu există. Rezultatul acestei expresii este impredictibil!
Adăugarea unui element la finalul listei
Un antet posibil pentru funcția care adaugă un element la finalul liste este:
void AdaugaFinal(nod * & prim , int val);
Parametru prim este transmis prin referință pentru a trata corespunzător situația când lista este vidă. În acesta caz, valoare de intrare a lui prim este NULL, iar valoarea de ieșire este adresa primului element al listei – element nou creat.
Practic, vom trata două situații:
- dacă
primesteNULL, creăm un nod nou, care va fi primul și totodată ultimul element al listei, memorăm în el valoarea dorită șiprimdevine adresa acestui nod; - în caz contrar, identificăm ultimul nod al listei și nodul nou creat devine succesor al ultimului element și totodată ultimul element al listei.
void AdaugaFinal(nod * & prim , int x)
{
// creăm nod nou
nod * q = new nod;
q -> info = x;
q -> urm = NULL;
// adăugă noul nod la listă
if(prim == NULL)
{ // lista este vidă
prim = q;
}
else
{ // lista nu este vidă
nod * t = prim;
while(t -> urm != NULL)
t = t -> urm;
t -> urm = q;
}
}
Adăugarea unui element la începutul listei
Un antet posibil pentru funcția care adaugă element la începutul liste este:
void AdaugaInceput(nod * & prim , int val);
Parametru prim este transmis prin referință deoarece la fiecare apel al funcției primul element se modifică; se creează un element nou care devine prim element al listei. Astfel, adresa primului element se modifică.
Procedăm astfel:
primmemorează adresa primului element- creăm un element nou:
nod * t = new nod; - memorăm în el informația utilă:
t->info = .... - îl plasăm în listă înaintea primului element:
t->urm = prim; - elementul nou creat este reținut ca prim element al listei:
prim = t;
Obs: Nu este necesară tratarea diferențiată a situațiilor când lista este vidă (prim==NULL), respectiv când lista conține elemente (prim memorează adresa primului element). În ambele situații atribuirea prim = t; are efectul dorit!
void AdaugaInceput(nod * & prim , int x)
{
// creăm nod nou
nod * t = new nod;
t -> info = x;
// legam nodul de lista
t -> urm = prim;
// valoarea lui prim se modifică, pentru a ieși din funcție cu valoarea corectă
prim = t;
}
Parcurgerea listei
Parcurgerea listei reprezintă vizitarea succesivă a elementelor pentru a realiza diverse operații cu valorile lor. Un antet posibil pentru o funcție care parcurge lista este:
void Parcurgere(nod * prim);
Parcurgerea se realizează secvențial, element cu element:
- folosim un pointer
nod * pîn care vom memora, pe rând, adresele elementelor din listă; - începem de la primul element al listei:
p = prim; - cât timp nu am trecut de ultimul element:
- prelucrăm elementul curent (
p->info) - trecem la următorul element:
p = p->urm;
- prelucrăm elementul curent (
void Parcurgere(nod * prim)
{
nod * p = prim;
while(p != NULL)
{
//prelucrăm nodul curent
// trecem la următorul nod
p = p->urm;
}
}
Ștergerea unui element
Ștergerea unui element al listei constă în două etape: ștergerea propriu-zisă a variabilei dinamice în care este stoca nodul de șters și refacerea legăturilor, astfel încât lista să fie consistentă. Tehnic, modul de ștergere diferă după cum nodul de șters este primul din listă sau nu.
Dacă ștergem primul element al listei vom proceda astfel:
- memorăm adresa primului nod într-un pointer auxiliar:
nod * t = prim; - nodul de după
primdevine primul nod al listei:prim = prim->urm; - ștergem variabila adresată de
t:delete t;
Dac ștergem un element oarecare al listei, trebuie să cunoaștem într-un pointer oarecare, să spunem p, adresa elementului din fața nodului de șters. Acest lucru este necesar pentru refacerea corectă a legăturilor dintre elementele listei:
- vom șterge elementul situat în listă după cel cu adresa memorată în
p, adică vom ștergep->urm; - memorăm adresa nodului de șters înt-un pointer auxiliar:
nod * t = p->urm; - corectăm adresa elementului de după
p:p->urm = t->urm; - ștergem variabila adresată de
t:delete t;
Inserarea unui nou element
Și inserarea se face diferit, în funcție de poziția noului nod în listă; inserarea unui nod nou înaintea primului nod al listei (adresa sa este memorată în pointer-ul prim) se face astfel:
- creăm un nod nou:
nod * t = new nod; - memorăm valoarea dorită în acest nod:
t->info = ...; - îl legăm de primul nod al listei:
t->urm = prim; - nodul nou creat devine primul din listă:
prim = t;
Dacă nodul nou creat nu va fi primul din listă, îl vom insera după un nod cu adresa cunoscută, memorată în pointer-ul p:
- creăm un nod nou:
nod * t = new nod; - memorăm valoarea dorită în acest nod:
t->info = ...; - în inserăm în listă:
- nodul nou creat va fi înaintea nodului de după
p:t->urm = p->urm; - nodul nou creat va fi plasat după nodul
p:p->urm = t;
- nodul nou creat va fi înaintea nodului de după
Secvențe cu extremități egale
Introducere
Se dă un șir cu n elemente. Să se determine cea mai lungă secvență de elemente din șir cu proprietatea că extremitățile secvenței au valori egale.
Fie V[] vectorul dat, cu n elemente. Vom propune trei soluții, cu diverse complexități.
Soluția 1
Prima soluție are complexitate \( O(n^2) \) și poate fi folosită pentru a rezolva problema #SecvEgale1 .
Considerăm că:
n ≤ 1000- elementele șirului au valori mai mici decât
231
Pentru fiecare element V[i] al vectorului vom determina cel mai mare indice j astfel încât V[i] și V[j] sunt egale. Dintre toate aceste perechi i j o reținem pe aceea pentru care lungimea secvenței, j - i + 1 este mai mare.
Soluția 2
Dacă valorile din șir sunt cuprinse între 1 și vmax, avem o soluție de complexitate \(O(n \cdot vmax)\). Pe site: #Lungime .
Considerăm că:
n ≤ 100000- elementele șirului au valori mai mici sau egale cu
vmax=100.
Pentru fiecare valoare c de la 1 la vmax vom determina cel mai din stânga indice i și cel mai din dreapta indice j cu proprietatea că V[i] și V[j] sunt egale cu c. Reținem pereceha i j pentru care j - i + 1 este maxim.
Soluția 3
O soluție de complexitate \(O(n)\) poate fi implementată dacă vmax este suficient de mic pentru a construi un vector cu vmax elemente: #distanta_maxima , #Lungime1 , #SecvEgale1_v2 .
Considerăm că:
n ≤ 100000- elementele șirului au valori mai mici sau egale cu
vmax=10000.
Considerăm un vector P[] în care P[k] reprezintă cel mai din stânga indice i cu proprietatea că V[i] = k. Inițial toate elementele lui P sunt nule.
Fie lgmax lungimera maximă a unei secvențe care respectă regula. Inițial, lgmax ← 0. Parcugem vectorul V:
- dacă
P[V[i]]este zero, suntem la prima apariție a valorii curenteV[i]în vector, deci cea mai din stânga. Atunci:P[V[i]] ← i. - dacă
P[V[i]]nu este zero, atunci valoareaV[i]a mai apărut în vector, la pozițiaP[V[i]]. Dacăi - P[V[i]] > lgmax, actualizămlgmaxși reținem secvențaP[V[i]] ica fiind secvența rezultat!
Matrice Fibonacci
Introducere
Șirul lui Fibonacci este definit astfel:
$$ F_n = \begin{cases}
1& \text{dacă } n = 1 \text{ sau } n = 2 ,\\
F_{n-1} + F_{n-2} & \text{dacă } n > 2.
\end{cases} $$
Pentru a determina al n-termen a șirului putem folosi diverse metode. Acest articol prezintă un algoritm de complexitate \(O(n)\) care determină al n-lea termen.
Prezentul articol prezintă un algoritm de complexitate logaritmică, bazat pe înmulțirea rapidă a matricelor.
Matrice Fibonacci
Considerăm următoarea matrice: \( Q = \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right) \). Dacă extindem șirul lui Fibonacii cu încă un element, \( F_0 = 0 \), observăm că: \( Q = \left( \begin{matrix} F_2& F_1\\ F_1& F_0\end{matrix} \right) \). Să calculăm \(Q^2\) și \(Q^3\):
$$ \begin{align} Q^2 & = Q \times Q \\
& = \left( \begin{matrix} F_2& F_1\\ F_1& F_0\end{matrix} \right) \times \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right)\\
& = \left( \begin{matrix}
F_2 \cdot 1 + F_1 \cdot 1& F_2 \cdot 1 + F_1 \cdot 0 \\
F_1 \cdot 1 + F_0 \cdot 1& F_1 \cdot 1 + F_0 \cdot 0
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_2 + F_1 & F_2 \\
F_1 + F_0 & F_1
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_3 & F_2 \\
F_2 & F_1
\end{matrix} \right) \\
\end{align}
$$
Similar:
$$ \begin{align} Q^3 & = Q^2 \times Q \\
& = \left( \begin{matrix} F_3 & F_2\\ F_2 & F_1\end{matrix} \right) \times \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right)\\
& = \left( \begin{matrix}
F_3 \cdot 1 + F_2 \cdot 1& F_3 \cdot 1 + F_2 \cdot 0 \\
F_2 \cdot 1 + F_1 \cdot 1& F_2 \cdot 1 + F_1 \cdot 0
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_3 + F_2 & F_3 \\
F_2 + F_1 & F_2
\end{matrix} \right) \\
& = \left( \begin{matrix}
F_4 & F_3 \\
F_3 & F_2
\end{matrix} \right) \\
\end{align}
$$
Observăm că \( Q^n = \left( \begin{matrix} F_{n+1}& F_n\\ F_n& F_{n-1}\end{matrix} \right) \), lucru ușor de demonstrat prin inducție matematică.
Concluzie: Dacă \( Q = \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right) \), atunci \( Q^n = \left( \begin{matrix} F_{n+1}& F_n\\ F_n& F_{n-1}\end{matrix} \right) \).
Algoritm
Pentru a determina \(F_n\), considerăm matricea \( Q = \left( \begin{matrix} 1& 1\\ 1& 0\end{matrix} \right) \), pe care o ridicăm la puterea n. Pentru a efectua repede calculele, folosim exponențierea rapidă.
Problema #Fibonacci2 cere determinarea celui de-al n-lea termen al șirului lui Fibonacii, modulo 666013. Succes!